NVIDIAのNeMoを使って自動音声認識モデルの学習、最適化、解析、可視化、デプロイを行う
自動音声認識(ASR)は、話し言葉を自動で文字に変換する技術、いわゆるスピーチ・トゥ・テキストを指します。本記事では、NVIDIAのNeMo(Neural Modules)ツールキットを使ってエンドツーエンドのASRシステムを学習させる方法と、実験や性能指標の追跡にWeights & Biasesを利用する方法を紹介します。
Created on August 25|Last edited on August 25
Comment
目次(クリックで展開)
はじめに
このレポートでは、次の点を検討します。自動音声認識(ASR)〜を使った例NVIDIA NeMoおよび〜の使い方も紹介しますWeights and Biasesさまざまな実験や性能指標を追跡・記録するため。
まず、NeMoとWeights & Biases(W&B)について簡単に説明し、一般的な自動音声認識(ASR)の概要を紹介します。環境構築に直接進みたい場合は、ここをクリックしてください自動音声認識(ASR)
〜を使った例
NVIDIA NeMo
および〜の使い方も紹介します
Weights & Biases
さまざまな実験や性能指標を追跡・記録するため。
まず、NeMoとWeights & Biases(W&B)について簡単に説明し、一般的な自動音声認識(ASR)の概要を紹介します。環境構築に直接進みたい場合は、ここをクリックしてください。
NVIDIA NeMoとは何ですか?
NVIDIA NeMoからの ウェブサイト以下は最近の翻訳履歴です。
SOURCE: just click here
TRANS: ここをクリックしてください
SOURCE: .
TRANS: 自動音声認識(ASR)
〜を使った例
NVIDIA NeMo
および〜の使い方も紹介します
Weights & Biases
さまざまな実験や性能指標を追跡・記録するため。
まず、NeMoとWeights & Biases(W&B)について簡単に説明し、一般的な自動音声認識(ASR)の概要を紹介します。環境構築に直接進みたい場合は、ここをクリックしてください。
SOURCE: Lastly, much of the code used in this blog post is available at
TRANS: 最後に、本記事で使用したコードの多くは以下で入手できます。
SOURCE: ASR_with_NeMo.ipynb
TRANS: ASR_with_NeMo.ipynb
SOURCE: .
TRANS: 最後に、本記事で使用したコードの多くは以下で入手できます。
ASR_with_NeMo.ipynb
SOURCE: What is Nvidia NeMo?
TRANS: NVIDIA NeMoとは何ですか?
SOURCE: From the Nvidia NeMo
TRANS: NVIDIA NeMoからの
SOURCE: website
TRANS: ウェブサイト
批評ノート(この翻訳を改善するために使用してください。スタイル/用語/文法の問題に対処してください。各セクションごとに翻訳しています。該当しない批評点は無視してください):
主な問題点(要約) — 全体的なパターン
- 用語の一貫性: "Nvidia"/"NVIDIA"、"NeMo"/"NeMo toolkit"、"Weights and Biases"/"Weights & Biases"/"W&B"、"NGC"/"NGC here"などの混在。略語(ASR、WER、TTS、NLP)を導入する際の表記が一貫していない(英語表記とカタカナや日本語の併記が混在)。
- 自然さ/流暢さ: UI表現の直訳や不自然な表現がある(「click here」の過度に直訳された表現や文の断片、未翻訳のプレースホルダー)。英語語順のまま残っているため日本語として不自然な箇所がある。
- 文法/助詞: 助詞の欠落や不適切な助詞選択が見られる(例: "を使用する" がぶら下がっている、主語の省略、孤立した ":" や ".")。文の断片が残っている。
- 語順/構文: 英語の語順が残っている箇所があり読みづらい(例: "モデル、 …、回数。" や "という名前のフォルダができているはずです" の不完全な箇所)。
- スペースと句読点: 括弧や英語用語の前後に不必要なスペースがある。句読点の変換が不統一。コードやファイル名の表記に空白や誤った句読点が混入している(例: "ASR_with_NeMo.ipynb" 、"Dockerコンテナを実行する using command .")。
- ブランド名と大文字小文字: "Nvidia" と "NVIDIA" の不統一、"NGC" の大文字小文字の不一致。"Jasper/KxR" の表記揺れ、"Weights & Biases" が "Weights and Biases" と混在。
- コード/API/ファイル名: コード片やコマンドが省略されているか空白になっている。マニフェスト例やファイル形式のトークンが欠落している(例: ""、""、 , )。バッククォートやコードフォントが消えている。コマンドやパスは明示的に示す必要がある。
具体的な改善指針
- 用語集を確立する: ブランド表記を統一する(NVIDIA、NeMo、Weights & Biases(および略称W&B))と補足説明を用意する。略語は初出で展開する(例: 自動音声認識(ASR))。
- 技術用語の表記を統一する: 英語名はローマ字表記のままにし、必要に応じて日本語説明を付ける(例: NeMoツールキット(NeMo)、QuartzNet15x5、ASR_with_NeMo.ipynb)。
- 断片化した文を修正する: 孤立した句読点やプレースホルダーを補完し、各文を完結させる。不要なピリオドやコロンを削除。
- 助詞と結びつきを改善する: 欠落している助詞や主語を補い、自然な日本語表現を用いる(例: "を使用します" → "を使用します。"、"〜を使った例" → "〜を使った例です。")。
- コードとコマンドの書式: コマンド、ファイル名、コードは適切にインラインや等幅で示す。角括弧のプレースホルダーは明示する(例: <path>)。
- スペースと句読点の一貫性: 日本語と英語の間に不要なスペースを入れない。日本語文には全角句読点を使用し、コード内は英語句読点にする。
- UI表現の自然化: "click here" は「こちらをクリック」や「ここをクリックしてください」と自然な日本語にする。
- 全体に渡り上記ルールを適用し、欠落しているコード片やプレースホルダーを復元して可読性をテストする。
これらの規則を文書全体に適用してください。
あなたはWeights & Biasesのプロの技術翻訳者です。すべてのユーザー文を日本語に翻訳してください。出力は日本語の原文文字のみとしてください。
ローマ字、発音表記、ASCII、コードポイント、文字化けなどは一切出力しないでください。
特定語の正確な形を次の通り使用してください: Weights & Biases
文を自然で流暢な日本語に翻訳してください。語順を入れ替えたり、助詞を加えたり、文法を整えて構いません。原文に厳密である必要はありませんが、日本語として自然になるようにしてください。
説明、注釈、音訳などを追加しないでください。
NVIDIA NeMoは、自動音声認識(ASR)、自然言語処理(NLP)、および音声合成(TTS)に取り組む研究者向けに開発された会話型AIツールキットです。NeMoの主な目的は、産業界や学術界の研究者が既存の成果(コードや事前学習済みモデル)を再利用できるようにし、新しい会話型AIモデルの作成をより容易にすることです。
Weights & Biasesとは何ですか?
Weights & Biasesは機械学習チームがより良いモデルをより早く構築するのを支援します。ほんの数行のコードで、実践者はモデルのアーキテクチャ、ハイパーパラメータ、gitコミット、モデルの重み、GPU使用状況、データセット、予測といった情報を瞬時にデバッグ、比較、再現でき、チームメンバーと共同作業しながら管理できます。
Weights & Biasesは、世界の最先端企業や研究機関の20万人以上の機械学習実務者に信頼されています。無料で始められ、わずか数行のコードで5分程度で統合できます。 ここをクリックして始めてください 無料で。
導入:自動音声認識(ASR)とは何ですか?
