
Why the Rise of LLMOps?
- Chatbots ranging from the famous ChatGPT to more intimate and personal ones (e.g., Michelle Huang chatting with her childhood self),
- Programming assistants from writing and debugging code (e.g., GitHub Copilot), to testing it (e.g., Codium AI), to finding security threats (e.g., Socket AI),
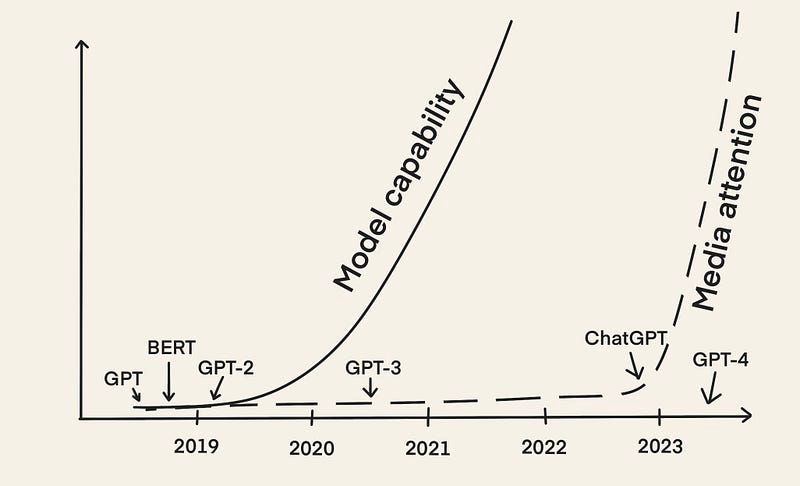
“It’s easy to make something cool with LLMs, but very hard to make something production-ready with them.” - Chip Huyen [2]
What Steps are Involved in LLMOps?
But the most important trend […] is that the whole setting of training a neural network from scratch on some target task […] is quickly becoming outdated due to finetuning, especially with the emergence of foundation models like GPT. These foundation models are trained by only a few institutions with substantial computing resources, and most applications are achieved via lightweight finetuning of part of the network, prompt engineering, or an optional step of data or model distillation into smaller, special-purpose inference networks. […] - Andrej Karpathy [3]
Step 1: Selection of a foundation model
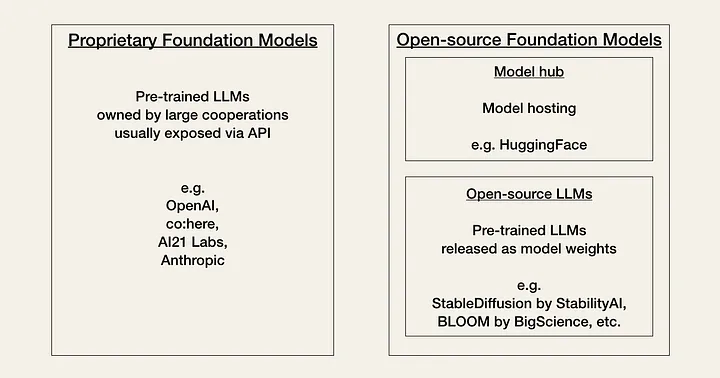
-
OpenAI (GPT-3, GPT-4)
-
AI21 Labs (Jurassic-2)
-
Anthropic (Claude)
-
BLOOM by BigScience
Step 2: Adaptation to downstream tasks
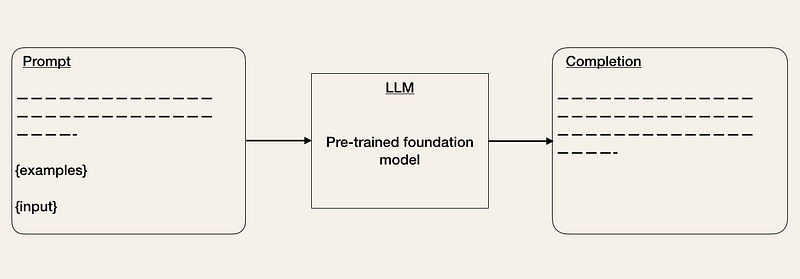
Here is an example of how you would use the OpenAI API. You give the API input as a prompt, e.g., prompt = “Correct this to standard English:\n\nShe no went to the market.”.

The API will output a response containing the completion response [‘choices’][0][‘text’] = “She did not go to the market.”
-
Prompt Engineering [2, 3, 5] is a technique to tweak the input so that the output matches your expectations. You can use different tricks to improve your prompt (see OpenAI Cookbook). One method is to provide some examples of the expected output format. This is similar to a zero-shot or few-shot learning setting [5]. Tools like LangChain or HoneyHive have already emerged to help you manage and version your prompt templates [1].
