Autonomous vehicle perception depends on complementary sensor modalities: camera, lidar, and radar.
For example, lidar provides very accurate depth but could be sparse in the long-range. Cameras can provide dense semantic signals even in the long-range but do not capture an object’s depth.
By fusing these sensor modalities, we can leverage their complementary strengths to achieve more accurate 3D detection of agents (e.g. cars, pedestrians, cyclists) than solely relying on a single sensor modality. To accelerate autonomous driving research, Lyft shares data from our autonomous fleet to tackle perception and prediction problems.
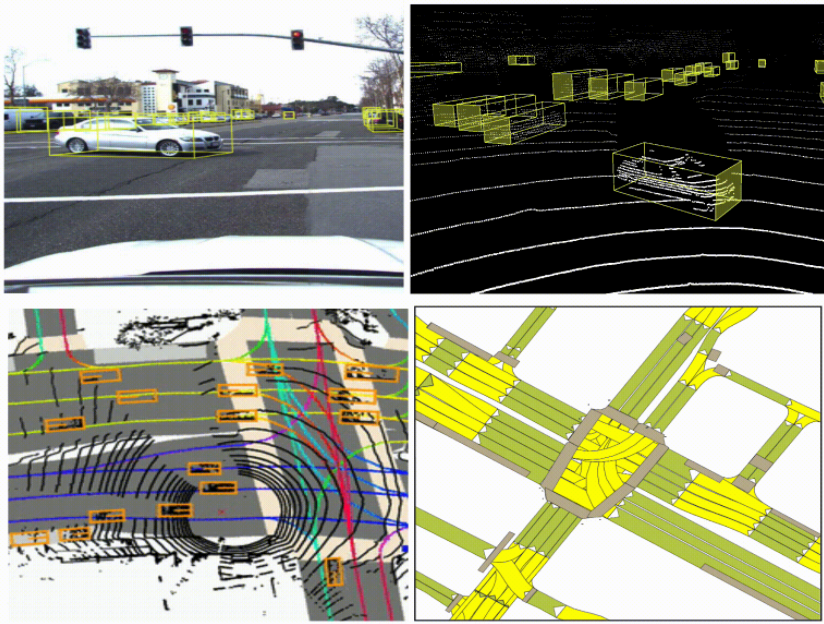
There are many strategies for fusing cameras and lidar. Interested readers can find a comprehensive review of various fusion strategies below in the resources [1-6]. Here, we only consider two strategies that both utilize deep neural networks.
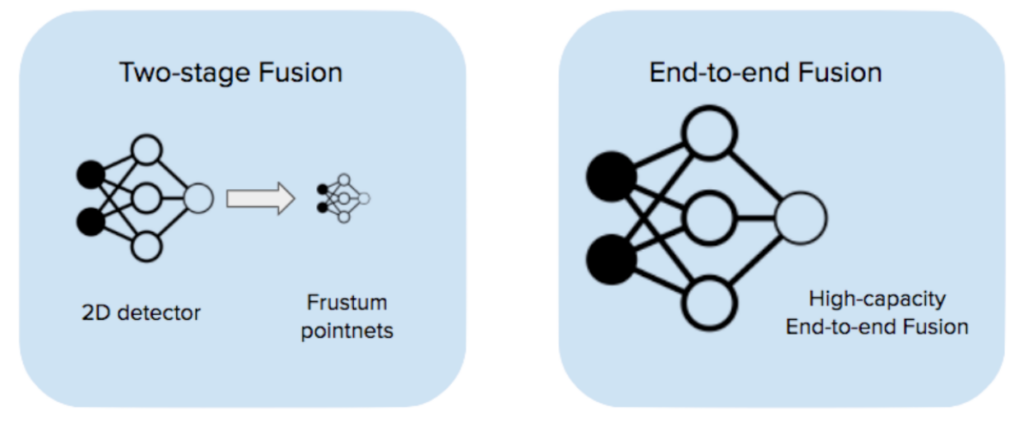
One strategy is through two-stage fusion like frustum pointnets [1]: the first stage is an image detection model that takes camera images and outputs 2d detections. The second stage takes the 2D detection proposals, creates frustums from them in 3D, and runs lidar-based detection within each frustum. We adopted this strategy in our early stack and achieved good results (check our blog post for more details).
