EfficientNetV2
As part of this blog, we are going to be looking into the EfficientNetV2 architecture in detail with code implementation in PyTorch.
Created on May 3|Last edited on May 5
Comment
After the massive success of the EfficientNet architecture, Mingxin Tan and Quoc V. Le have done it again! This time they have come up with a new family of networks that have faster training speed and better parameter efficiency - EfficientNetV2!
As part of this blog post we are going to be looking into the EfficientNetV2 architecture in detail and specifically try to answer these questions:
- How does the design of EfficientNetV2 architecture looks like? How is different from EfficientNet (from here on referred to as "EfficientNetV1") ?
- What is the new Fused-MBConv layer that is used in the in EfficientNetV2 architecture? How does it compare to MBConv layers used in EfficientNets?
- How does the EfficientNetV2 architecture compare to ResNet-RS, NfNet and Vision Transformer(ViT) rchitectures?

Figure-1: ImageNet ILSVRC2012 top-1 Accuracy vs. Training Time and Parameters – Models tagged with 21k are pretrained on ImageNet21k, and others are directly trained on ImageNet ILSVRC2012. Training time is measured with 32 TPU cores. All EfficientNetV2 models are trained with progressive learning.
As can be seen from Figure-1, the EfficientNet-V2 models have lower training time and higher accuracy when compared to the training time and accuracies of other models such as ResNet-RS, NfNet, ViT & EfficientNetV1s!
So how did they do it? We'll find out in this blog post.
Prerequisite
It would really help if the reader has a good understanding of EfficientNetV1 - the EfficientNetV2 architecture is just an extension of the authors prior work in EfficientNetV1.
👉 I have previously written a blog post explaining all the details of the EfficientNetV1 archicture here - EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.
👉 I have also previously written about Vision Transformer, NF-ResNet and ResNet-RS architectures here -
NF-ResNets: Characterizing Signal Propagation to Close the Performance Gap in Unnormalized ResNets
👉 From this point on, I am going to assume that the reader has referred to these resources and understands these architectures.
With that being said, let's begin!
Introduction
EfficientNetV2 architecture was developed in exactly the same way as EfficientNetV1 and the main contributions of the paper are:
- Introduce new EfficientNetV2 architecture.
- Proposed an improved method of progressive learning, which adjusts the regularization with image size.
- Upto 11x faster training speed and 6.8x better parameter efficiency for EfficientNetV2 architecture as shown in Figure-1.
So let's understand how the authors designed the EfficientNetV2 architecture.
Review - EfficientNetV1 architecture
For a detailed explaination on EfficientNetV1, I redirect the reader to this resource mentioned on EfficientNetV1 in the Prerequisites section above.
But, let's quickly review EfficientNetV1. From the blog post, we know that the structure of EfficientNetV1 looks like:
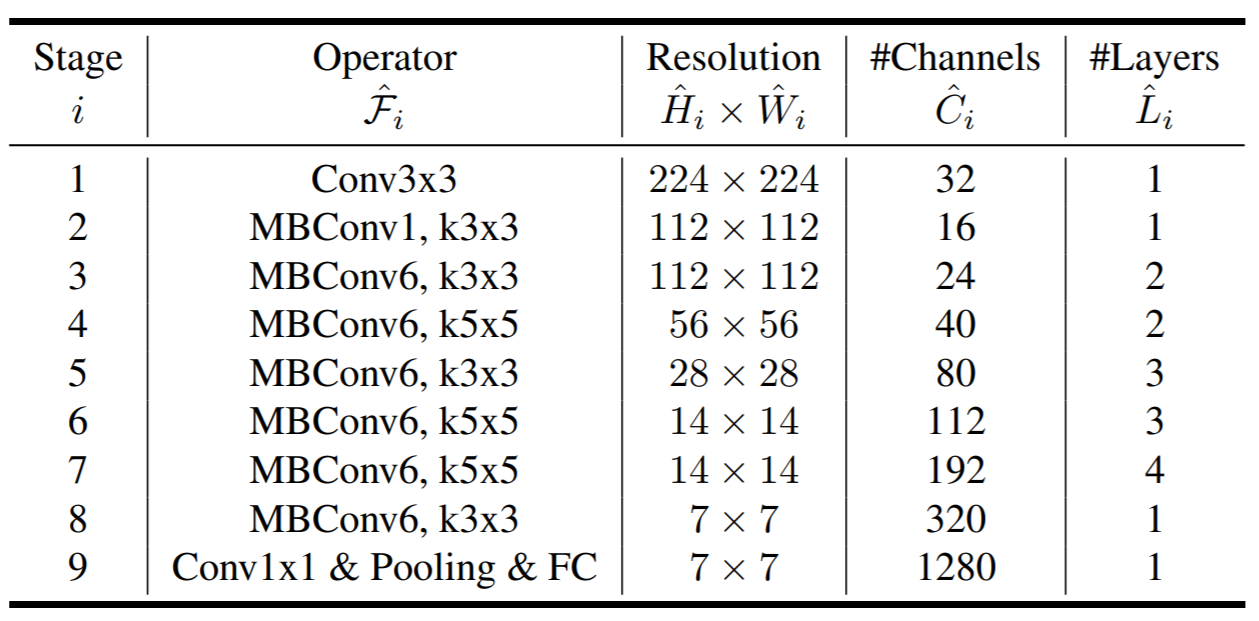
Table-1: EfficientNetV1-B0 baseline architecture
As can be seen, the EfficientNetV1-B0 architecture consists of 9 stages. Ignoring the first and the last stage which consist of a 3x3 convolution and a 1x1 convolution with pooling & FC, the rest of the architecture heavily utilizes MBConv building block.
EfficientNetV2 architecture design
Having briefly reviewed the EfficientNetV1 architecture above, in this section of the blog post, we look at the limitations of the EfficientNetV1 architecture and understand how the EfficientNetV2 architecture overcomes these limitations.
Training with very large image sizes is slow
As pointed out in previous works by Designing Network Design Spaces, EfficientNet's large image size results in significant memory usage. Since the total memory on hardware devices such as GPU/TPU is fixed, therefore, these models with larger image sizes need to be trained with smaller batch size. One simple improvement that can be used to fix this is to use the methodology mentioned in Fixing the train-test resolution discrepancy (FixRes) paper where the main idea is to train on smaller on image sizes and test on larger image sizes.

