Rewriting a Deep Generative Model: An Overview
In this article, we will explore the work presented in the paper "Rewriting a Deep Generative Model" by Bau et al. It shows a new way of looking at deep neural networks. This is a translated version of the article. Feel free to report any possible mis-translations in the comments section
Created on August 26|Last edited on August 26
Comment
In the words of the authors:
"Deep network training is a blind optimization procedure where programmers define objectives but not the solutions that emerge. In this paper, we ask if deep networks can be created in a different way.Can the rules in a network be directly rewritten?"
The Paper | The Code | Interactive Google Colab →
The blind optimization procedure is investigated quantitatively in the paper "Deep Ensembles: A Loss Landscape Perspective" by Fort et al. Sayak Paul, and I explored this paper in this article.
The usual recipe for creating a deep neural network is to train such a model on a massive dataset with a defined objective function. This takes a considerable amount of time and is expensive in most cases. The authors of Rewriting a Deep Generative Model propose a method tocreate new deep networks by rewriting the rule of an existing pre-trained networkas shown in figure 1. By doing so, they wish to enable novice users to easily modify and customize a model without the training time and computational cost of large-scale machine learning.

->Figure 1: Rewriting GAN without training to remove the watermark, to add people, and to replace the tower with the tree. (Source) <-
They do so by setting up a new problem statement:manipulation of specific rules encoded by a deep generative model.
Table of Contents
Why Is Rewriting Deep Generative Model Useful?An Overview of the PaperUser InterfacePutting it all Together and Ending Note
Why Is Rewriting Deep Generative Model Useful?
Deep generative models such as a GAN can learn rich semantic and physical rules about a target distribution (faces, etc.). However, it usually takes weeks to achieve state-of-the-art GAN on any dataset.
If the target distribution changes by some amount, retraining a GAN would be a waste of resources. However, what if we directly change some trained GAN rules to reflect the target distribution change? Thus by rewriting a GAN:
- We can build a new model without retraining, which is a more involved task.
- From the perspective of demystifying deep neural nets, the approach to edit a model gives new insight about the model and how semantic features are captured.
- It can also provide some insight into the generalization of deep models to unseen scenarios.
- Unlike conventional image editing tools where the desired change is applied on a single image, by editing a GAN, one can apply the edit on every image generated.
- Using this tool, one can build new generative models without domain expertise, training time, and computational expense.
An Overview of the Paper
The usual practice is to train a new model for every new version(slightly different target distribution) of the same dataset. By rewriting a specific rule without effecting other rules captured by the model, a lot of training and computing time is reduced.
How can we edit generative models? In the words of the authors,
"..we show how togeneralize the idea of a linear associative memory to a nonlinear convolutional layerof a deep generator. Each layer stores latent rules as a set of key-value relationships over hidden features. Ourconstrained optimization aims to add or edit one specific rulewithin the associative memory while preserving the existing semantic relationships in the model as much as possible. We achieve it by directly measuring and manipulating the model's internal structure,without requiring any new training data."
To specify the rules, the authors have provided an easy to use interface. The video linked above has a clear explanation of using this interface.
Try out the interface in Google Colab
1. Change Rule With Minimal Collateral Damage
- We start with a pre-trained GAN. The authors have used StyleGAN and Progressive GAN pre-trained models trained on multiple datasets.
- With a given pre-trained generator(yes we are discarding discriminator),, we can generate many(infinite) synthetic images. To generate an imagea latent code(just a random vector sampled from a multivariate normal distribution)is required. Thus for a given;.
- The user wants to apply a change such that the new image is. For the generator,to producewould not be possible since the changed image represents a target distribution that the GAN was not trained on. We thus need to find updated weightssuch that. Interesting!
- Note thatrepresents the trainable weights or parameters in our GAN generator. The number of parameters is huge in standard SOTA GANs leading to easy overfitting. The aim here is to have a generalized rewritten GAN.
- The authors provided two modifications to the standard approach to tackle this manipulation of hidden features in the generator.
- Instead of updating all of, the authors proposed to modify the weights of one layer. Thus all other layers are frozen/made non-trainable.
- The objective function(sayloss) is applied in the output feature space of that layer instead of the generator's output.
- So now, given a layer, letbe the feature output from thelayer(frozen). We can write the feature output from thelayer as. Thus the output from the target layer,, is defined as a functionwith input asand pre-trained weights.
- For a latent code, the output from the firstlayer is. (Note here the use ofwithdoes not mean a change in the rule specified by the user). Thus the output of the target layerwould be.
- For each target example, this is specified by the user manually, there is a feature change. The aim is to have a generatorsuch that it can produce target examplewith minimum interference with other behavior of the generator.
- This can be solved by minimizing a simple joint objective function.
-