自動音声認識(ASR)、または自動音声認識は、音声を自動で文字起こしする問題を指します。一般に「speech-to-text」として知られています。
我々の目標は通常、単語誤り率(WER)を最小化するモデルを得ることです。単語誤り率(WER)音声入力を文字に変換する際の評価指標です。つまり、音声を含むファイル(例:WAVファイル)を与えられたとき、できるだけ誤りを少なく対応するテキストにどのように変換するか、という問題です。
のようなアプローチでは従来の音声認識生成的アプローチを取り、音声がどのように生成されるかというパイプライン全体をモデル化して音声サンプルを評価します。ここでは、次のように始めます。言語モデル生成される単語の最も尤もらしい並び(例えば n-gram モデル)を包含し、そして取り入れる発音モデルその語順にある各単語(例えば発音表)のそれぞれについて、およびさらに音響モデルそれらの発音を音声波形に変換する(たとえばガウス混合モデルなど)。
次に、音声入力を受け取ったときには、生成的なモデルパイプラインに従って与えられた音声から最も尤もらしいテキストの並びを見つけることが目的になります。つまり、従来の音声認識では全体として、次のような要素をモデル化しようとします。 Pr(audio|transcript)*Pr(transcript)、そして可能な転写の中でこの値の最大値を取ります。
時が経つにつれて、ニューラルネットワークは進化し、従来の音声認識モデルの各コンポーネントが、より高い性能と汎化能力を持つニューラルモデルに置き換えられるようになりました。問題は、これらの各ニューラルモデルがそれぞれ異なるタスクごとに個別に学習させる必要があることです。そして、パイプライン内のどのモデルにおいても誤りが生じると、全体の予測が大きく狂ってしまう可能性があります。
このようにして、私たちは〜の魅力を理解できます。エンドツーエンドのASRアーキテクチャ: 音声入力を受け取って直接テキストを出力する識別モデルで、アーキテクチャのすべての構成要素が同じ目的に向かって一緒に学習されるものです。モデルのエンコーダは音声特徴を抽出する音響モデルに相当し、それをそのままテキストを出力するデコーダへ接続できます。必要であれば、予測を改善するために言語モデルを統合することも可能です。
このようにして、エンドツーエンドのASRモデル全体を一度に学習させることができ、はるかに扱いやすいパイプラインになります。
本日のタスクでは、以下を使用します。NVIDIAのNeMoツールキットエンドツーエンドのASRアーキテクチャを学習させるためのツールキットとして使用し、さらにWeights and Biasesパフォーマンス指標の記録用。
それでは、始めましょう!
環境のセットアップ
これで自動音声認識や本記事で使用するツールの概要がつかめたので、最初のステップはコードを実行できるように環境を整えることです。
まずはインスタンスを起動します。AWSその後、マシン上で NeMo を動作させるために必要な依存関係をインストールします。ここでは、次のものを使用します。 NVIDIA NGC およびここにある Jupyter ノートブック。
- AWSインスタンスを起動するRECENT TRANSLATION HISTORY: SOURCE: AWS TRANS: AWS SOURCE: and then install the required dependencies for NeMo to run on the machine. We'll be using TRANS: その後、マシン上で NeMo を動作させるために必要な依存関係をインストールします。ここでは、次のものを使用します。 SOURCE: Nvidia NGC TRANS: NVIDIA NGC SOURCE: and Jupyter Notebooks here. TRANS: およびここにある Jupyter ノートブック。 SOURCE: Here are the steps to set up the environment for TRANS: 環境を整える手順は次のとおりです: SOURCE: Nvidia NeMo TRANS: NVIDIA NeMo SOURCE: : TRANS: : SOURCE: Launch AWS Instance TRANS: AWSインスタンスを起動するp2.xlargeおよび使用する NVIDIA GPU最適化AMI。
- AWSインスタンスにSSHで接続するおよびポート 8888 をフォワードします。
- NGCからNVIDIA NeMoのDockerコンテナを取得する NVIDIAGPU最適化AMI 。 AWSインスタンスにSSHで接続する およびポート8888をフォワードします。 Jupyterノートブックをダウンロードしてください ここ(NGC) 。これをダウンロードします。 NGCからNVIDIA NeMoのDockerコンテナを取得する docker pull nvcr.io/nvidia/nemo:1.6.1。
- Dockerコンテナを実行する コマンドを使用して docker run --runtime=nvidia -it --rm --shm-size=16g -p 8888:8888 --ulimit memlock=-1 --ulimit stack=67108864 -v $(pwd):/notebooks nvcr.io/nvidia/nemo:1.6.1。
- Dockerコンテナ内にいる場合、Jupyterノートブックを起動する NVIDIA NeMo の Docker コンテナを NGC から取得する NVIDIA GPU 最適化 AMI AWS インスタンスに SSH で接続し、ポート 8888 をフォワードしてください。 Jupyter ノートブックをここ(NGC)からダウンロードしてください。これをダウンロードします。 NGC から NVIDIA NeMo の Docker コンテナを取得する。 Docker コンテナを実行するには、次のコマンドを使用します。 Docker コンテナを実行する コマンドを使用して NVIDIA GPU 最適化 AMI。 AWS インスタンスに SSH で接続し、ポート 8888 をフォワードしてください。 Jupyter ノートブックをダウンロードしてください(ここ)。これをダウンロードします。 NGC から NVIDIA NeMo の Docker コンテナを取得する。 Docker コンテナを実行するには、次のコマンドを使用します。 Docker コンテナ内にいる場合、 Jupyter ノートブックを起動する jupyter notebook --port 8888。
- へ移動してください localhost:8888 へ Jupyter ノートブックにアクセスする。
- ダウンロードしたものをアップロードする files.zip ステップ3でダウンロードし、解凍してASRのW&Bノートブックにアクセスしてください。
以上です。6つの簡単な手順で、NeMo のコードを実行できる状態で AWS インスタンスに入ることができます。
導入:エンドツーエンド自動音声認識
導入のASRの節から、エンドツーエンドのASRモデルを構築できることがはるかに有用であることがわかります。
エンドツーエンドモデルでは、入力音声から直接学習して Pr(transcript|audio) 元の音声から文字起こしを予測するためです。音声データは時間に沿った連続情報であり、対応する文字列の並びと対応するため、RNN は自然な選択肢となります。
しかしここで差し迫った問題があります。入力系列(音声のタイムステップ数)は望む出力(文字起こしの長さ)と同じではないため、音声データの各タイムステップをどのようにして正しい出力文字に対応させればよいのでしょうか。
アテンション付きシーケンス・ツー・シーケンス
一般的な解決策として、アテンション機構を備えたシーケンス・ツー・シーケンスモデルを使用する方法があります。
典型的なASR向けのシーケンス・ツー・シーケンスモデルは、音声の各タイムステップを逐次取り込む双方向RNNエンコーダと、その出力を受け取るアテンションベースのデコーダで構成されます。デコーダの各予測は、エンコードされた入力全体の一部に注意を向けることと、これまでに出力されたトークンの両方に基づいて行われます。
デコーダの出力は、ワードピース、音素、文字など何でもあり得ます。予測が入力のタイムステップに直接結び付いていないため、終了トークンが出るか、あらかじめ定めた最大出力長に達するまで、トークンを一つずつ生成し続ければよいのです。こうすることで音声と出力の時間的なアライメントを扱う必要がなくなり、予測された文字起こしはデコーダが出力したトークン列そのものになります。
データを見てみましょう
AN4は、住所や名前、電話番号などを一文字ずつ綴って発話した録音と、それに対応する文字起こしから成るデータセットです。AN4は比較的小規模で、訓練用が948件、テスト用が130件しかないため学習が速く、短いチュートリアルに最適です。