However, two-stage fusion performances are limited by either the vision model or the lidar model. Both models are trained using single modality data and have no chance to learn to directly complement the two sensor modalities.
An alternative way of fusing camera and lidar is end-to-end fusion (EEF): using one single high-capacity model that takes all raw camera images (6 of them in our case) and lidar point cloud as input and trains end-to-end. The model runs separate feature extractors on each modality and performs detection on the fused feature map. In this report, we will discuss our take on end-to-end camera-lidar fusion and present experimental results conducted with Jadoo, our internal ML framework, and W&B.
End-to-End Fusion Performs Better Than Two-Stage Fusion
End-to-end trained EEF has several key advantages over two-stage fusion:
- The fusing of image and lidar features happens inside the model and is end-to-end learned during training. This means fewer heuristics and hyperparameters, and the network has the capacity to learn more complex mappings from input to output.
- EEF models can be trained to be fault-tolerant against missing data in either modality through data dropout during training. In comparison, it is harder for two-stage models to achieve the same level of fault-tolerance.
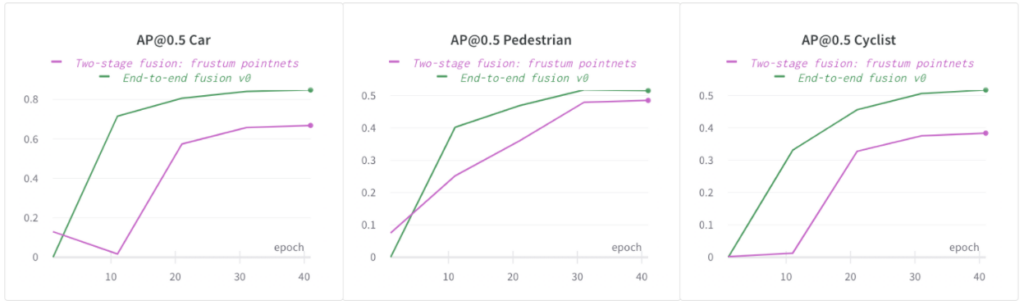
In the following figure, you can see that an end-to-end fusion model gives a much higher AP@0.5 than a two-stage fusion model for cars, pedestrians, and cyclists on our in-house dataset. We observed the same trend for the other classes (cars and cyclists) as well. For simplicity, we only compare AP for pedestrians in the rest sections of the report.
End-to-End Fusion Performs Better Than a Lidar-Only Model
We ran this experiment to understand if fusing image features will increase modeling accuracies. We used the following configurations:
- Lidar-only (no fusion): lidar-only model
- End-to-end fusion: end-to-end learned fusion with image & lidar
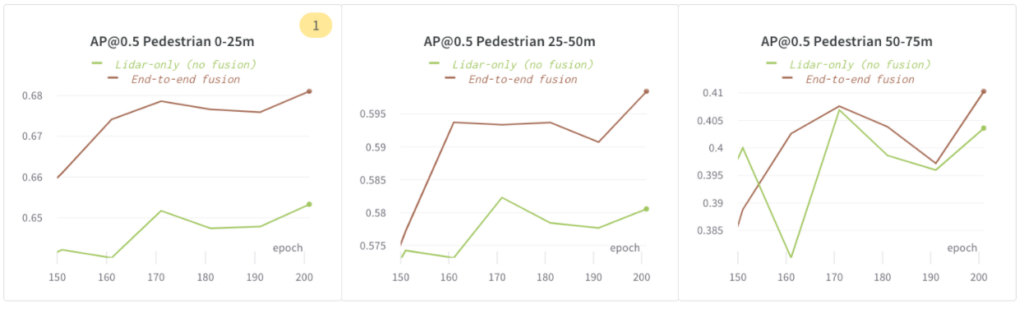
In the following figures, we demonstrated that `End-to-end fusion` performs better than `Lidar-only (no fusion)` on AP@0.5 for pedestrians within the 75m range.