-
- Thus, we are updating the weights, of target layerby minimizingsmooth[[TRANSLATION_FAILED]]constraintloss. Thesmoothloss function ensures that the output generated by the new rule is not far apart from the initial(pre-trained) one. Theconstraintloss ensues a specific rule to be modified or added.
- Alsodenotes theloss.
2. The Analogy of Associative Memory
- Any matrixcan be used as an associative memory that stores a set of key-value pairs {[[TRANSLATION_FAILED]]
-
- [[TRANSLATION_FAILED]][[TRANSLATION_FAILED]]
- [[TRANSLATION_FAILED]][[TRANSLATION_FAILED]]
- [[TRANSLATION_FAILED]]
- [[TRANSLATION_FAILED]][[TRANSLATION_FAILED]][[TRANSLATION_FAILED]][[TRANSLATION_FAILED]]
-
- [[TRANSLATION_FAILED]][[TRANSLATION_FAILED]][[TRANSLATION_FAILED]][[TRANSLATION_FAILED]] [[TRANSLATION_FAILED]][[TRANSLATION_FAILED]][[TRANSLATION_FAILED]].
3. How to Updateto Insert a new Value?
To add a new rule or modify an existing rule we will have to modify the pre-trainedweights of layerwhich is given by. The user will provide a single key to assign a new value such that. The modified weights matrixshould be such that it satisfies two conditions:
- It should store a new value.
- It should continue to minimize errors in all the previously stored values.
This modifiedis given by,
subject to
Just like previous section point 5, this is a least square problem, however this time it's a constrained least-square(CLS) problem which can be solved exactly as:
where
From the previous section point 5, we can replaceat. The modified equation is,
or,
where
There are two interesting points of the last equation derived,
- For the requested mappingthe final form of the equation transforms the soft error minimization objective into hard constraint such that the weights be updated in a particularly straight direction.
- The update directionis determined only by overall key statistics and the specific targeted key.
Note:is a model constant which can be pre-computed and cached. Onlywhich specifies the magnitude of change depends on target value.
4. Generalizing to a Non-Linear layer
So far, the discussion was done, assuming a linear setting. However, the convolutional layer of a generator or, in general, have several non-linear components like biases, activation(ReLU), normalization, style module, etc.
The authors have generalized the idea of associative memory such that:
- They first define the update direction,. It was derived in the previous section.
- Then, in order to insert a new key, they begin withand perform an optimization over the rank-one subspace defined by the row vector. First, this optimization is solved:
-
- Onceis calculated, weight is updated such that,
-
The authors have expanded this idea to insert the desired change for more than one key at once.
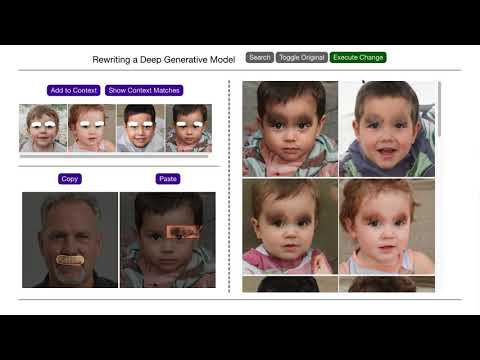
User Interface
If you are frustrated with all this mathematics, the good news is that the authors were kind enough to build us a user interface to edit a GAN easily. The video linked above is an excellent demonstration of this user interface tool by the authors.

This interface provides a three-step rewriting process:
- Copy - the user can use a brush to copy fascinating region in an image to define target value
- Paste - the user can paste the copied value into a single target image specifyingconstraint.
- Context - for generalization, the user can select the same interesting region in multiple images. This establishes the updated directionfor the associative memory.
Try out the interface in Google Colab

Figure 4: User interface as seen after running the linked Colab notebook.
Putting it all Together and Ending Note
The authors have used the user interface and the idea behind rewriting generative models to showcase multiple use cases. Some of them are:
- Putting objects/interesting regions into a new context. You can add trees to the top of the building or a dome in place of a pointy tower. You can also put the moustache in place of an eyebrow!
- Removing undesired features like a watermark in an image or some artifacts in an image. This is a handy outcome of this idea.
In the words of the authors,
"Machine learning requires data, so how can we create effective models for data that do not yet exist?Thanks to the rich internal structure of recent GANs, in this paper, we have found it feasible to create such models by rewriting the rules within existing networks."
This is truly a novel bit.
Thank you for sticking so far with this article. I wrote this article with the intent to provide an easy start to the paper. If something is still not clear or I made some mistakes, please provide your feedback in the comment section.
Finally, this article showcases the rich writing experience one can get while writing such W&B reports. I hope you enjoyed reading it. Thank you.
Add a comment