よし、それではデータセットをダウンロードして準備しましょう。発話データは次の場所で入手できます。 .sph 形式のファイルなので、変換する必要があります .wav 処理のために、次を実行してください:
# Download the datasetprint("******")if not os.path.exists(data_dir + '/an4_sphere.tar.gz'):an4_url = 'http://www.speech.cs.cmu.edu/databases/an4/an4_sphere.tar.gz'an4_path = wget.download(an4_url, data_dir)print(f"Dataset downloaded at: {an4_path}")else:print(f"Tarfile already exists at {data_dir + '/an4_sphere.tar.gz'}")an4_path = data_dir + '/an4_sphere.tar.gz'# convert .sph to .wavif not os.path.exists(data_dir + '/an4/'):# Untar and convert .sph to .wav (using sox)tar = tarfile.open(an4_path)tar.extractall(path=data_dir)sph_list = glob.glob(data_dir + '/an4/**/*.sph', recursive=True)for sph_path in tqdm(sph_list):wav_path = sph_path[:-4] + '.wav'cmd = ["sox", sph_path, wav_path]subprocess.run(cmd)
この時点で、という名前のフォルダができているはずです。 an4 を含む etc/an4_train.transcription、 etc/an4_test.transcription、オーディオファイルは形式で wav/an4_clstk 、 wav/an4test_clstkおよび、今回は使用しないその他のファイルがいくつか含まれています。
まずはサンプル音声を用意して波形をプロットしてみましょう。例として、ファイル cen2-mgah-b.wav は、男性がアルファベットの「G L E N N」を一つずつ発音した、長さ2.6秒の音声録音です。これを確認するために、ファイルを再生して波形をプロットしてみましょう:
import librosaimport IPython.display as ipd# Load and listen to the audio fileexample_file = data_dir + '/an4/wav/an4_clstk/mgah/cen2-mgah-b.wav'audio, sample_rate = librosa.load(example_file)ipd.Audio(example_file, rate=sample_rate)_ = librosa.display.waveplot(audio)

それぞれの発音された文字が異なる「形」をしていることがなんとなく分かり、最後の二つの塊が比較的似ているのは、どちらも文字「N」であるため予想通りである点が興味深いです。
スペクトログラムとメルスペクトログラム
しかし、音声情報は時間に沿った周波数の文脈でより有用であるため、スペクトル解析を行うことでより良い表現が得られます。 フーリエ変換 音声信号に対してより有用な表現を得るために: スペクトログラムこれは、ファイルの再生時間にわたる信号の各周波数(すなわち音の高さ)におけるエネルギー量(振幅、つまり「音の大きさ」)を表したものです。
サンプルのスペクトログラムがどのようになっているか見てみましょう。

再び、各文字が発音されている様子と、最後の二つの塊が「N」に対応していてかなり似た見た目をしていることが確認できます。しかし、これらの形や色はどのように解釈すればよいのでしょうか?
前の波形プロットと同様に、横軸は時間の経過(全長2.6秒)を表しています。しかし今回は縦軸が異なる周波数(対数スケール)を示しており、プロット上の色は特定の時刻における各周波数成分の強さを表しています。
まだ終わりではありません。もうひとつ有用な調整が可能です:使用するのはメルスペクトログラム通常のスペクトログラムの代わりに用います。これは単に周波数スケールを線形(または対数)からメル尺度に変更しただけのものです。メル尺度「聴取者が互いに等しい距離にあると判断する音高の知覚的尺度」です。
言い換えると、周波数を人間の知覚に合わせて変換したものです。例えば2000Hzから3000Hzへの+1000Hzの変化は、9000Hzから10000Hzへの同じ+1000Hzの変化よりも私たちには大きく聞こえます。メル尺度はこの違いを正規化し、等しい距離が人間の耳にとって等しい差に聞こえるようにします。
# Plot the mel spectrogram of our samplemel_spec = librosa.feature.melspectrogram(audio, sr=sample_rate)mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)librosa.display.specshow(mel_spec_db, x_axis='time', y_axis='mel')plt.colorbar()plt.title('Mel Spectrogram');

畳み込み型自動音声認識モデル
これから構築するモデルと、そのパラメータの指定方法を見ていきましょう。
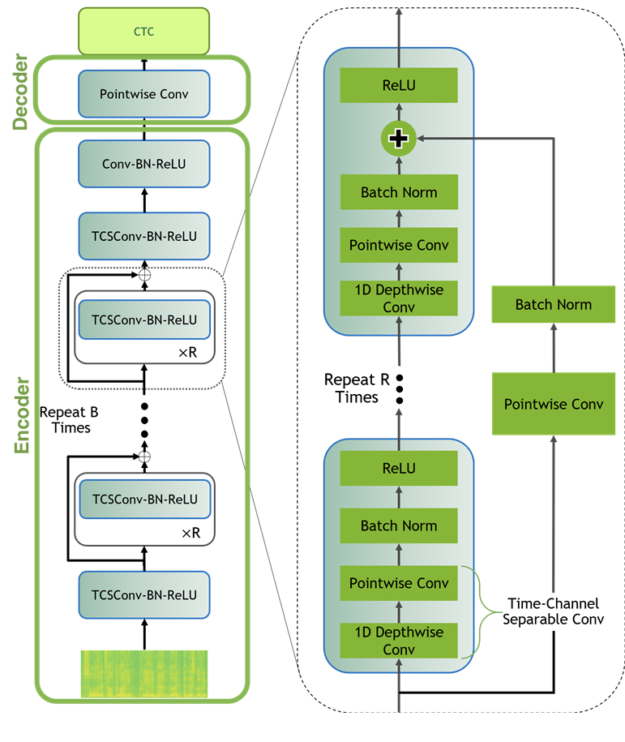
Jasperモデル
小さなモデルを訓練します Jasper(Just Another SPeech Recognizer)モデル ランダムに初期化��るなど、ゼロから訓練します。要するに、Jasperアーキテクチャは1次元畳み込みを利用した繰り返しブロック構造で構成されています。Jasper_KxRモデル、 R サブブロック(1次元畳み込み、バッチ正規化、ReLU、およびドロップアウトで構成)をまとめて1つのブロックにし、そのブロックを繰り返します K 回数。
最初にもう1つブロックがあり、最後にもいくつかブロックが追加されていて、それらは不変です K 、 R、そして私たちはCTC損失を使用します。
QuartzNetモデル
QuartzNetはJasperの改良版で、主な違いは時間とチャネルを分離した1次元畳み込み(time-channel separable 1D convolution)を使用している点です。これにより、精度をほぼ保ちながらパラメータ数を大幅に削減できます。
Jasper/QuartzNet モデルは次のような構成になっています(図は QuartzNet モデル)。
NeMo を使った自動音声認識
ASRが何か、音声データがどのようなものかが分かったので、NeMoを使って実際にASRを始めてみましょう。
私たちは次を使用します:Neural Modules(NeMo)ツールキット この部分を進めるには、まだの場合は NeMo とその依存関係をダウンロードしてインストールしてください。インストール方法は、以下の指示に従ってください。 GitHubページ、または ドキュメンテーション。
NeMoを使うと、データ層や中間層、各種の損失関数などモデルの構成要素(モジュール)を、個々の部品やモジュール間の接続実装の細部をあまり気にせずに簡単に組み合わせられます。NeMoには、学習に必要なのはデータとハイパーパラメータだけという完全なモデルも用意されています。
# NeMo's "core" packageimport nemo# NeMo's ASR collection - this collections contains complete ASR models and# building blocks (modules) for ASRimport nemo.collections.asr as nemo_asr# This line will download pre-trained QuartzNet15x5 model from NVIDIA's NGC cloud and instantiate it for youquartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="QuartzNet15x5Base-En")#
既製モデルの使用
NeMoのASRコレクションには、学習や評価に使える多くの構成要素や、すぐに使える完全なモデルが揃っています。さらに、いくつかのモデルは事前学習済みの重みも提供されています。それでは、完全なモデルをインスタンス化してみましょう。QuartzNet15x5モデル。
