NVIDIA NeMo로 자동 음성 인식 모델을 학습하고 최적화하고 분석하고 시각화하고 배포하기
자동 음성 인식(ASR)은 음성 언어를 자동으로 받아쓰는 기술로, 일반적으로 음성을 텍스트로 변환하는 것을 의미합니다. 이 블로그에서는 NVIDIA의 Neural Modules(NeMo) 툴킷을 사용해 엔드 투 엔드 ASR 시스템을 학습하는 방법과, Weights & Biases를 사용해 다양한 실험과 성능 지표를 체계적으로 추적하는 방법을 배웁니다. 이 글은 AI 번역본입니다. 오역이 있을 수 있으니 댓글로 알려 주세요.
Created on September 12|Last edited on September 12
Comment
목차(클릭하여 펼치기)
소개
이 보고서에서는 다음 내용을 살펴봅니다 자동 음성 인식 (ASR) 사용 예 NVIDIA NeMo 또한 사용하는 방법을 보여줍니다 Weights & Biases 여러 실험과 성능 지표를 체계적으로 기록하고 추적하기 위해.
NVIDIA NeMo란 무엇인가요?
NVIDIA NeMo는 자동 음성 인식(ASR), 자연어 처리(NLP), 음성 합성(TTS)을 연구하는 연구자들을 위해 설계된 대화형 AI 툴킷입니다. NeMo의 주요 목표는 산업계와 학계의 연구자들이 기존 작업(코드와 사전 학습된 모델)을 재사용하고, 새로운 대화형 AI 모델을 더 쉽게 만들 수 있도록 돕는 것입니다.
Weights & Biases란 무엇인가요?
Weights & Biases는 머신러닝 팀이 더 나은 모델을 더 빠르게 만들 수 있도록 돕습니다. 몇 줄의 코드만으로 모델의 아키텍처, 하이퍼파라미터, git 커밋, 모델 가중치, GPU 사용량, 데이터셋, 예측 결과를 즉시 디버깅하고 비교하며 재현할 수 있고, 팀원들과 원활하게 협업할 수 있습니다.
W&B는 전 세계의 가장 혁신적인 기업과 연구 기관에서 활동하는 200,000명 이상의 머신러닝 실무자에게 신뢰받고 있습니다. 시작은 무료이며, 몇 줄의 코드만으로 5분 안에 통합할 수 있습니다. 시작하려면 여기를 클릭하세요 무료로.
소개: 자동 음성 인식(ASR)이란 무엇인가요?
ASR, 또는 자동 음성 인식은(는) 프로그램이 음성 언어를 자동으로 받아쓰도록 만드는 문제를 말합니다. 흔히 음성 → 텍스트로도 알려져 있습니다.
우리의 목표는 보통 모델이 다음을 최소화하도록 하는 것입니다 단어 오류율 (WER) 음성 입력을 받아 쓸 때의 핵심 지표입니다. 다시 말해, 음성이 담긴 오디오 파일(예: WAV 파일)이 주어졌을 때, 이를 가능한 한 오류가 적은 대응 텍스트로 어떻게 변환할 수 있을까요?
다음과 같은 접근 방식 전통적인 음성 인식 생성적 접근 방식을 취하여, 음성 샘플을 평가하기 위해 실제로 음성이 생성되는 전 과정을 모델링합니다. 우리는 다음과 같은 단계에서 시작합니다 언어 모델 생성된 단어들의 가장 그럴듯한 순서를 포괄하는 모델(예: n‑gram 모델)을 포함하고, 그리고 이를 결합하여 발음 모델 그 단어 순서의 각 단어에 대한 발음 표와 같은 자료를 포함하고, 또한 음향 모델 그 발음을 오디오 파형으로 변환하는 모델(예: 가우시안 혼합 모델).
그다음 어떤 음성 입력을 받으면, 우리 모델의 생성적 파이프라인에 따라 해당 오디오가 생성될 가능성이 가장 높은 텍스트 시퀀스를 찾는 것이 목표입니다. 요약하면, 전통적인 음성 인식에서는 다음을 모델링하려고 합니다 Pr(audio|transcript)*Pr(transcript), 그리고 가능한 전사들 중에서 이의 argmax를 취합니다.
시간이 지나면서 신경망은 발전하여, 전통적인 음성 인식 모델의 각 구성 요��를 더 나은 성능과 더 높은 일반화 가능성을 지닌 신경망 모델로 대체할 수 있게 되었습니다. 문제는 이러한 각 신경망 모델이 서로 다른 과제에 대해 개별적으로 학습되어야 한다는 점입니다. 그리고 파이프라인의 어느 모델에서든 발생한 오류가 전체 예측을 흐트러뜨릴 수 있습니다.
따라서, 우리는 다음과 같은 점에서 매력을 확인할 수 있습니다 엔드 투 엔드 ASR 아키텍처: 오디오 입력을 받아 텍스트 출력만을 생성하는 판별적 모델로, 아키텍처의 모든 구성 요소가 동일한 목표를 향해 함께 학습됩니다. 이 모델의 인코더는 음성 특성을 추출하는 음향 모델에 해당하며, 이렇게 얻은 특성은 텍스트를 출력하는 디코더로 직접 전달됩니다. 필요하다면 예측 품질을 높이기 위해 언어 모델을 통합할 수도 있습니다.
이렇게 하면 엔드 투 엔드 ASR 전체 모델을 한 번에 학습할 수 있어, 훨씬 다루기 쉬운 파이프라인이 됩니다!
오늘 우리가 수행할 작업을 위해, 우리는 사용할 것입니다 NVIDIA의 NeMo 엔드 투 엔드 ASR 아키텍처를 학습하기 위한 툴킷과 사용 Weights & Biases 성능 지표를 기록하기 위해.
시작해 봅시다!
환경 설정
이제 자동 음성 인식과 이 글에서 사용할 도구들에 대해 어느 정도 이해했으니, 첫 단계로 코드를 실행할 수 있도록 환경을 설정하겠습니다.
먼저 인스턴스를 실행하기 위해 사용할 것은 AWS 그리고 해당 머신에서 NeMo가 실행되도록 필요한 종속 항목들을 설치합니다. 우리가 사용할 것은 NVIDIA NGC 그리고 여기에서 Jupyter 노트북을 확인하세요.
- AWS 인스턴스에 SSH로 접속하기 그리고 포트 8888을 포워딩하세요.
- NGC에서 NVIDIA NeMo Docker 컨테이너 가져오기 docker pull nvcr.io/nvidia/nemo:1.6.1.
- Docker 컨테이너 실행하기 명령어 사용 docker run --runtime=nvidia -it --rm --shm-size=16g -p 8888:8888 --ulimit memlock=-1 --ulimit stack=67108864 -v $(pwd):/notebooks nvcr.io/nvidia/nemo:1.6.1.
- Docker 컨테이너 내부에 있을 때, Jupyter Notebook 실행하기 - jupyter notebook --port 8888.
- 이동하기 localhost:8888 로 Jupyter Notebook에 접속하기.
- 다운로드한 파일 업로드하기 files.zip 3단계에서 다운로드한 파일의 압축을 해제하여 ASR W&B 노트북에 접근하세요.
이제 끝입니다! 6단계만 거치면 NeMo 코드 실행 준비가 완료된 AWS 인스턴스에 접속해 있을 것입니다.
소개: 엔드투엔드 자동 음성 인식
소개에서 설명했듯이, 엔드투엔드 ASR 모델을 구축할 수 있는 역량이 훨씬 더 도움이 됩니다.