Balancing Model Capacity & Overfitting
Higher Model Capacity = Boosted Accuracy
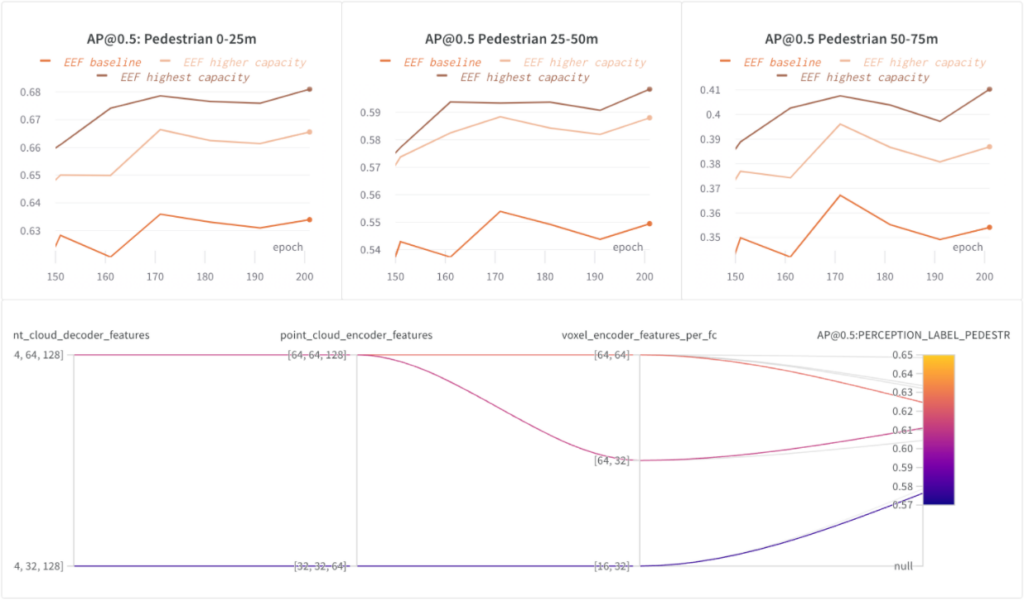
We increased the capacity of feature extractors within the EEF model and trained three configurations of increasing capacity: EEF baseline, EEF higher capacity, and EEF highest capacity.
In the following graphs, we demonstrated that higher model capacity helps. The highest model capacity (in the number of point cloud encoder/decoder features) boosted AP@0.5 for pedestrians within the 75m range by ~5%.
Tackling Overfitting with Data Augmentations
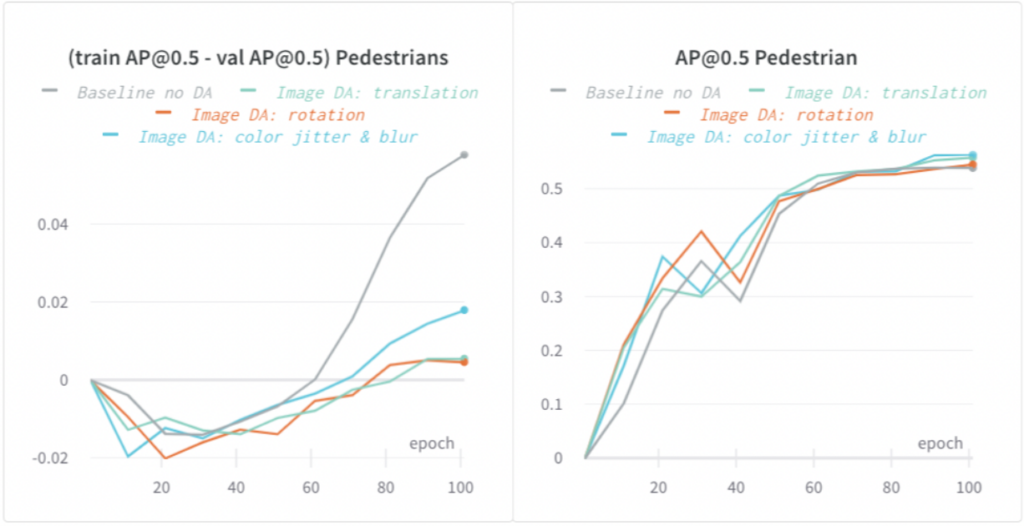
EEF model is a high-capacity model and is more prone to overfitting. One sign of overfitting is that the training metric improves while the validation metric does not improve (or an increased gap between train and validation metric).
We applied both image and lidar data augmentations (DA) and significantly reduced the overfitting. In the following graphs, we demonstrated different types of image-based DA reduced the gap between train and validation AP@0.5 for pedestrians by up-to 5% and improved model generalization.