次に、文字起こししたいファイルへのパスをリストに追加して、それをモデルに渡します。なお、比較的短い(25秒未満)ファイルであれば動作します。
files = ['./an4/wav/an4_clstk/mgah/cen2-mgah-b.wav']for fname, transcription in zip(files, quartznet.transcribe(paths2audio_files=files)):print(f"Audio in {fname} was recognized as: {transcription}")
簡単でしたね!しかし、多くの場面ではモデルを自分のデータで微調整したり、場合によっては最初から学習させたりする必要があります。たとえば、この既製モデルは明らかにスペイン語には対応しておらず、電話音声では性能が大きく低下する可能性が高いです。したがって、独自に収集したデータがあるなら、ぜひそれを使って微調整や学習を試みてください。
最初から学習する
最初から学習するには、学習データを適切な形式で準備し、モデルのアーキテクチャを指定する必要があります。
ゼロからデータマニフェストを作成する
もし最初からモデルを学習させる場合は、データを適切な形式で準備する必要があります。そこで、学習用および評価用のデータに対するマニフェストを作成し、音声ファイルのメタデータを記述します。NeMoのデータセットは、各行が1つの音声サンプルに対応する標準化されたマニフェスト形式を取ります。したがって、マニフェストの行数はそのマニフェストで表されるサンプル数と一致します。各行には音声ファイルへのパス、対応する文字起こし(または文字起こしファイルへのパス)、および音声サンプルの長さ(秒数)を含める必要があります。
以下は、NeMo互換のマニフェストの1行がどのような形式になるかの例です。
{"audio_filepath": "path/to/audio.wav", "duration": 3.45, "text": "this is a nemo tutorial"}
学習用および評価用のマニフェストは、次のように作成できます。 an4/etc/an4_train.transcription 、 an4/etc/an4_test.transcription(各行には文字起こしとそれに対応する音声ファイルのIDが含まれています)
...<s> P I T T S B U R G H </s> (cen5-fash-b)<s> TWO SIX EIGHT FOUR FOUR ONE EIGHT </s> (cen7-fash-b)...
# Function to build a manifestdef build_manifest(transcripts_path, manifest_path, wav_path):audio_paths=[]; durations=[]; texts=[]with open(transcripts_path, 'r') as fin:with open(manifest_path, 'w') as fout:for line in fin:# Lines look like this:# <s> transcript </s> (fileID)transcript = line[: line.find('(')-1].lower()transcript = transcript.replace('<s>', '').replace('</s>', '')transcript = transcript.strip()file_id = line[line.find('(')+1 : -2] # e.g. "cen4-fash-b"audio_path = os.path.join(data_dir, wav_path,file_id[file_id.find('-')+1 : file_id.rfind('-')],file_id + '.wav')duration = librosa.core.get_duration(filename=audio_path)audio_paths.append(audio_path)durations.append(duration)texts.append(transcript)# Write the metadata to the manifestmetadata = {"audio_filepath": audio_path,"duration": duration,"text": transcript}json.dump(metadata, fout)fout.write('\n')return audio_paths, durations, texts# Building Manifeststrain_transcripts = data_dir + '/an4/etc/an4_train.transcription'train_manifest = data_dir + '/an4/train_manifest.json'train_audio_paths, train_durations, train_texts = build_manifest(train_transcripts, train_manifest, 'an4/wav/an4_clstk')test_transcripts = data_dir + '/an4/etc/an4_test.transcription'test_manifest = data_dir + '/an4/test_manifest.json'test_audio_paths, test_durations, test_texts = build_manifest(test_transcripts, test_manifest, 'an4/wav/an4test_clstk')
それでは、学習用およびテスト用のマニフェストが準備できたので、どのような内容になっているか見てみましょう。
最初の5行 train_manifest 次のようになります:(このコマンドで簡単に確認できます) !head {train_manifest} -n5)
{"audio_filepath": "./an4/wav/an4_clstk/fash/an251-fash-b.wav", "duration": 1.0, "text": "yes"}{"audio_filepath": "./an4/wav/an4_clstk/fash/an253-fash-b.wav", "duration": 0.7, "text": "go"}{"audio_filepath": "./an4/wav/an4_clstk/fash/an254-fash-b.wav", "duration": 0.9, "text": "yes"}{"audio_filepath": "./an4/wav/an4_clstk/fash/an255-fash-b.wav", "duration": 2.6, "text": "u m n y h six"}{"audio_filepath": "./an4/wav/an4_clstk/fash/cen1-fash-b.wav", "duration": 3.5, "text": "h i n i c h"}
Weights and Biasesへのデータのログ記録テーブル
学習用と評価用のマニフェストが準備できたので、データを実際に操作できると便利だと思いませんか?データのパス、音声、スペクトログラム、メルスペクトログラムを一箇所で確認できるようにしておくと便利です。
まずは、一つひとつ順を追って見ていきます。 audio_filepath および保存する a スペクトログラムおよびメルスペクトログラムオーディオファイルのサムネイル画像を作成します。次に、を作成します。 wandb.Table をログに記録するために ファイル名、オーディオファイル、テキスト(モデルの出力目標)、スペクトログラム画像、メルスペクトログラム画像。
以下のコードでこれを実行できます:
def save_spectogram_as_img(audio_path, datadir, plt_type='spec'):filename = os.path.basename(audio_path)out_path = os.path.join(datadir, filename.replace('.wav', '.png'))audio, sample_rate = librosa.load(audio_path)if plt_type=='spec':spec = np.abs(librosa.stft(audio))spec_db = librosa.amplitude_to_db(spec, ref=np.max)else:mel_spec = librosa.feature.melspectrogram(audio, sr=sample_rate)mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)fig = plt.Figure()ax = fig.add_subplot()ax.set_axis_off()librosa.display.specshow(spec_db if plt_type=='spec' else mel_spec_db,y_axis='log' if plt_type=='spec' else 'mel',x_axis='time', ax=ax)fig.savefig(out_path)# convert audio file to spectogram and mel spectogram imagesif not os.path.exists('./an4/melspectogram_images/'):for path in tqdm(train_audio_paths):save_mel_spectogram_as_img(path, datadir='./an4/images/')save_spectogram_as_img(path, datadir='./an4/melspectogram_images/', plt_type='mel')# log filename, playable audio, duration of audio, transcript, spectogram and mel spectogram to W&B for ease of referenceif LOG_WANDB:# create W&B Tablewandb.init(project="ASR")audio_table = wandb.Table(columns=['Filename', 'Audio File', 'Duration', 'Transcript', 'Spectogram', 'Mel-Spectogram'])for path, duration, text in zip(train_audio_paths, train_durations, train_texts):filename = os.path.basename(path)img_fn = filename.replace('.wav', '.png')spec_pth = os.path.join('./an4/images', img_fn)melspec_pth = os.path.join('./an4/melspectogram_images', img_fn)audio_table.add_data(filename, wandb.Audio(path), duration, text, wandb.Image(spec_pth), wandb.Image(melspec_pth))wandb.log({"Train Data": audio_table})wandb.finish();
上のコードを実行すると、以下のような Weights and Biases のテーブルが表示されます。
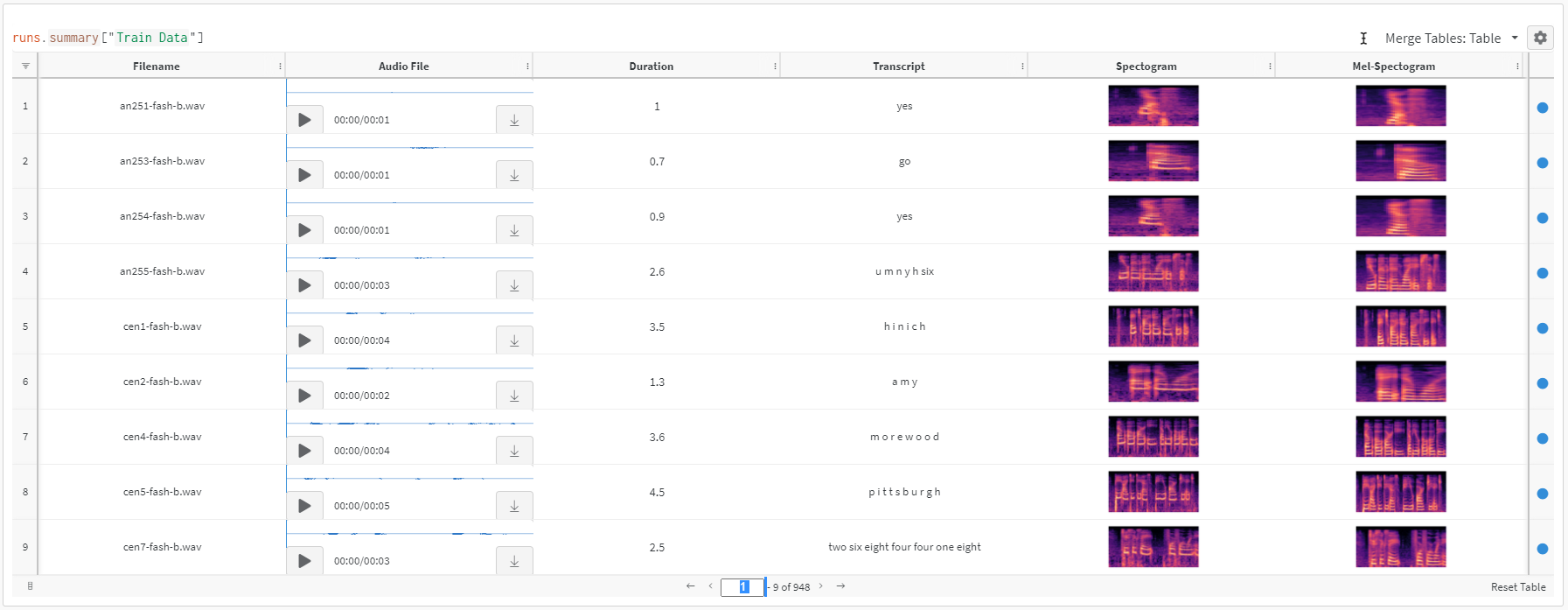
ご覧のとおり、データセットの探索はずっと簡単ですWeights and Biasesすべてが一箇所にまとまったテーブルです。オーディオを再生したり、文字起こしを確認したりできます。
素晴らしいです!データセットを作成し、データを簡単に確認できる方法が整ったので、次に進みましょう。
YAML設定ファイルでモデルを指定する
このチュートリアルでは、我々は…Jasper_4x1 モデル、で K=4 単一のブロック (R=1)サブブロックと1つの グリーディCTC、で見つかった設定を使用して ./configs/config.yaml。
この設定ファイルを開くと、モデルのアーキテクチャを記述した model セクションが見つかります。モデルには、ラベル付けされたエントリが含まれています。 encoder、で フィールド名が jasper 複数のエントリを持つリストが含まれています。このリスト内の各要素はモデル内の1つのブロックを指定しており、次のような形式になっています。
- filters: 128repeat: 1kernel: [11]stride: [2]dilation: [1]dropout: 0.2residual: falseseparable: truese: truese_context_size: -1
リストの最初の要素は、Jasperアーキテクチャ図の最初のブロックに対応しており、…に関係なく表示されます。 K 、 R次に、モデルの4つのエントリがあり、それぞれが…に対応します。 K=4 ブロックであり、それぞれが repeat: 1 私たちが使用しているので R=1これらに続いて、Jasperモデルの末尾でCTC損失の直前に現れるブロックに対応するエントリがさらに2つあります。
ファイルの先頭には、トレーニングの実行方法を指定するエントリもいくつかあります。train_ds)および検証validation_ds)データ。
このようなYAML設定を使うと、アーキテクチャ全体を素早く人間が読める形で把握でき、コードを変更せずにモデルや実行設定を簡単に差し替えられるので便利です。
上のパラメータをそのまま見ているだけでは本当に分かりにくいです。特に、同僚とパラメータや結果を共有するのは難しいです。以下では、Weights & Biases を使うとどれほど簡単にできるかを見ていきます。Weights and Biases統合PyTorch Lightningおよび Weights & Biases が結果、設定、テーブルをすべて一か所に保存する仕組みは、結果を再現しようとする際に非常に便利です。
PyTorch Lightning と Weights & Biases の統合によるトレーニング
NeMo のモデルやモジュールは、torch.nn.Module が期待される任意の PyTorch コードで使用できます。
ただし、NeMo のモデルは、 PyTorch Lightning の LightningModule を使用し、混合精度や分散トレーニングの利用が非常に簡単になるため、トレーニングやファインチューニングには Lightning の使用をおすすめします。ではまず、GPU 上で 50 エポックの学習を行うための Trainer インスタンスを作成しましょう。
import pytorch_lightning as pltrainer = pl.Trainer(gpus=1, max_epochs=50)
ご存知でしたか?Weights and Biasesは、すでに広く使われているフレームワークに統合されています。PyTorch Lightningこの段階では、単に使用するだけでもかまいません。 WandbLogger トレーニング中の進捗をすべて Weights & Biases に記録します!
import pytorch_lightning as plfrom pytorch_lightning.loggers import WandbLogger# initialize W&B logger and specify project name to store results towandb_logger = WandbLogger(project="ASR", log_model='all')# set config params for W&B experimentfor k,v in params.items():wandb_logger.experiment.config[k]=v# initialize trainer with W&B loggertrainer = pl.Trainer(gpus=1, max_epochs=10, logger=wandb_logger)
これは非常に便利で、実験を簡単に再現できるようになります。
次に、前節で作成した config.yaml ファイルに基づいて ASR モデルのインスタンスを作成します。この段階で、学習用および検証用のマニフェストファイルの場所をモデルに伝えることにも注意してください。
# Update train and test data pathparams['model']['train_ds']['manifest_filepath'] = train_manifestparams['model']['validation_ds']['manifest_filepath'] = test_manifest# initialize modelfirst_asr_model = nemo_asr.models.EncDecCTCModel(cfg=DictConfig(params['model']), trainer=trainer)
これで、たった一行でトレーニングを開始できます!