엔드투엔드 모델에서는 직접 학습하고자 합니다 Pr(transcript|audio) 원본 오디오로부터 전사를 예측하기 위해서입니다. 시간에 따라 연속되는 오디오 데이터가 문자 시퀀스에 대응하는 순차적 정보이므로, RNN은 당연한 선택입니다.
하지만 지금 당장 해결해야 할 중요한 문제가 있습니다. 입력 시퀀스(오디오 타임스텝 수)와 원하는 출력(전사 길이)의 길이가 서로 다를 때, 오디오 데이터의 각 타임스텝을 올바른 출력 문자에 어떻게 대응시킬 수 있을까요?
어텐션 기반 시퀀스-투-시퀀스
널리 사용되는 해결책은 어텐션을 갖춘 시퀀스-투-시퀀스 모델을 사용하는 것입니다.
일반적인 ASR용 seq2seq 모델은 오디오 시퀀스를 타임스텝 단위로 처리하는 양방향 RNN 인코더와, 그 출력을 어텐션 기반 디코더에 전달하는 구조로 이루어집니다. 디코더의 각 예측은 전체 인코딩된 입력의 일부에 어텐션을 적용하고, 이전에 출력된 토큰들을 함께 고려하여 이루어집니다.
디코더의 출력은 워드피스, 음소, 문자 등 어떤 형태도 될 수 있으며, 예측이 입력의 타임스텝에 직접 연결되지 않기 때문에 종료 토큰이 나오거나 지정된 최대 출력 길이에 도달할 때까지 토큰을 하나씩 계속 생성하면 됩니다. 이렇게 하면 오디오 정렬을 신경 쓸 필요가 없고, 예측된 전사는 디코더가 내놓은 출력들의 시퀀스가 됩니다!
데이터 살펴보기
익숙하지 않다면, AN4는 사람들이 주소, 이름, 전화번호 등을 한 글자 또는 한 숫자씩 말한 음성 녹음과 그에 해당하는 전사로 구성된 데이터셋입니다. AN4는 비교적 작아서 학습 발화 948개, 테스트 발화 130개로 이루어져 있어 학습이 빠르고 짧은 튜토리얼에 적합한 훌륭한 데이터셋입니다.
좋아요, 이제 데이터셋을 다운로드하고 준비해 봅시다! 발화 음성은 다음과 같은 형식으로 제공됩니다 .sph 형식의 파일이므로, 이를 다음 형식으로 변환해야 합니다 .wav 처리를 위해 다음을 실행하세요:
# Download the datasetprint("******")if not os.path.exists(data_dir + '/an4_sphere.tar.gz'):an4_url = 'http://www.speech.cs.cmu.edu/databases/an4/an4_sphere.tar.gz'an4_path = wget.download(an4_url, data_dir)print(f"Dataset downloaded at: {an4_path}")else:print(f"Tarfile already exists at {data_dir + '/an4_sphere.tar.gz'}")an4_path = data_dir + '/an4_sphere.tar.gz'# convert .sph to .wavif not os.path.exists(data_dir + '/an4/'):# Untar and convert .sph to .wav (using sox)tar = tarfile.open(an4_path)tar.extractall(path=data_dir)sph_list = glob.glob(data_dir + '/an4/**/*.sph', recursive=True)for sph_path in tqdm(sph_list):wav_path = sph_path[:-4] + '.wav'cmd = ["sox", sph_path, wav_path]subprocess.run(cmd)
이 시점에서, 이제 다음 이름의 폴더가 있어야 합니다 an4 포함하는 etc/an4_train.transcription, etc/an4_test.transcription, 오디오 파일은 wav/an4_clstk 그리고 wav/an4test_clstk, 우리가 사용할 필요가 없는 다른 몇몇 파일들과 함께.
샘플 오디오부터 시작해서 파형을 그려 봅시다. 예를 들어, 파일 cen2-mgah-b.wav 는 한 남성이 알파벳 “G L E N N”을 한 글자씩 말한 2.6초 길이의 오디오 녹음입니다. 이를 확인하기 위해 파일을 듣고 파형을 그려 보겠습니다.
import librosaimport IPython.display as ipd# Load and listen to the audio fileexample_file = data_dir + '/an4/wav/an4_clstk/mgah/cen2-mgah-b.wav'audio, sample_rate = librosa.load(example_file)ipd.Audio(example_file, rate=sample_rate)_ = librosa.display.waveplot(audio)

각 발음된 글자가 서로 다른 “모양”을 가지고 있다는 것을 어느 정도 구분할 수 있습니다. 마지막 두 덩어리가 비교적 비슷해 보이는 것도 흥미로운데, 둘 다 “N”이기 때문에 당연한 일입니다.
스펙트로그램과 멜 스펙트로그램
하지만 오디오 정보는 시간에 따른 주파수의 맥락에서 더 유용하므로, 다음을 적용하면 더 나은 표현을 얻을 수 있습니다. 푸리에 변환 오디오 신호에 적용하면 더 유용한 표현을 얻을 수 있습니다. 즉, a 스펙트로그램, 이는 파일의 전체 길이에 걸쳐 신호의 각 주파수(즉, 음높이)에 대한 에너지 수준(즉, 진폭 또는 “크기”)을 나타낸 표현입니다.
이제 샘플의 스펙트로그램이 어떻게 보이는지 살펴보겠습니다.

이번에도 각 글자가 발음되는 모습을 확인할 수 있으며, 마지막의 두 덩어리는 “N”에 해당해 서로 꽤 비슷해 보입니다. 하지만 이러한 모양과 색을 어떻게 해석해야 할까요?
앞서 본 파형 그래프와 마찬가지로, x축에는 시간이 흐르는 모습이 표시됩니다(전체 2.6 s 오디오). 하지만 이제 y축은 서로 다른 주파수(로그 스케일)를 나타내며, 플롯의 색상은 특정 시점에서 해당 주파수의 세기를 보여줍니다.
아직 끝난 것은 아닙니다. 더 유용할 수 있는 한 가지를 더 조정해 볼 수 있습니다. 바로 멜 스펙트로그램 일반적인 스펙트로그램 대신 사용합니다. 이는 선형(또는 로그) 스케일에서 주파수 스케일을 다음으로 바꾸는 간단한 변경입니다. 멜 스케일, 이는 청취자가 서로 간의 간격이 같다고 판단하는 음높이를 기준으로 한 지각적 스케일입니다.
즉, 사람이 지각하는 방식에 더 맞추기 위해 주파수를 변환하는 것입니다. 예를 들어 2000Hz에서 3000Hz로 +1000Hz 변화는 9000Hz에서 10000Hz로의 +1000Hz 변화보다 더 크게 들리므로, mel 스케일은 동일한 간격이 사람의 귀에는 동일한 차이로 들리도록 이를 정규화합니다.
# Plot the mel spectrogram of our samplemel_spec = librosa.feature.melspectrogram(audio, sr=sample_rate)mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)librosa.display.specshow(mel_spec_db, x_axis='time', y_axis='mel')plt.colorbar()plt.title('Mel Spectrogram');

합성곱 기반 ASR 모델
이제 우리가 구축할 모델과 그 매개변수를 어떻게 지정할지 살펴보겠습니다.