Faster Training: Iteration Speed Matters
Faster Training from Image Dropout and Using Half-res Images
Training the high-capacity EEF model could be slow because:
- Compute is large considering contributions from the high-capacity.
- GPU memory footprint of the model is large. This means the model is more prone to running out of GPU memory when using a large batch size during training. Forced to use a smaller batch size means slower training.
- Data loading takes time considering the large input (6x full-resolution camera images + lidar spin, more details could be found in our Lyft Level 5 Open Dataset).
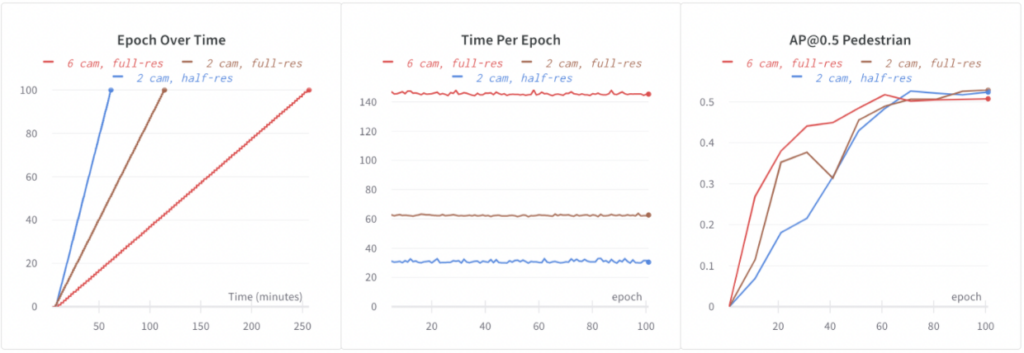
Baseline EEF trains on all 6 full-res images. It took 4.3 hours to train 100 epochs on 64 GPUs. In order to iterate faster on EEF, we need to speed up training. We experimented with the following configurations:
- 6 cam, full-res: Baseline EEF.
- 2 cam, full-res: Random image dropout was used during training: we randomly dropped out 4 out of 6 images during training. This reduced compute and data loading time and led to 2.3x faster training. In addition, the dropout helped regularization, and likely because of this, we observed better accuracies (shown below: +1.5% AP@0.5 for pedestrians).
- 2 cam, half-res: We further reduced image resolution by using half-res images. This further led to 2x faster training than using full-res images without much accuracy regression.
With the help from both image dropout and half-res images, we speeded up EEF training by 4.3x and also improved model accuracies.
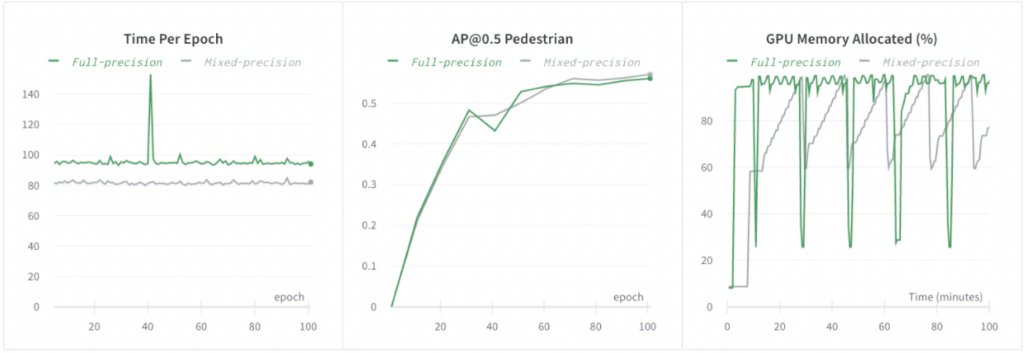
Mixed-precision Training
We used the automatic mixed-precision from PyTorch and further speeded up training by 1.2x, reduced GPU memory footprint without regressing model accuracies.
Impact
- We demonstrated that high-capacity end-to-end fusion performs better than two-stage fusion or lidar-only models for 3d detection.
- We demonstrated our workflow in training high-capacity models, reducing overfitting while increasing model capacity, and maintaining fast iteration speed.
Learn More about Lyft Level 5
Acknowledgments
This report is based on the work done by the authors and Anastasia Dubrovina, Dmytro Korduban, Eric Vincent, and Linda Wang.