# Start training - this will automatically store results to Weights and Biasestrainer.fit(first_asr_model)wandb.finish();
できました!モデルの完全な学習パイプラインを構築し、10エポックで訓練を行いました。
Weights and Biases:Sweeps を使ったハイパーパラメータチューニング
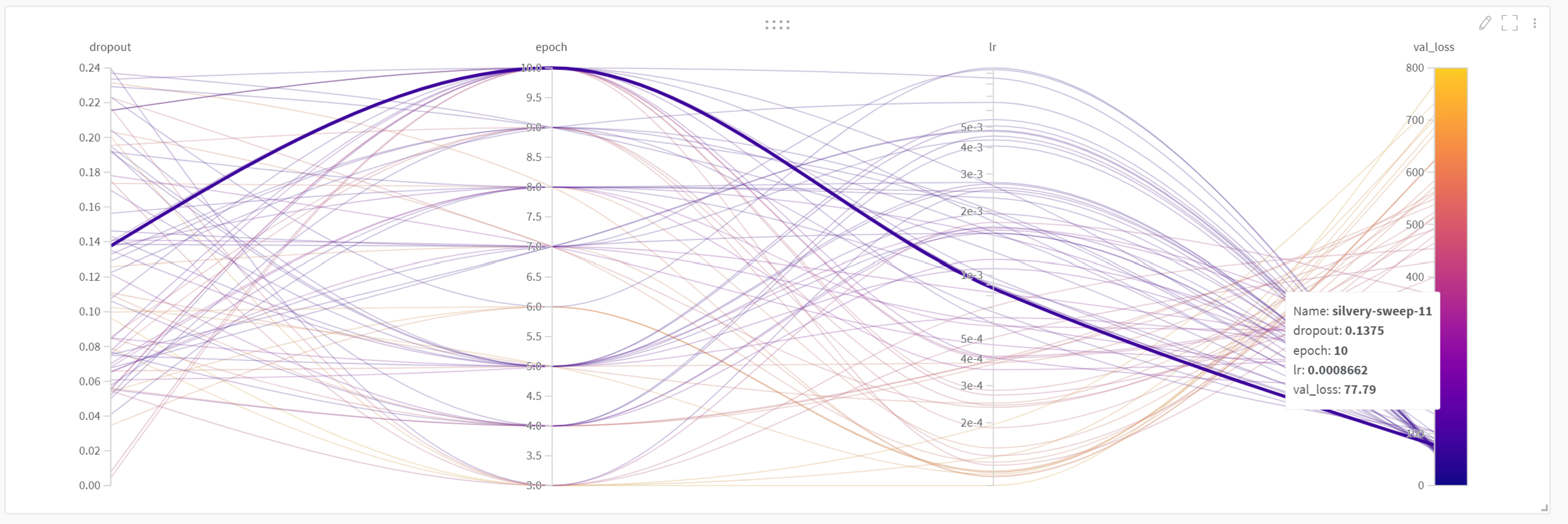
さらに、いくつかのハイパーパラメータをチューニングしたい場合もあります。以下では、考えられるすべてのパラメータのうちごく一部だけを取り上げています。 params、例えば lr、 epoch 、 dropout ハイパーパラメータのチューニングを紹介するために W&B Sweeps。
ドキュメントによると、W&B Sweeps を使用する利点は多数あります:
- クイックセットアップ:数行のコードだけで始められます。数十台のマシンでスイープを実行することもでき、ノートパソコンでスイープを開始するのと同じくらい簡単です。
- 透明:私たちは使用しているすべてのアルゴリズムを引用し、コードはオープンソースとして公開しています。
- 強力です私たちの Sweeps は完全にカスタマイズおよび設定可能です。
このASRの例にSweepsを追加するのはとても簡単です。まず、以下のようにスイープ構成(sweep config)を定義します:
sweep_config = {"method": "random", # Random search"metric": { # We want to minimize `val_loss`"name": "val_loss","goal": "minimize"},"parameters": {"lr": {# log uniform distribution between exp(min) and exp(max)"distribution": "log_uniform","min": -9.21, # exp(-9.21) = 1e-4"max": -4.61 # exp(-4.61) = 1e-2},"epoch": {"distribution": "int_uniform","min": 3,"max": 10},"dropout": {"distribution": "uniform","min": 0,"max": 0.25}}}
次に、私たちは定義します sweep_iteration 以下のように機能します。主な違いは、これらの値が今や〜から取得される点です。 wandb.config ハードな固定値ではなく設定されます。
例、
params['model']['optim']['lr'] = wandb.config.lrparams['model']['encoder']['jasper'][-1]['dropout'] = wandb.config.dropout
これらの値はスイープごとに変わるため、これらの値は〜から取得します。 wandb.config 以下のとおり。
def sweep_iteration():# load configconfig_path = './configs/config.yaml'yaml = YAML(typ='safe')with open(config_path) as f:params = yaml.load(f)# set up W&B loggerwandb.init() # required to have access to `wandb.config`wandb_logger = WandbLogger(log_model='all') # log final model# setup dataparams['model']['train_ds']['manifest_filepath'] = train_manifestparams['model']['validation_ds']['manifest_filepath'] = test_manifest# setup sweep paramparams['model']['optim']['lr'] = wandb.config.lrparams['model']['encoder']['jasper'][-1]['dropout'] = wandb.config.dropouttrainer = pl.Trainer(gpus=1, max_epochs=wandb.config.epoch, logger=wandb_logger)# setup model - note how we refer to sweep parameters with wandb.configmodel = nemo_asr.models.EncDecCTCModel(cfg=DictConfig(params['model']), trainer=trainer)# traintrainer.fit(model)
最後に、wandb のスイープを作成し、次の項目を渡します。 wandb_config 次に、さまざまな実行を行うエージェントを作成します。このエージェントはスイープの「method」に基づいてパラメータを選択し、各パラメータ値について検証損失(val_loss)を比較します。
sweep_id = wandb.sweep(sweep_config, project="ASR")wandb.agent(sweep_id, function=sweep_iteration)
Weights and Biases:パフォーマンス指標をログ記録する
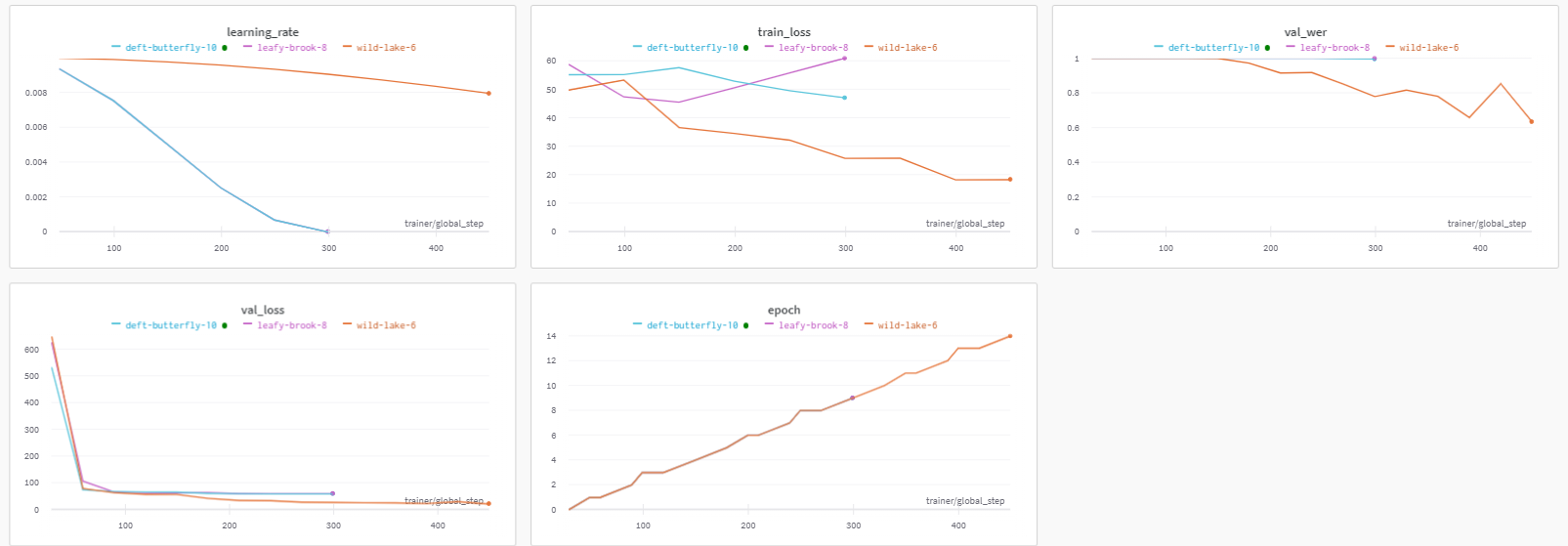
実行する 上記のトレーニングコードは、すべてのトレーニング指標を Weights & Biases に保存し、見やすいダッシュボードを作成します。記録されたトレーニング指標はダッシュボードで確認できます。 ここ。
ダッシュボードは以下のようになります:
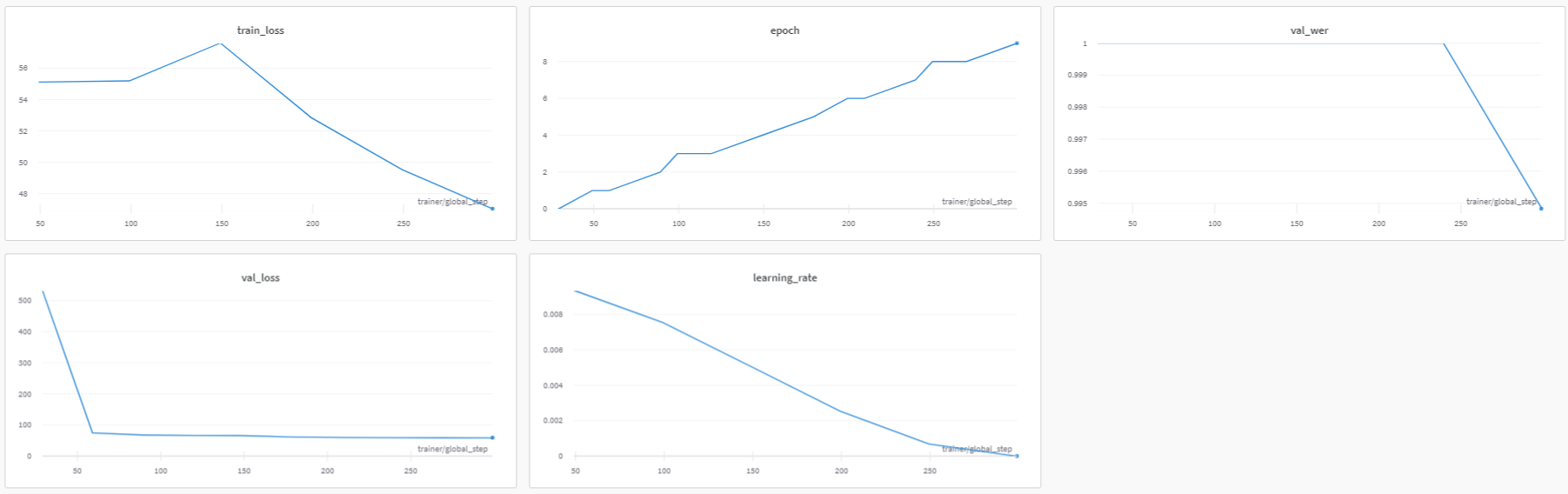