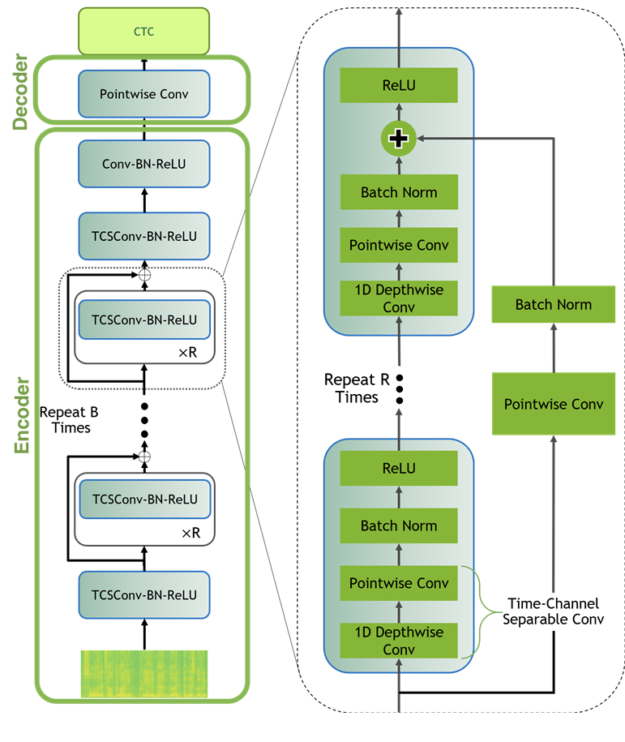
Jasper 모델
우리는 작은 모델을 학습할 것입니다 Jasper(Just Another SPeech Recognizer) 모델 처음부터(예: 무작위로 초기화). 간단히 말해, Jasper 아키텍처는 1D 합성곱을 사용하는 반복 블록 구조로 구성됩니다. In a Jasper_KxR 모델, R 서브 블록(1D 합성곱, 배치 정규화, ReLU, 드롭아웃으로 구성)을 하나의 블록으로 묶고, 이 블록을 반복합니다 K 횟수
또한 시작 부분에 하나의 추가 블록이 있고, 끝부분에는 몇 개의 추가 블록이 더 있으며, 이는 …와 무관합니다 K 그리고 R, 그리고 우리는 CTC 손실을 사용합니다.
QuartzNet 모델
QuartzNet은 시간-채널 분리형 1D 합성곱을 사용하는 것이 핵심 차이인 Jasper의 개선된 변형입니다. 이를 통해 비슷한 정확도를 유지하면서도 가중치 수를 크게 줄일 수 있습니다.
Jasper/QuartzNet 모델은 다음과 같은 구조입니다(사진은 QuartzNet 모델).
NeMo를 활용한 자동 음성 인식
이제 ASR가 무엇인지, 오디오 데이터가 어떤 형태인지 이해했으니, NeMo를 사용해 ASR을 시작해 봅시다!
우리는 …을 사용할 것입니다 Neural Modules(NeMo) 도구 모음 이 부분을 진행하려면, 아직 하지 않았다면 NeMo와 그 종속 항목들을 다운로드하여 설치해야 합니다. 그렇게 하려면 다음의 안내를 따라 주세요 GitHub 페이지, 또는 …에서 문서.
NeMo를 사용하면 데이터 레이어, 중간 레이어, 다양한 손실 함수 등 모델의 구성 요소(모듈)를 손쉽게 연결할 수 있으며, 각 부분의 구현 세부 사항이나 모듈 간 연결에 대해 지나치게 신경 쓰지 않아도 됩니다. 또한 NeMo에는 학습에 필요한 사용자 데이터와 하이퍼파라미터만 제공하면 되는 완전한 모델들도 포함되어 있습니다.
# NeMo's "core" packageimport nemo# NeMo's ASR collection - this collections contains complete ASR models and# building blocks (modules) for ASRimport nemo.collections.asr as nemo_asr# This line will download pre-trained QuartzNet15x5 model from NVIDIA's NGC cloud and instantiate it for youquartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="QuartzNet15x5Base-En")#
바로 사용 가능한 모델 활용
NeMo의 ASR 컬렉션에는 학습과 평가에 사용할 수 있는 다양한 구성 요소와 완전한 모델까지 포함되어 있습니다. 또한 여러 모델은 사전 학습된 가중치를 함께 제공합니다. 이제 완전한 모델을 인스턴스화해 봅시다 QuartzNet15x5 모델.
다음으로, 필사할 파일들의 경로를 목록에 추가한 뒤 모델에 전달하면 됩니다. 이 방법은 비교적 짧은(25초 미만) 파일에 대해 동작합니다.
files = ['./an4/wav/an4_clstk/mgah/cen2-mgah-b.wav']for fname, transcription in zip(files, quartznet.transcribe(paths2audio_files=files)):print(f"Audio in {fname} was recognized as: {transcription}")
생각보다 간단하죠! 하지만 실제로는 자신의 데이터로 모델을 미세 조정하거나 아예 처음부터 학습해야 하는 상황이 많습니다. 예를 들어, 이 바로 사용 가능한 모델은 스페인어에는 당연히 맞지 않고, 전화 음성에도 성능이 떨어질 가능성이 큽니다. 따라서 직접 수집한 데이터가 있다면, 반드시 그 데이터로 미세 조정하거나 처음부터 학습해 보세요!
처음부터 학습하기
처음부터 학습하려면 학습 데이터를 올바른 형식으로 준비하고 모델의 아키텍처를 지정해야 합니다.
처음부터 데이터 매니페스트 만들기
모델을 처음부터 학습하려면, 데이터를 올바른 형식으로 준비해야 합니다. 따라서 학습 및 평가 데이터에 대한 매니페스트를 생성해야 하며, 이 매니페스트에는 오디오 파일의 메타데이터가 포함됩니다. NeMo 데이터 세트는 표준화된 매니페스트 형식을 사용하며, 각 줄은 하나의 오디오 샘플에 대응합니다. 따라서 매니페스트��� 줄 수는 해당 매니페스트가 나타내는 샘플 수와 같습니다. 각 줄에는 오디오 파일의 경로, 해당 전사(또는 전사 파일의 경로), 그리고 오디오 샘플의 길이가 포함되어야 합니다.
NeMo와 호환되는 매니페스트의 한 줄 예시는 다음과 같습니다:
{"audio_filepath": "path/to/audio.wav", "duration": 3.45, "text": "this is a nemo tutorial"}
다음을 사용해 학습 및 평가용 매니페스트를 만들 수 있습니다 an4/etc/an4_train.transcription 그리고 an4/etc/an4_test.transcription전사와 해당 오디오 파일 ID가 포함된 줄이 있는:
...<s> P I T T S B U R G H </s> (cen5-fash-b)<s> TWO SIX EIGHT FOUR FOUR ONE EIGHT </s> (cen7-fash-b)...
# Function to build a manifestdef build_manifest(transcripts_path, manifest_path, wav_path):audio_paths=[]; durations=[]; texts=[]with open(transcripts_path, 'r') as fin:with open(manifest_path, 'w') as fout:for line in fin:# Lines look like this:# <s> transcript </s> (fileID)transcript = line[: line.find('(')-1].lower()transcript = transcript.replace('<s>', '').replace('</s>', '')transcript = transcript.strip()file_id = line[line.find('(')+1 : -2] # e.g. "cen4-fash-b"audio_path = os.path.join(data_dir, wav_path,file_id[file_id.find('-')+1 : file_id.rfind('-')],file_id + '.wav')duration = librosa.core.get_duration(filename=audio_path)audio_paths.append(audio_path)durations.append(duration)texts.append(transcript)# Write the metadata to the manifestmetadata = {"audio_filepath": audio_path,"duration": duration,"text": transcript}json.dump(metadata, fout)fout.write('\n')return audio_paths, durations, texts# Building Manifeststrain_transcripts = data_dir + '/an4/etc/an4_train.transcription'train_manifest = data_dir + '/an4/train_manifest.json'train_audio_paths, train_durations, train_texts = build_manifest(train_transcripts, train_manifest, 'an4/wav/an4_clstk')test_transcripts = data_dir + '/an4/etc/an4_test.transcription'test_manifest = data_dir + '/an4/test_manifest.json'test_audio_paths, test_durations, test_texts = build_manifest(test_transcripts, test_manifest, 'an4/wav/an4test_clstk')
이제 학습 및 테스트용 매니페스트가 준비되었으니, 어떻게 생겼는지 확인해 봅시다!
