
Die ganze Rechenleistung – keine Komplexität
Starten Sie einen Job in einer beliebigen Zielumgebung, um ML-Trainingsworkloads drastisch von der lokalen Maschine auf verteilte Rechner zu skalieren. Greifen Sie problemlos auf externe Umgebungen, bessere GPUs und Cluster zu, um die Geschwindigkeit und den vorhersehbaren Umfang Ihres ML-Workflows zu erhöhen.
")
Bridge ML-Praktiker undMLOps
Beseitigen Sie Organisationssilos mit einer gemeinsamen Schnittstelle. Anwender erhalten die Rechenleistung, die sie benötigen, wobei die gesamte Infrastrukturkomplexität abstrahiert wird, während MLOps die Übersicht und Beobachtung der von ihnen verwalteten Infrastrukturumgebungen aufrechterhält. Arbeiten Sie gemeinsam, um ML-Aktivitäten zu skalieren.
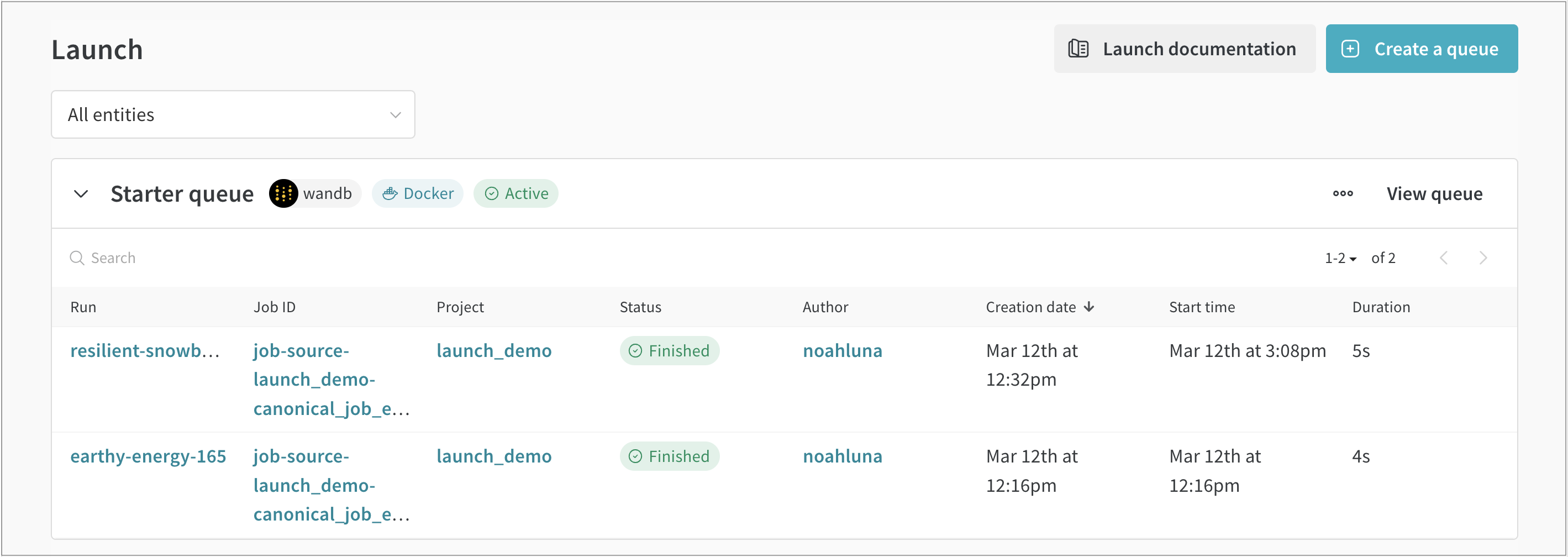
Leicht zu laufen kontinuierliche Integrations- und Evaluierungsjobs
Reduzieren Sie Ihre Zykluszeit für die Bereitstellung genehmigter Modelle in Produktionsinferenzumgebungen drastisch. Bewerten Sie Ihre Modelle häufiger, gründlicher und kontinuierlicher, mit der Möglichkeit, Läufe mit nur einem Klick zu reproduzieren. Verwenden Sie Sweeps on Launch, um Regler einfach einzustellen und Hyperparameter zu ändern, bevor Sie Jobs erneut ausführen.

")
Verbesserte Observabilität fürML-Ingenieure
Machen Sie sich transparenter, wie Ihr ML-Infrastrukturbudget genutzt wird … oder nicht. Rationalisieren Sie Ihre Ausgaben für bedeutende Infrastrukturinvestitionen und legen Sie bessere Standardeinstellungen fest, um eine optimale und effiziente Nutzung dieser Ressourcen sicherzustellen.
Skalieren Sie Ihre ML-Workflows noch heute mitW&B Start
Gewichte & Die Biases-Plattform hilft Ihnen, Ihren Arbeitsablauf von Anfang bis Ende zu optimieren.
Modell
Experiment
Tracking und Visualisierung ML-Experimente
fegen
Optimierung Hyperparameter
Modellregister
Registrierung und Verwaltung von ML-Modellen
Automatisierung
Lösen Sie Workflows automatisch aus
Start
Verpackung und Betrieb ML-Workflow-Aufgaben
salzig
Beweis
Entdecken Sie
LLM-Debug
Auswertung
Strenge Bewertung von GenAI-Anwendungen