Table-2: EfficientNet-B6 accuracy and training throughput for difference input image size and batch size
As can be seen in table-2 above, by using the FixRes technique mentioned above, using smaller image sizes leads to slightly better accuracy.
Depthwise convolutions are slow in early layers
We already know that the EfficientNetV1 architecture utilized MBConv layers with depthwise convolutions. Depthwise convolutions have fewer parameters and FLOPs than regular convolutions, but they often cannot fully utilize the modern accelerators. This means that a reduction in FLOPs doesn't necessarily lead to improvement in training speed.
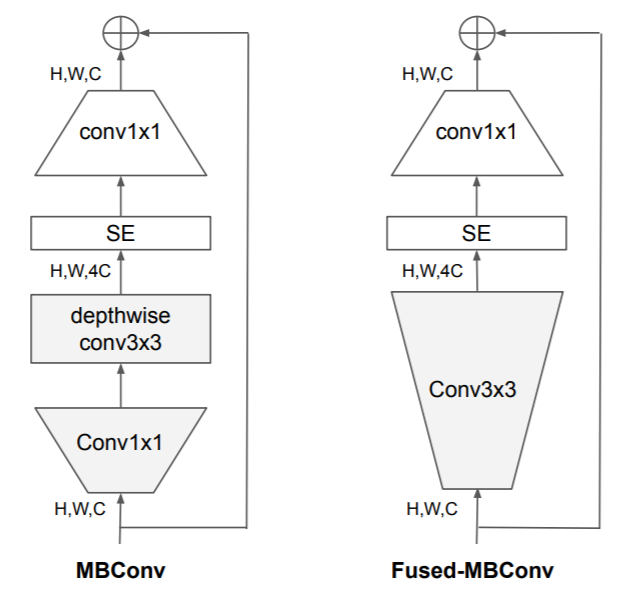
Figure-2: Structure of MBConv and Fused-MBConv.
Recently, Fused-MBConv was proposed which replaces the depthwise 3x3 convolution and expansion 1x1 convolution in MBConv with a regular 3x3 convolution as shown in Figure-2 above.
To compare these two building blocks and performance improvement, the authors of the EfficientNetV2 architecture gradually replaced the original MBConv in EfficientNetV1 with Fused-MBConv and the results are shown in table-2 below.