처음 다섯 행의 train_manifest 다음과 같이 보입니다. (다음 명령어로 직접 쉽게 확인할 수 있습니다 - !head {train_manifest} -n5)
{"audio_filepath": "./an4/wav/an4_clstk/fash/an251-fash-b.wav", "duration": 1.0, "text": "yes"}{"audio_filepath": "./an4/wav/an4_clstk/fash/an253-fash-b.wav", "duration": 0.7, "text": "go"}{"audio_filepath": "./an4/wav/an4_clstk/fash/an254-fash-b.wav", "duration": 0.9, "text": "yes"}{"audio_filepath": "./an4/wav/an4_clstk/fash/an255-fash-b.wav", "duration": 2.6, "text": "u m n y h six"}{"audio_filepath": "./an4/wav/an4_clstk/fash/cen1-fash-b.wav", "duration": 3.5, "text": "h i n i c h"}
Weights & Biases 테이블에 데이터 로깅하기
이제 데이터 매니페스트가 준비되었으니, 데이터를 직접 다뤄보면 더 도움이 되지 않을까요? 데이터 경로, 오디오, 스펙트로그램, 멜 스펙트로그램을 한곳에서 모두 볼 수 있으면 좋겠죠?
우선, 우리는 모든 것을 살펴보고 audio_filepath 그리고 저장합니다 스펙트로그램 그리고 멜 스펙트로그램 오디오 파일용 이미지. 다음으로, 우리는 wandb.Table 기록하기 위해 파일 이름, 오디오 파일, 텍스트(우리 모델의 정답), 스펙트로그램 이미지 및 멜 스펙트로그램 이미지.
이를 수행할 수 있는 코드는 아래에서 확인할 수 있습니다:
def save_spectogram_as_img(audio_path, datadir, plt_type='spec'):filename = os.path.basename(audio_path)out_path = os.path.join(datadir, filename.replace('.wav', '.png'))audio, sample_rate = librosa.load(audio_path)if plt_type=='spec':spec = np.abs(librosa.stft(audio))spec_db = librosa.amplitude_to_db(spec, ref=np.max)else:mel_spec = librosa.feature.melspectrogram(audio, sr=sample_rate)mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)fig = plt.Figure()ax = fig.add_subplot()ax.set_axis_off()librosa.display.specshow(spec_db if plt_type=='spec' else mel_spec_db,y_axis='log' if plt_type=='spec' else 'mel',x_axis='time', ax=ax)fig.savefig(out_path)# convert audio file to spectogram and mel spectogram imagesif not os.path.exists('./an4/melspectogram_images/'):for path in tqdm(train_audio_paths):save_mel_spectogram_as_img(path, datadir='./an4/images/')save_spectogram_as_img(path, datadir='./an4/melspectogram_images/', plt_type='mel')# log filename, playable audio, duration of audio, transcript, spectogram and mel spectogram to W&B for ease of referenceif LOG_WANDB:# create W&B Tablewandb.init(project="ASR")audio_table = wandb.Table(columns=['Filename', 'Audio File', 'Duration', 'Transcript', 'Spectogram', 'Mel-Spectogram'])for path, duration, text in zip(train_audio_paths, train_durations, train_texts):filename = os.path.basename(path)img_fn = filename.replace('.wav', '.png')spec_pth = os.path.join('./an4/images', img_fn)melspec_pth = os.path.join('./an4/melspectogram_images', img_fn)audio_table.add_data(filename, wandb.Audio(path), duration, text, wandb.Image(spec_pth), wandb.Image(melspec_pth))wandb.log({"Train Data": audio_table})wandb.finish();
위 코드를 실행하면 아래와 같은 Weights & Biases 테이블이 생성됩니다:
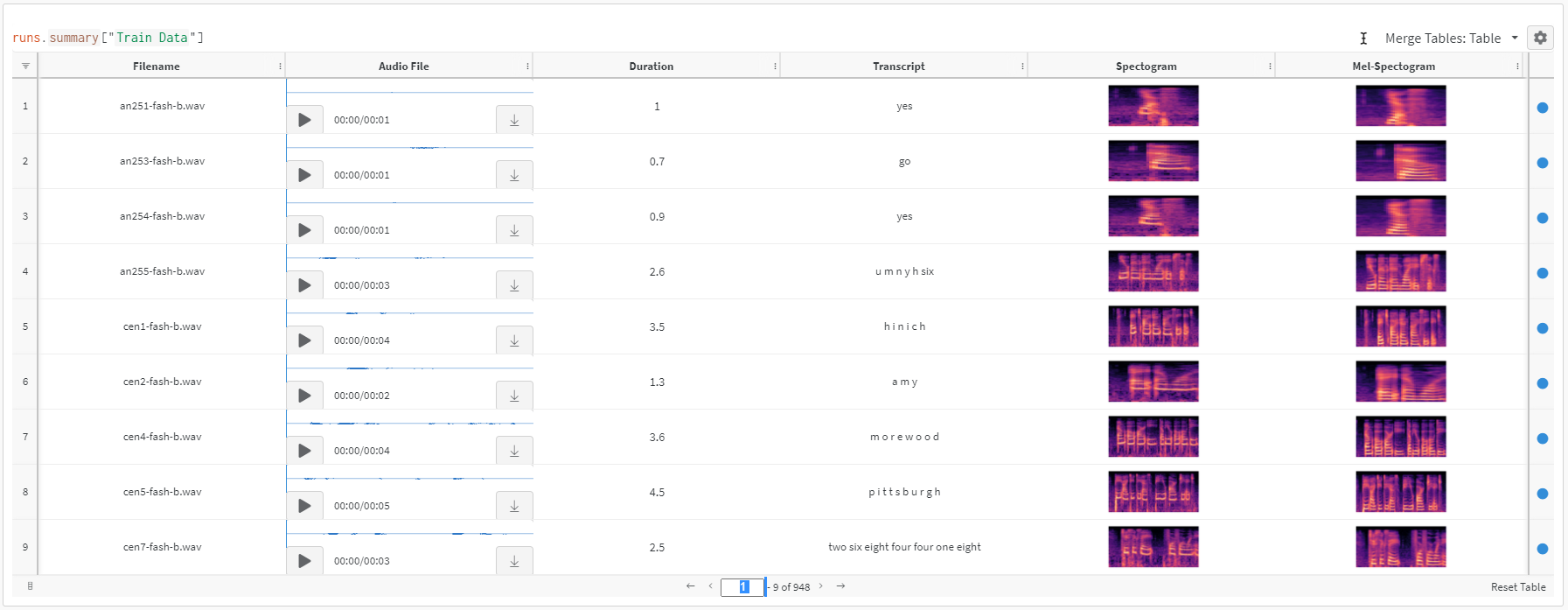
보시다시피, 다음을 사용하면 데이터셋을 훨씬 쉽게 탐색할 수 있습니다 Weights & Biases 모든 정보를 한곳에 모아 둔 테이블입니다. 오디오를 재생하고 전사도 확인할 수 있습니다.
