"We're now driving 50 or 100 times more experiments versus what we were doing before on the Mk1 IPU systems"

Phil Brown
Director of Applications
In this article, we take a look at how Weights & Biases has helped Graphcore to drive exponential growth in the number of experiments being run on their advanced IPU hardware.
About Graphcore
Graphcore is the inventor of the Intelligence Processing Unit (IPU), the world’s most sophisticated microprocessor, designed for the needs of current and next-generation artificial intelligence workloads.
Graphcore’s systems can dramatically accelerate AI workloads, as well as enable innovators to develop new, more sophisticated models. For many AI training and inference tasks, IPU systems significantly outperform the latest GPU-based systems, as they are based on a completely new kind of silicon architecture.
For large-scale deployments, Graphcore’s IPU-POD platform offers the ability to run very large models across large numbers of IPU processors in parallel or to share the compute resource across multiple users and tasks.
Scaling BERT on Graphcore’s Hardware
Most of our readers are likely familiar with BERT, the Bidirectional Encoder Representations from Transformers model released by Google in 2018. Essentially, BERT understands context a lot better than prior unidirectional models like Generative Pre-trained Transformers (GPTs). For example, BERT is a lot more likely to know the differences between a word like “run”, which has many different meanings in English. That’s because it looks in multiple directions (hence, “bidirectional”) to figure out what “run” means in a certain sentence. After all, a “run” of your latest model is a lot different than a “run” on the treadmill.
BERT was successful enough that Google now uses it on nearly every English language search. It’s been applied in myriad contexts and has been a building block for multiple SOTA approaches, not just in NLP but in domains as disparate as video, computer vision, and protein feature extraction.
BERT is also a fairly large model. The BERT-base variant has 110 million parameters whereas BERT-large has 340 million parameters. In fact, some of these large models can have over 100 billion parameters.
Now, as models like BERT grow in prevalence, there’s an increasing demand for hardware that can keep up with their attendant compute greediness. And that’s something Graphcore is helping to solve with their Intelligence Processing Units (or IPUs).
IPUs are AI processors made to handle large-scale models like BERT and the next wave of even bigger ones. Typically, they’re connected together in PODs, meaning that training these models can be completed in a reasonable timeframe of a few days or even a handful of hours.
Graphcore themselves have written eloquently about their processes here. Essentially, they employ multiple connected IPUs (hence IPU-POD) and use various data-parallel model training techniques to scale the pre-training processes to these multiple machines. We’ll let them explain:
“Data-parallel training involves breaking the training dataset up into multiple parts, which are each consumed by a model replica. At each optimization step, the gradients are mean-reduced across all replicas so that the weight update and model state are the same across all replicas.”
Graphcore engineers also use Gradient Accumulation to help maintain parallel scaling efficiency when training BERT with large batches.
The end result is that their BERT training times are incredibly fast: just over 12 hours on their own PopART system. You can see that performance below.
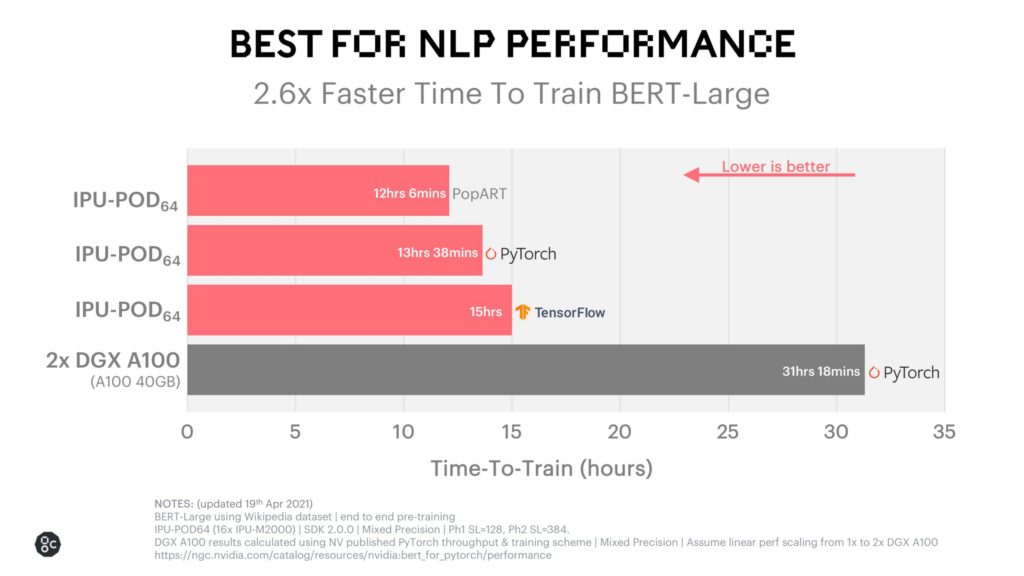
Graphcore’s customer base is full of smart, innovative companies that are running large and complex models. Building out this infrastructure is key for them as they support their growing user base. But combining all these IPUs and running experiments this large is, to put it lightly, a challenging task. That’s where Weights & Biases comes in.
Scaling IPU Experimentation With Weights & Biases
A bit like how Graphcore’s IPU-PODs enable AI engineers to train parameter-rich models like BERT faster, W&B helped the team at Graphcore to scale their experimentation.
Before integrating with Weights & Biases tools, Graphcore was doing what a lot of teams do: building internal tools and tracking their experiments manually in spreadsheets.
That approach brought with it a few tricky challenges. For one, they were having issues tracking experiments both across multiple IPU-POD systems and across multiple deployment locations. In other words, scaling their approach was becoming too complicated to track effectively, and that was an issue since large-scale experimentation is critical to enabling their target machine learning models. They also didn’t have a central place to analyze their work or an easy way to collaborate across their team and share findings.
To add to these challenges, training massive models on multiple machines is just a really complex task. Snags can occur with the model itself, with the datasets, or with bugs in their software, just to name a few potential difficulties. Diagnosing these points of failure required a central source of truth, one that could record all their work and one they could use to look back through time and compare previous and current experiments.
Their internal solution could handle some of the issues but the more complex Graphcore’s work got, the more they needed from their internal solution. W&B was an “obvious choice”.
“We’re now driving 50 or 100 times more experiments versus what we were doing before on the Mk1 IPU systems,” was how Phil Brown, Director of Applications at Graphcore, described it.
W&B allows them to scale up their experiments as they scale up the systems they’re building. It lets them more easily discover what went wrong faster so that it can be fixed sooner. It gives them a central source of truth that stretches back to the day they instrumented so they can compare successful runs from months back and get novel insights. It lets them understand if variable performance on these experiments is to be expected or if there’s an issue that needs debugging. And they love the visualizations too.
What’s Next for Graphcore
Graphcore is continuing to build not only bigger and more powerful IPUs and IPU-PODs but also building out a software ecosystem as well. Instrumenting W&B means they can focus on providing the systems and software their customers need to train state-of-the-art models now and into the future as models grow even larger.
Because make no mistake: models will be growing. It’s estimated that SOTA NLP models are growing ten times larger per year, in fact. Distributed compute will be absolutely necessary. And IPUs are a spectacular choice as models keep expanding in both size and complexity.
We’re thrilled we can be a small part of helping them. We recommend checking out the detailed case study on BERT in addition to the Graphcore website.