上のダッシュボードからわかるように、学習率や訓練損失、検証損失といった指標を一目で確認でき、これらは指標をWeights & Biasesにログ記録していなければここまで簡単には見られません。Weights and Biases。
Weights and Biases: ログ設定
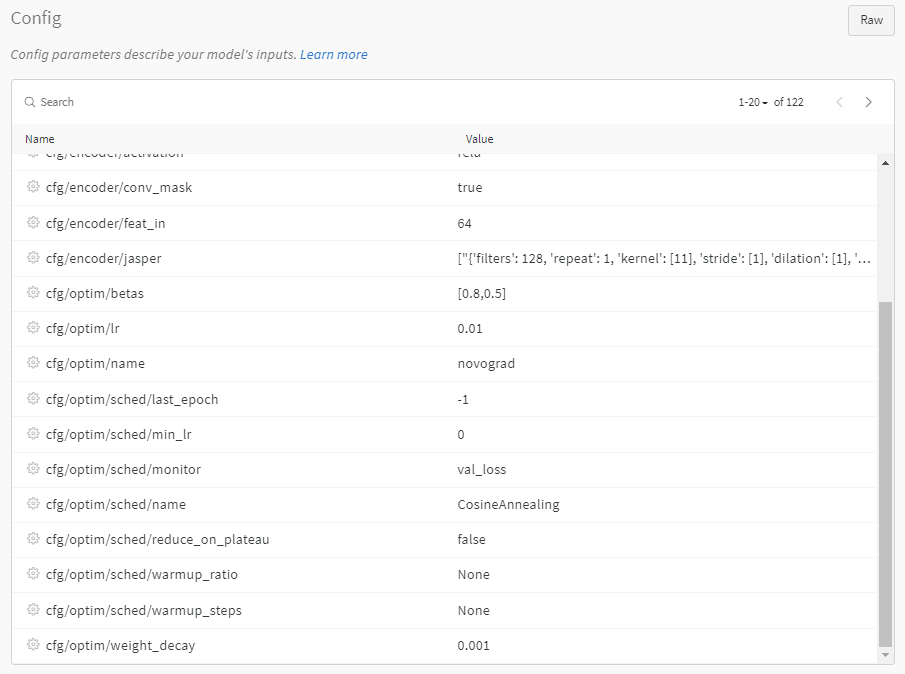
結果をWeights and Biasesに保存するもうひとつの利点は、設定パラメータを一目で確認できる点です。以下のように、パラメータを簡単かつわかりやすく閲覧できます。
Weights and Biases: 実験の比較
Weights and Biases: モデルアーティファクト
このモデルのチェックポイントを後で読み込めるように保存したい場合(例:ファインチューニングやトレーニングの継続のため)、次のように呼び出すだけで構いません first_asr_model.save_to(<checkpoint_path>)。次に、重みを復元するには、設定ファイルを使ってモデルを再構築します(ここでは仮にと呼ぶことにします)。 first_asr_model_continued 今回) first_asr_model_continued.restore_from(<checkpoint_path>)。
進捗とモデルの重みを手早く保存するもう一つの方法は、を使用することです。Weights and Biasesアーティファクト。こちらを指定したため log_model='all' へ WandbLoggerWeights and Biases はすでに各エポックごとに全てのモデル重みを保存しています。

これらのモデル重みはどれも非常に簡単に使えます。やることは次の2行のコードを実行するだけです。
artifact = run.use_artifact('user_name/project_name/new_artifact:v1', type='my_dataset')artifact_dir = artifact.download()
ご覧のとおり、これによりモデルがダウンロードされます。 './artifacts/model-2kr60tp1:v9'
推論
NeMoのASRモデルで推論を実行する方法を手短に見てみましょう。
まず、 EncDecCTCModel およびそのサブクラスには便利な機能が含まれています transcribe 音声ファイルの文字起こしを簡単に取得するために使えるメソッドです。パフォーマンス向上のために batch_size 引数も用意されています。
if LOG_WANDB:preds = quartznet.transcribe(paths2audio_files=test_audio_paths, batch_size=16)pred_table = wandb.Table(columns=['FileName', 'Audio', 'Prediction', 'Ground Truth'])for path, gt, pred in zip(test_audio_paths, test_texts, preds):pred_table.add_data(os.path.basename(path), wandb.Audio(path), pred, gt)run = wandb.init(project='ASR')wandb.log({'Prediction Table': pred_table})wandb.finish();
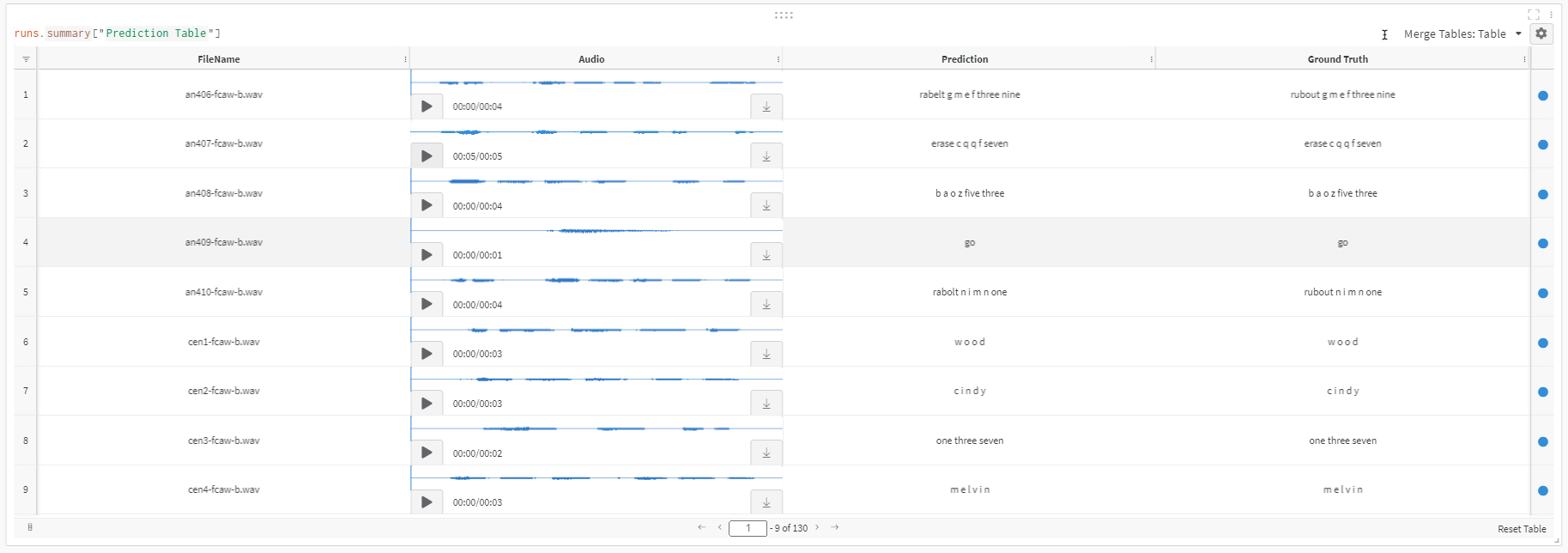
また、以下は純粋な PyTorch で書かれた簡単な推論ループの例です。予測結果と参照テキスト間の単語誤り率(WER)をどのように計算するかも示しています。
import copynew_opt = copy.deepcopy(params['model']['optim'])new_opt['lr'] = 0.001first_asr_model.setup_optimization(optim_config=DictConfig(new_opt))# Bigger batch-size = bigger throughputparams['model']['validation_ds']['batch_size'] = 16# Setup the test data loader and make sure the model is on GPUfirst_asr_model.setup_test_data(test_data_config=params['model']['validation_ds'])first_asr_model.cuda()# We will be computing Word Error Rate (WER) metric between our hypothesis and predictions.# WER is computed as numerator/denominator.# We'll gather all the test batches' numerators and denominators.wer_nums = []wer_denoms = []# Loop over all test batches.# Iterating over the model's `test_dataloader` will give us:# (audio_signal, audio_signal_length, transcript_tokens, transcript_length)# See the AudioToCharDataset for more details.for test_batch in first_asr_model.test_dataloader():test_batch = [x.cuda() for x in test_batch]targets = test_batch[2]targets_lengths = test_batch[3]log_probs, encoded_len, greedy_predictions = first_asr_model(input_signal=test_batch[0], input_signal_length=test_batch[1])# Notice