좋습니다! 이제 우리가 직접 데이터셋을 만들었고 데이터를 아주 간단하게 탐색할 수 있는 방법도 마련했으니, 다음 단계로 넘어가겠습니다.
YAML 구성 파일로 모델 지정하기
이 튜토리얼에서는, 우리는 …을(를) 구축할 것입니다 Jasper_4x1 모델, 와 함께 K=4 단일 블록R=1) 서브 블록과 a 그리디 CTC 디코더, 다음 위치의 구성으로 ./configs/config.yaml.
이 구성 파일을 열어 보면, 모델의 아키텍처를 설명하는 model 섹션이 있습니다. 모델에는 다음과 같이 라벨이 지정된 항목이 포함됩니다 encoder, 다음 필드를 포함해 jasper 여러 항목이 포함된 목록을 담고 있습니다. 이 목록의 각 항목은 우리 모델의 하나의 블록을 지정하며, 대략 다음과 같은 형태입니다:
- filters: 128repeat: 1kernel: [11]stride: [2]dilation: [1]dropout: 0.2residual: falseseparable: truese: truese_context_size: -1
목록의 첫 번째 항목은 Jasper 아키텍처 다이어그램에서 첫 번째 블록에 해당하며, 이는 다음과 무관하게 항상 나타납니다 K 그리고 R다음으로, 다음에 해당하는 네 개의 항목이 있습니다 K=4 블록이며, 각각은 repeat: 1 우리가 사용하고 있으므로 R=1이후에는 CTC 손실 직전에 Jasper 모델의 끝부분에 나타나는 블록 두 개에 해당하는 항목이 이어집니다.
파일 상단에는 학습을 어떻게 처리할지 지정하는 항목들도 있습니다 (train_ds) 및 검증 (validation_ds) 데이터.
이와 같은 YAML 구성 파일을 사용하면 아키텍처의 구성을 빠르고 사람이 읽기 쉬운 형태로 파악할 수 있으며, 코드를 수정하지 않고도 모델과 실행 설정을 손쉽게 교체할 수 있습니다.
위의 파라미터를 살펴보기는 정말 어렵습니다. 특히 팀 동료와 파라미터와 결과를 공유하기가 더욱 어렵습니다. 아래에서는 사용하는 방법이 얼마나 쉬운지 살펴보겠습니다. Weights & Biases 와의 통합 PyTorch Lightning 또한 Weights & Biases는 결과, 설정, 테이블을 한곳에 모두 저장해 주기 때문에 결과를 재현할 때 매우 편리합니다!
PyTorch Lightning 및 Weights & Biases 통합으로 학습하기
NeMo 모델과 모듈은 torch.nn.Module이 예상되는 모든 PyTorch 코드에서 사용할 수 있습니다.
그러나 NeMo의 모델은 다음을 기반으로 합니다 PyTorch Lightning의 LightningModule이며, 혼합 정밀도와 분산 학습을 매우 쉽게 사용할 수 있으므로 학습과 파인튜닝에는 Lightning 사용을 권장합니다. 그럼 시작해 봅시다. GPU에서 50 에포크 동안 학습할 Trainer 인스턴스를 생성하겠습니다.
import pytorch_lightning as pltrainer = pl.Trainer(gpus=1, max_epochs=50)
알고 계셨나요? Weights & Biases 이미 다음과 같은 인기 있는 프레임워크에 통합되어 있습니다 PyTorch Lightning? 이 단계에서는 그냥 사용할 수도 있습니다 WandbLogger 학습하는 동안의 모든 진행 상황을 Weights & Biases에 기록하기 위해서입니다!
import pytorch_lightning as plfrom pytorch_lightning.loggers import WandbLogger# initialize W&B logger and specify project name to store results towandb_logger = WandbLogger(project="ASR", log_model='all')# set config params for W&B experimentfor k,v in params.items():wandb_logger.experiment.config[k]=v# initialize trainer with W&B loggertrainer = pl.Trainer(gpus=1, max_epochs=10, logger=wandb_logger)
이것은 실험을 매우 쉽게 복제할 수 있게 해 주기 때문에 아주 좋습니다.
다음으로, 이전 섹션의 config.yaml 파일을 기반으로 ASR 모델을 인스턴스화합니다. 이 단계에서는 학습 및 검증 매니페스트의 위치도 모델에 지정해 줍니다.
# Update train and test data pathparams['model']['train_ds']['manifest_filepath'] = train_manifestparams['model']['validation_ds']['manifest_filepath'] = test_manifest# initialize modelfirst_asr_model = nemo_asr.models.EncDecCTCModel(cfg=DictConfig(params['model']), trainer=trainer)
이제 한 줄만으로 학습을 시작할 수 있습니다!
# Start training - this will automatically store results to Weights and Biasestrainer.fit(first_asr_model)wandb.finish();
좋습니다! 모델용 전체 학습 파이프라인을 구성했고, 10에폭 동안 학습을 완료했습니다.
Weights & Biases: Sweeps를 사용한 하이퍼파라미터 튜닝
또한 일부 하이퍼파라미터를 튜닝하고 싶을 수도 있습니다. 아래에서는 가능한 모든 파라미터 중에서 작은 부분집합만 골라 보여 드립니다 params, 예를 들어 lr, epoch 그리고 dropout 하이퍼파라미터 튜닝을 보여 주기 위해 W&B Sweeps.
문서에서 설명하듯, W&B 스위프를 사용하면 많은 이점이 있습니다:
- 빠른 설정: 몇 줄의 코드만으로 바로 시작할 수 있습니다. 수십 대의 머신에서 스위프를 실행할 수 있으며, 노트북에서 스위프를 시작하는 것만큼이나 쉽게 할 수 있습니다.
- 투명: 우리가 사용하는 모든 알고리즘을 인용하며, 코드는 오픈 소스입니다.
- 강력함: 우리의 스위프는 완전히 사용자 정의와 구성이 가능합니다.
이 ASR 예제에 스위프를 추가하는 것은 정말 간단합니다. 먼저 아래와 같이 스위프 설정을 정의합니다:
sweep_config = {"method": "random", # Random search"metric": { # We want to minimize `val_loss`"name": "val_loss","goal": "minimize"},"parameters": {"lr": {# log uniform distribution between exp(min) and exp(max)"distribution": "log_uniform","min": -9.21, # exp(-9.21) = 1e-4"max": -4.61 # exp(-4.61) = 1e-2},"epoch": {"distribution": "int_uniform","min": 3,"max": 10},"dropout": {"distribution": "uniform","min": 0,"max": 0.25}}}
다음으로, 우리는 a를 정의합니다 sweep_iteration 아래와 같은 함수입니다. 핵심 차이점은 이제 이들의 값이 다음에서 가져온다는 점입니다. wandb.config 고정된 값으로 설정하는 대신에.