Table-3: Replacing MBConv with Fused-MBConv. No fused denotes all stages use MBConv, Fused stage1-3 denotes replacing MBConv with Fused-MBConv in stage {2, 3, 4} as in table-1.
As can be seen in table-3 above, it was observed that when Fused-MBConv is applied in the early layers (stages 1-3), this can lead to an improvment in the training speed with a small overhead on parameters and FLOPs. However, if the authors replace all blocks with Fused-MBConv, then it significantly increases parametrs and FLOPs while also slowing down training speed.
Since, there is no simple answer as to when to utilize Fused-MBConv or MBConv, the authors leveraged nueral architecture search to search for the best combination.
Equally scaling up every stage is sub-optimal
EfficientNetV1 architecture equally scales up all the stages using a simple compound scaling rule. However, these stages are not equally contributed to the training speed and parameter efficiency. Therefore, for EfficientNetV2, the authors use a non-uniform scaling strategy to gradually add more layers.
EfficientNetV2 Architecture
Table-4 below shows the articuture for EfficientNetV2-S which was found using neural architecture search (NAS) and the changes mentioned above.

Table-4: EfficientNetV2-S architecture
As opposed to EfficientNetV1, it can be observed that:
- The EfficientNetV2 architecture extensively utilizes both MBConv and the newly added Fused-MBConv in the early layers.
- EfficientNetV2 prefers small 3x3 kernel sizes as opposed to 5x5 in EfficientNetV1.
- EfficientNetV2 completely removes the last stride-1 stage as in EfficientNetV1 (table-1).
And that's it! That's the EfficientNetV2 architecture in all it's glory.
Progressive Learning
Progressive resizing was first introduced by Jeremy Howard in the popular fast.ai course. The main idea is to gradually increase the image size as the training progresses. For example, if we are to train for a total of 10 epochs, then start out with image size 224x224 for the first 6 epochs and then finetune using image size 256x256 for the last 4 epochs.
However, going from a smaller image size to a larger image size leads ton accuracy drop. The authors of EfficientNetV2 paper hypothesize that this drop comes from unbalanced regularization. When training with different image sizes, they mention that we should also change the regularization strength accordingly.
To validate their hypothesis, they train a model with different image sizes and data augmentations as shown in table-5 below.

Table-5: ImageNet top-1 accuracy.
It can be observed from table-5 above, when the image size is small, it has the best accuracy with weak augmentation; but for larger image size, it performs better with stronger augmentation. This observation motivated the authors to adaptively adjust regularization along with image size during training - leading to this different method of progressive learning.
For more details on progressive learning and various data augmentations used, I refer the reader to section 4.2 in the research paper.
Conclusion
As part of this blog post we looked at the architecture changes in EfficientNetV2 architecture compared to the EfficientNetV1 architecture. Having a different neural architecture search space with operations such as Fused-MBConv, the EfficientNetV2 architecture performs better than previous models on speed-accuracy curve (figure-1).
To further speed up training, the authors also introduced a different method of progressive learning, that jointly increases image size and regularization during training. Compared to EfficientNetV1, the EfficientNetV2 architecture trains upto 11x faster while being 6.8x smaller.
Add a comment