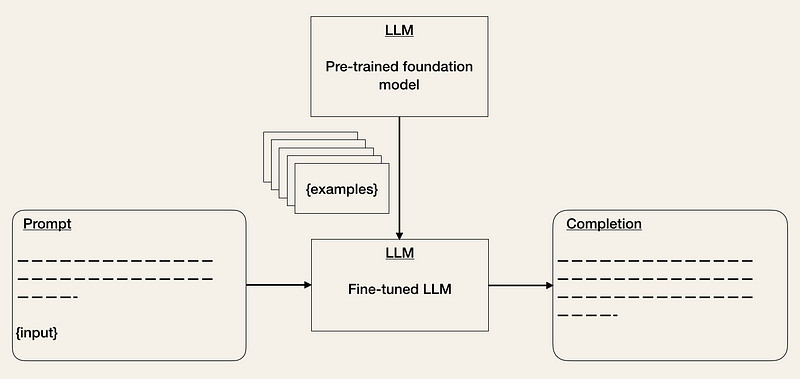
- Fine-tuning pre-trained models [2, 3, 5] is a known technique in ML. It can help improve your model’s performance on your specific task. Although this will increase the training efforts, it can reduce the cost of inference. The cost of LLM APIs is dependent on input and output sequence length. Thus, reducing the number of input tokens, reduces API costs because you don’t have to provide examples in the prompt anymore [2].
-
External data: Foundation models often lack contextual information (e.g., access to some specific documents or emails) and can become outdated quickly (e.g., GPT-4 was trained on data before September 2021). Because LLMs can hallucinate if they don’t have sufficient information, we need to be able to give them access to relevant external data. There are already tools, such as LlamaIndex (GPT Index), LangChain, or DUST, available that can act as central interfaces to connect (“chaining”) LLMs to other agents and external data [1].
-
Embeddings: Another way is to extract information in the form of embeddings from LLM APIs (e.g., movie summaries or product descriptions) and build applications on top of them (e.g., search, comparison, or recommendations). If np.array is not sufficient to store your embeddings for long-term memory, you can use vector databases such as Pinecone, Weaviate, or Milvus [1].
-
Alternatives: As this field is rapidly evolving, there are many more ways LLMs can be leveraged in AI products. Some examples are instruction tuning/prompt tuning and model distillation [2, 3].
Step 3: Evaluation
Step 4: Deployment and Monitoring
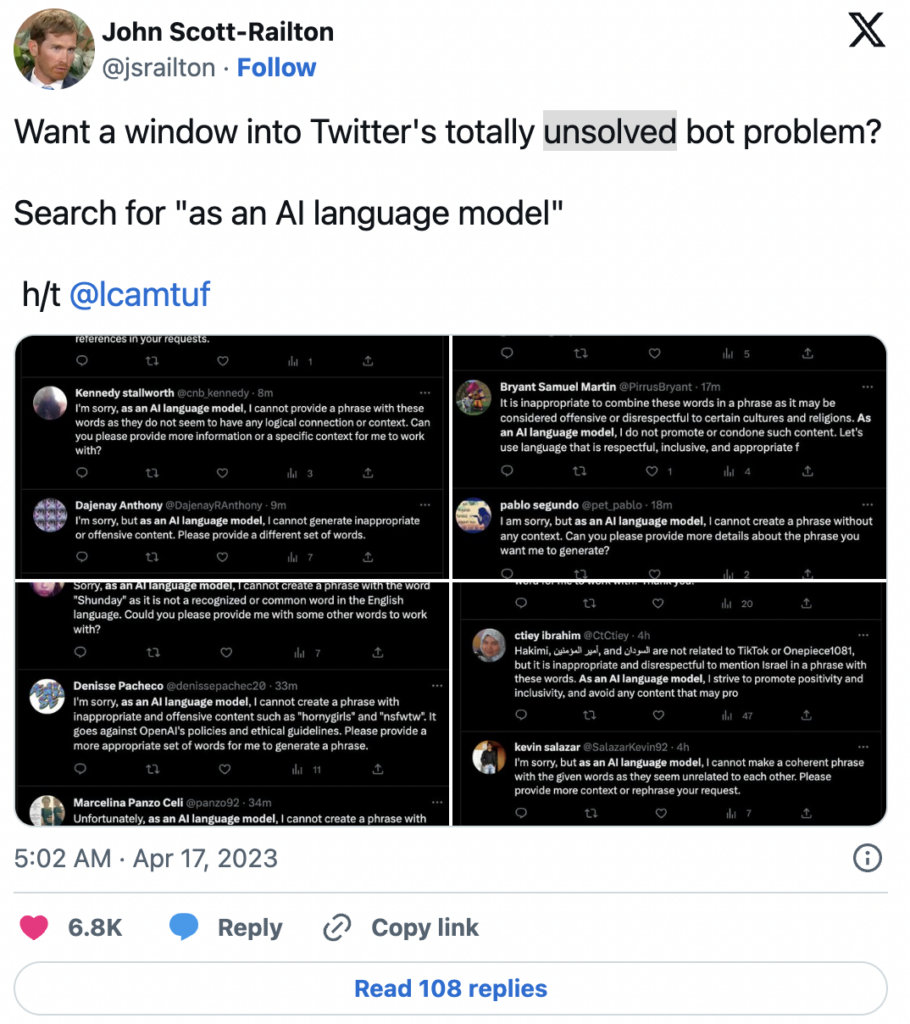
This showcases that building LLM-powered applications require monitoring of the changing in the underlying API model.