예시,
params['model']['optim']['lr'] = wandb.config.lrparams['model']['encoder']['jasper'][-1]['dropout'] = wandb.config.dropout
이 값들은 스위프마다 달라지므로, 우리는 이 값을 다음에서 가져옵니다 wandb.config 아래와 같이.
def sweep_iteration():# load configconfig_path = './configs/config.yaml'yaml = YAML(typ='safe')with open(config_path) as f:params = yaml.load(f)# set up W&B loggerwandb.init() # required to have access to `wandb.config`wandb_logger = WandbLogger(log_model='all') # log final model# setup dataparams['model']['train_ds']['manifest_filepath'] = train_manifestparams['model']['validation_ds']['manifest_filepath'] = test_manifest# setup sweep paramparams['model']['optim']['lr'] = wandb.config.lrparams['model']['encoder']['jasper'][-1]['dropout'] = wandb.config.dropouttrainer = pl.Trainer(gpus=1, max_epochs=wandb.config.epoch, logger=wandb_logger)# setup model - note how we refer to sweep parameters with wandb.configmodel = nemo_asr.models.EncDecCTCModel(cfg=DictConfig(params['model']), trainer=trainer)# traintrainer.fit(model)
마지막으로, wandb 스위프를 생성하고 다음을 전달합니다 wandb_config 그다음에는 에이전트를 생성해 여러 번의 실행을 수행하고, 스위프의 “method”에 따라 다양한 하이퍼파라미터 조합을 선택하여 각 파라미터 값에 대한 val_loss를 비교합니다.
sweep_id = wandb.sweep(sweep_config, project="ASR")wandb.agent(sweep_id, function=sweep_iteration)
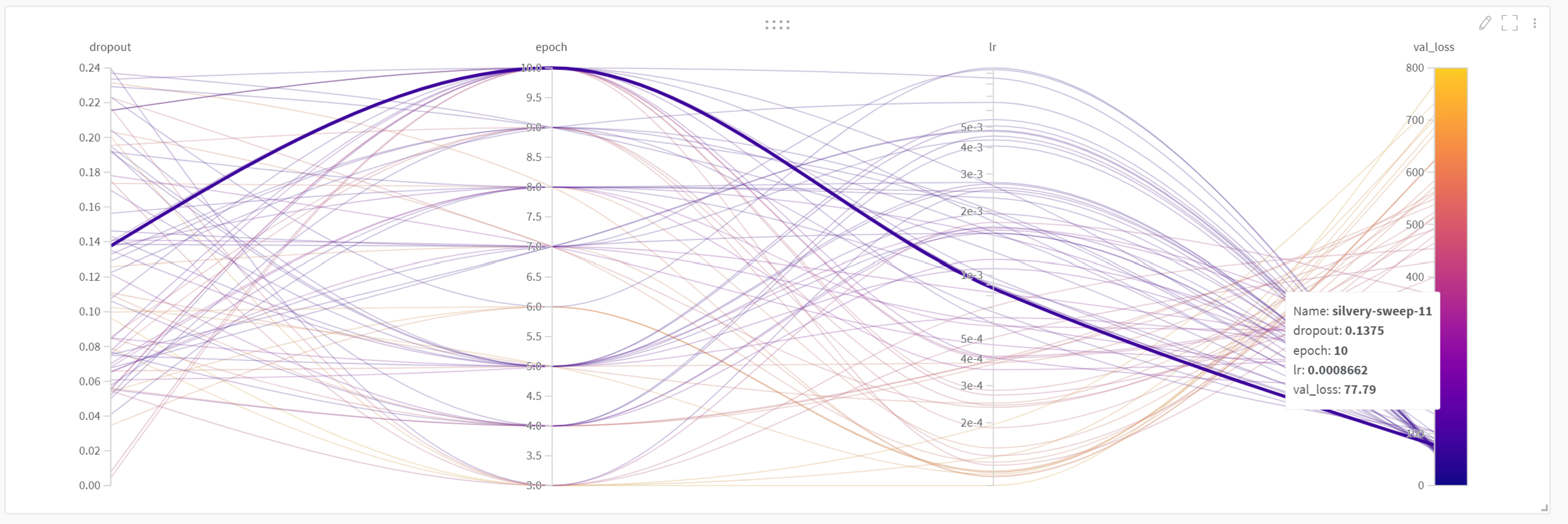
이 스위프 실행 결과를 확인할 수 있습니다 여기보시다시피 아래와 같은 멋진 플롯이 생성되며, 이를 통해 다양한 하이퍼파라미터가 검증 손실 값에 어떻게 영향을 미치는지 훨씬 쉽게 확인할 수 있습니다.
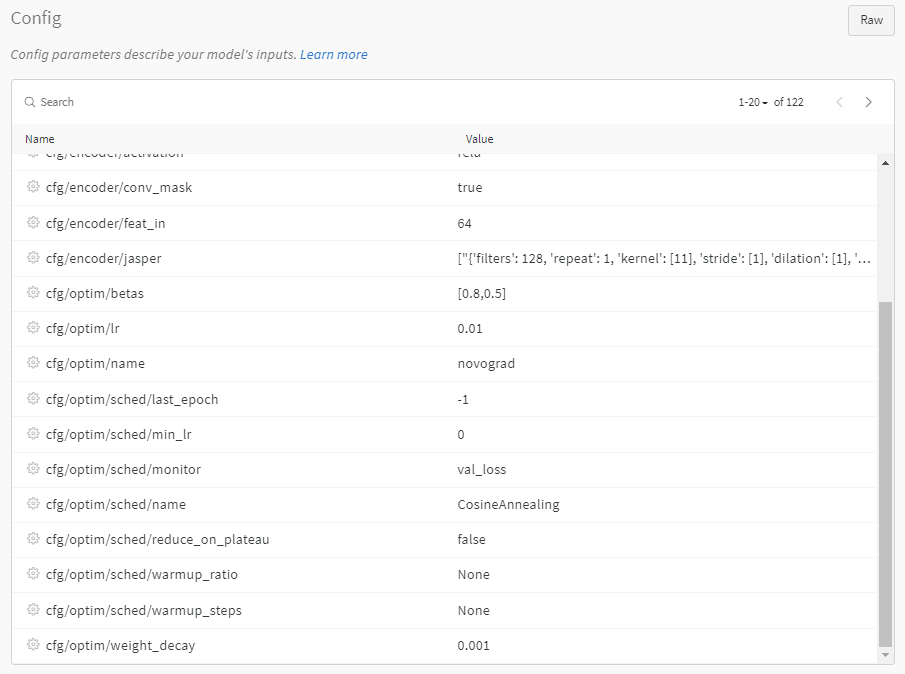
Weights & Biases: 성능 지표 기록
이 대시보드는 아래와 같습니다:
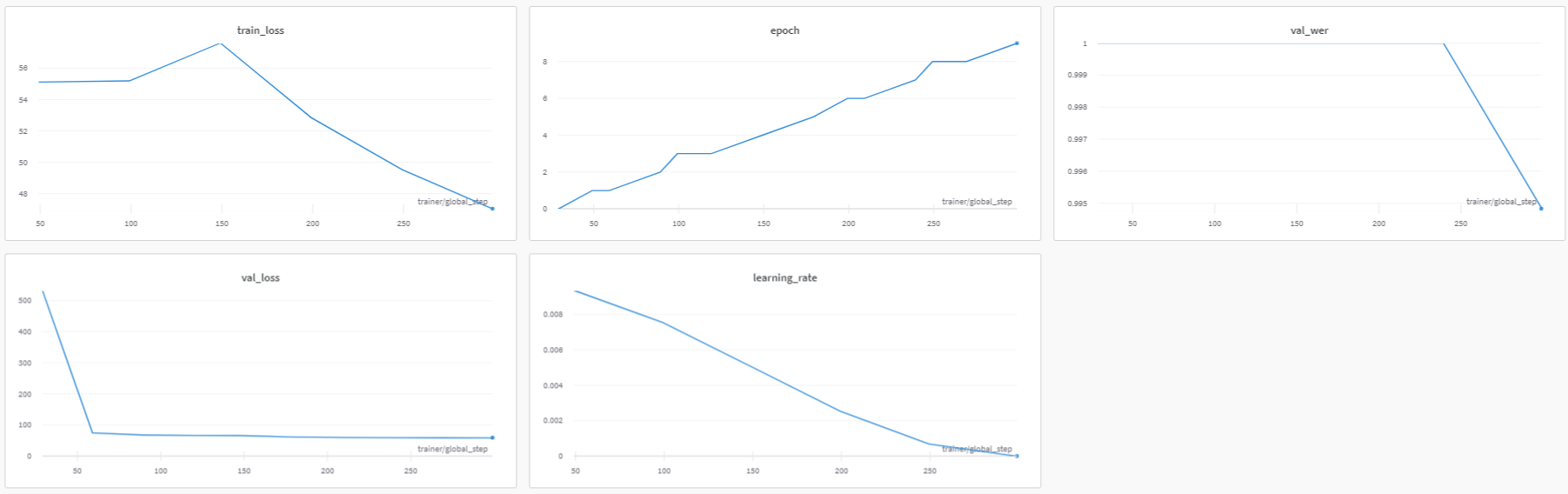
위의 대시보드에서 볼 수 있듯이, 학습률과 학습 손실, 검증 손실 지표를 매우 쉽게 확인할 수 있으며, 이는 지표를 기록하지 않았다면 불가능했을 것입니다. Weights & Biases.