the model has a helper object to compute WERfirst_asr_model._wer.update(greedy_predictions, targets, targets_lengths)_, wer_num, wer_denom = first_asr_model._wer.compute()first_asr_model._wer.reset()wer_nums.append(wer_num.detach().cpu().numpy())wer_denoms.append(wer_denom.detach().cpu().numpy())# Release tensors from GPU memorydel test_batch, log_probs, targets, targets_lengths, encoded_len, greedy_predictions# We need to sum all numerators and denominators first. Then divide.print(f"WER = {sum(wer_nums)/sum(wer_denoms)}")
この WER は特に優れた数値ではなく、かなり改善の余地があります。より良い結果を得るには、学習を長く行ってみてください(例えば 100 エポックを試してください)。さらに改善する方法については次のセクションを参照してください。
モデルの改善
NeMo で独自の ASR モデルを作成するのに必要なものはすでに揃っていますが、さらに試せるテクニックがいくつかあります。本節では、ASR モデルを改善するためのいくつかの方法を簡単に紹介します。
データ拡張
トレーニングセットのサイズを増やせる音声認識(ASR)向けのデータ拡張手法はいくつか存在します。
たとえば、スペクトログラムに対して、特定の周波数帯域をゼロにする「周波数マスキング」や、特定の時間区間をゼロにする「時間マスキング」といった拡張を行うことができます。 SpecAugment、またはスペクトログラム上の長方形領域をゼロにする方法などです。 CutoutNeMo では、これらのいずれも、単に に追加するだけで実行できます。 SpectrogramAugmentation ニューラルモジュール。
転移学習
転移学習は、あるタスクで獲得したモデルの知識を別のタスクに活用して性能を向上させる重要な機械学習手法です。��ァインチューニングは転移学習を行うための手法の一つで、基盤モデルを大量の訓練データで事前学習し、その後データが少ない、あるいは乏しい別のタスクに対して調整(微調整)するという、最先端成果で広く用いられている手順の重要な要素です。
ASRでは、特定のドメイン(医療、金融など)や訛りのある音声に対してモデルの性能を向上させたい場合など、さまざまな状況でファインチューニングを行うことがあります。ある言語から別の言語へ転移学習を行うことも可能です。具体例についてはこの論文を参照してください。
NeMoを使った転移学習は簡単です。ここでは、クラウドから取得したモデルをAN4データでファインチューニングする方法を示します(注:これはおもちゃの例です)。ついでに、やり方を示すためにモデルの語彙も変更してみます。
# Check what kind of vocabulary/alphabet the model has right nowprint(quartznet.decoder.vocabulary)# Let's add "!" symbol there. Note that you can (and should!) change the vocabulary# entirely when fine-tuning using a different language.quartznet.change_vocabulary(new_vocabulary=[' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n','o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', "'", "!"])>> [' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', "'"][NeMo I 2022-01-19 15:31:05 ctc_models:348] Changed decoder to output to [' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', "'", '!'] vocabulary.
この変更でデコーダは完全に入れ替わりましたが、重みの大部分を占めるエンコーダはそのまま残っています。このモデルをAN4データセットで2エポックだけファインチューニングしましょう。
# Use the smaller learning rate we set beforequartznet.setup_optimization(optim_config=DictConfig(new_opt))# Point to the data we'll use for fine-tuning as the training setquartznet.setup_training_data(train_data_config=params['model']['train_ds'])# Point to the new validation data for fine-tuningquartznet.setup_validation_data(val_data_config=params['model']['validation_ds'])# And now we can create a PyTorch Lightning trainer and call `fit` again.trainer = pl.Trainer(gpus=[1], max_epochs=2)
参考資料/視聴案内
ひとまずここまでです!このチュートリアルで扱ったトピックについてさらに学びたい場合は、以下の参考資料が役立つかもしれません。
Add a comment