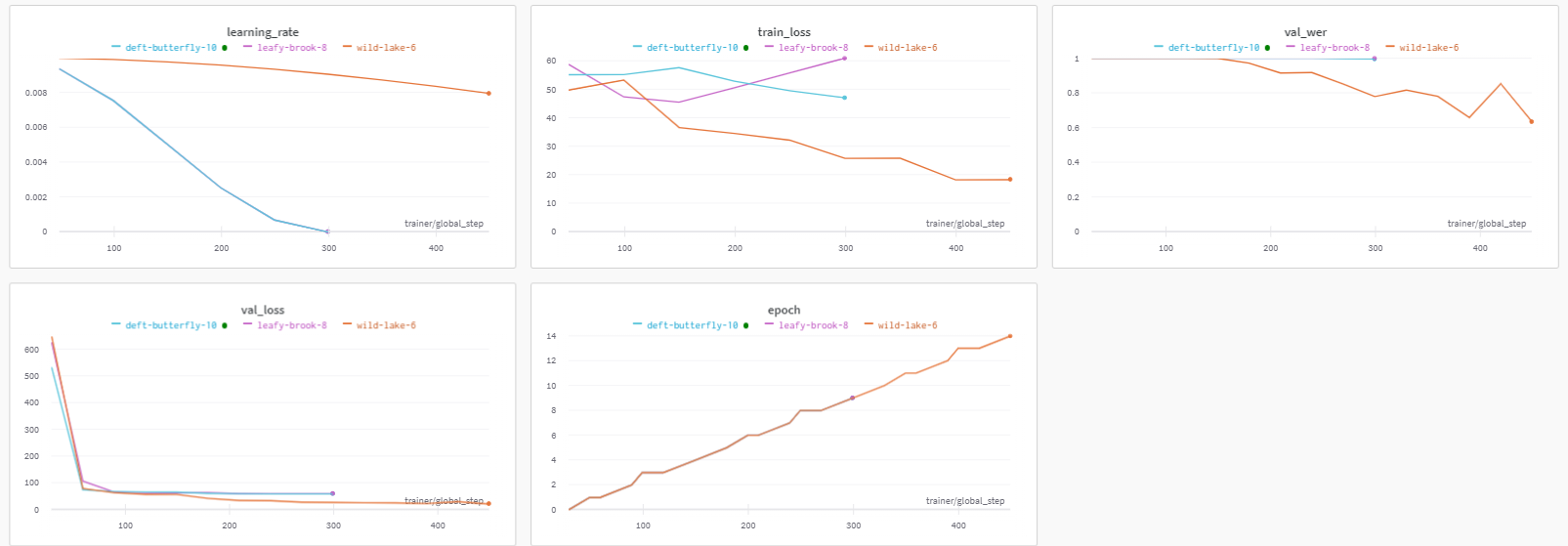
Weights & Biases: 로그 구성
Weights & Biases에 결과를 저장하면 구성 파라미터도 함께 보관된다는 이점이 있습니다. 아래와 같이 파라미터를 훨씬 쉽고 간단하게 확인할 수 있습니다.
Weights & Biases: 실험 비교
Weights & Biases: 모델 아티팩트
나중에 로드할 수 있도록 이 모델 체크포인트를 저장하고 싶다면(예: 파인튜닝이나 학습 재개용), 다음을 호출하면 됩니다. first_asr_model.save_to(<checkpoint_path>)그런 다음 가중치를 복원하려면, 구성으로 모델을 다시 빌드하면 됩니다(이를 호출한다고 가정해 보겠습니다. first_asr_model_continued 이번에는) 그리고 호출합니다 first_asr_model_continued.restore_from(<checkpoint_path>).
진행 상황과 모델 가중치를 빠르게 저장하는 또 다른 방법은 다음을 사용하는 것입니다 Weights & Biases 아티팩트입니다. 우리가 전달했으므로 log_model='all' 로 WandbLoggerWeights & Biases는 이미 각 에포크가 끝날 때마다 모든 모델 가중치를 저장했습니다.

이 모델 가중치들은 정말 간단하게 사용할 수 있습니다! 해야 할 일은 아래 두 줄의 코드를 실행하는 것뿐입니다:
artifact = run.use_artifact('user_name/project_name/new_artifact:v1', type='my_dataset')artifact_dir = artifact.download()
보시다시피, 이는 모델을 다음 위치로 다운로드합니다 './artifacts/model-2kr60tp1:v9'
추론
NeMo의 ASR 모델로 추론을 실행하는 방법을 간단히 살펴보겠습니다.
먼저, EncDecCTCModel 및 그 하위 클래스에는 유용한 transcribe 오디오 파일의 전사를 간단히 얻는 데 사용할 수 있는 메서드입니다. 성능 향상을 위해 batch_size 인수도 제공합니다.
if LOG_WANDB:preds = quartznet.transcribe(paths2audio_files=test_audio_paths, batch_size=16)pred_table = wandb.Table(columns=['FileName', 'Audio', 'Prediction', 'Ground Truth'])for path, gt, pred in zip(test_audio_paths, test_texts, preds):pred_table.add_data(os.path.basename(path), wandb.Audio(path), pred, gt)run = wandb.init(project='ASR')wandb.log({'Prediction Table': pred_table})wandb.finish();
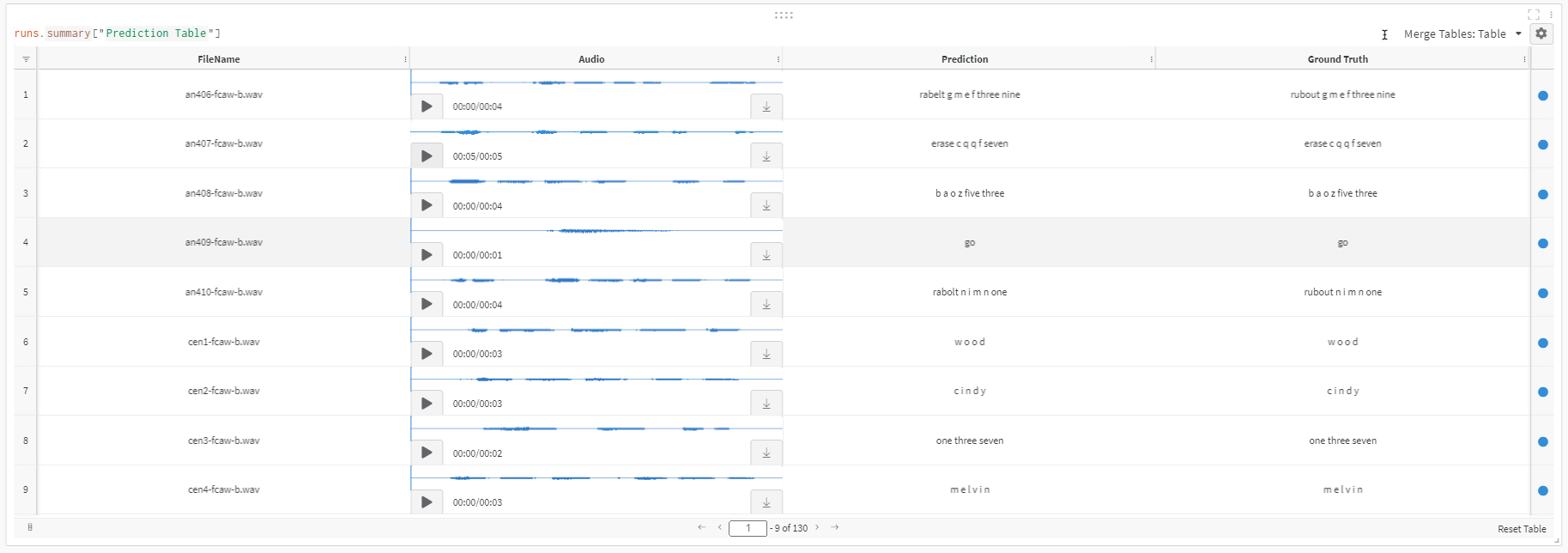
또한 아래에는 순수 PyTorch로 작성한 간단한 추론 루프 예시가 있습니다. 예측값과 정답(reference) 사이의 단어 오류율(WER) 지표를 계산하는 방법도 함께 보여줍니다.
import copynew_opt = copy.deepcopy(params['model']['optim'])new_opt['lr'] = 0.001first_asr_model.setup_optimization(optim_config=DictConfig(new_opt))# Bigger batch-size = bigger throughputparams['model']['validation_ds']['batch_size'] = 16# Setup the test data loader and make sure the model is on GPUfirst_asr_model.setup_test_data(test_data_config=params['model']['validation_ds'])first_asr_model.cuda()# We will be computing Word Error Rate (WER) metric between our hypothesis and predictions.# WER is computed as numerator/denominator.# We'll gather all the test batches' numerators and denominators.wer_nums = []wer_denoms = []# Loop over all test batches.# Iterating over the model's `test_dataloader` will give us:# (audio_signal, audio_signal_length, transcript_tokens, transcript_length)# See the AudioToCharDataset for more details.for test_batch in first_asr_model.test_dataloader():test_batch = [x.cuda() for x in test_batch]targets = test_batch[2]targets_lengths = test_batch[3]log_probs, encoded_len, greedy_predictions = first_asr_model(input_signal=test_batch[0], input_signal_length=test_batch[1])# Notice the model has a helper object to compute WERfirst_asr_model._wer.update(greedy_predictions, targets, targets_lengths)_, wer_num, wer_denom = first_asr_model._wer.compute()first_asr_model._wer.reset()wer_nums.append(wer_num.detach().cpu().numpy())wer_denoms.append(wer_denom.detach().cpu().numpy())# Release tensors from GPU memorydel test_batch, log_probs, targets, targets_lengths, encoded_len, greedy_predictions# We need to sum all numerators and denominators first. Then divide.print(f"WER = {sum(wer_nums)/sum(wer_denoms)}")
이 WER은 그다지 인상적이지 않으며 충분히 개선할 여지가 있습니다. 더 오래 학습하면(예: 100 에폭) 더 나은 수치를 얻을 수 있습니다. 추가 개선 방법은 다음 섹션을 확인하세요.
모델 개선
NeMo에서 자체 ASR 모델을 만들기 위한 모든 준비는 이미 갖추고 있습니다. 다만, 원한다면 활용할 수 있는 몇 가지 추가 요령이 있습니다. 이 섹션에서는 ASR 모델을 개선할 수 있는 몇 가지 가능성을 간략히 살펴보겠습니다.
데이터 증강
훈련 세트의 규모를 늘릴 수 있는 ASR 데이터 증강 기법이 여러 가지 존재합니다.
예를 들어, 특정 주파수 구간을 0으로 만드는 “frequency masking” 또는 특정 시간 구간을 0으로 만드는 “time masking”을 통해 스펙트로그램에 데이터 증강을 수행할 수 있습니다. 스펙오그먼트또는 스펙트로그램에서 직사각형 영역을 0으로 만들 수도 있으며, 이는 컷아웃NeMo에서는 다음의 세 가지를 모두 단순히 다음을 추가하는 것만으로 수행할 수 있습니다. SpectrogramAugmentation 신경 모듈
전이 학습
전이 학습은 한 과제에서 학습한 모델의 지식을 다른 과제에 활용해 성능을 높이는 중요한 머신 러닝 기법입니다. 파인튜닝은 전이 학습을 수행하는 기법 중 하나입니다. 많은 최신 성과의 핵심 구성 요소로, 기본 모델을 먼저 방대한 학습 데이터가 있는 과제에서 사전 학습한 뒤, 학습 데이터가 상대적으로 적거나 매우 부족한 다른 관심 과제에 대해 파인튜닝하는 방식을 사용합니다.
ASR에서는 여러 상황에서 파인튜닝을 수행할 수 있습니다. 예를 들어, 특정 도메인(의료, 금융 등)이나 억양이 있는 음성에 대한 모델 성능을 향상시키고자 할 때가 그렇습니다. 심지어 한 언어에서 다른 언어로 전이 학습을 적용할 수도 있습니다! 구체적인 사례는 이 논문을 참고하세요.
NeMo를 사용한 전이 학습은 간단합니다. 클라우드에서 가져온 모델을 AN4 데이터로 파인튜닝하는 방법을 보여드리겠습니다. (참고: 이는 예시용 데모입니다.) 아울러, 진행하면서 모델의 어휘 집합도 변경해 보며 그 방법을 함께 설명하겠습니다.
# Check what kind of vocabulary/alphabet the model has right nowprint(quartznet.decoder.vocabulary)# Let's add "!" symbol there. Note that you can (and should!) change the vocabulary# entirely when fine-tuning using a different language.quartznet.change_vocabulary(new_vocabulary=[' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n','o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', "'", "!"])>> [' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', "'"][NeMo I 2022-01-19 15:31:05 ctc_models:348] Changed decoder to output to [' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', "'", '!'] vocabulary.
이 작업을 마치면 디코더는 완전히 바뀌지만, 가중치 대부분이 있는 인코더는 그대로 유지됩니다. 이제 AN4 데이터셋으로 이 모델을 2 에폭 동안 파인튜닝해 봅시다.
# Use the smaller learning rate we set beforequartznet.setup_optimization(optim_config=DictConfig(new_opt))# Point to the data we'll use for fine-tuning as the training setquartznet.setup_training_data(train_data_config=params['model']['train_ds'])# Point to the new validation data for fine-tuningquartznet.setup_validation_data(val_data_config=params['model']['validation_ds'])# And now we can create a PyTorch Lightning trainer and call `fit` again.trainer = pl.Trainer(gpus=[1], max_epochs=2)
추가로 읽어보기/시청하기:
오늘은 여기까지입니다! 튜토리얼에서 다룬 주제들을 더 자세히 알아보고 싶다면, 아래 자료들을 참고해 보세요:
Add a comment