ResNet 이해하기: PyTorch와 함께 살펴보는 잔차 네트워크 심층 분석
이 글에서는 ResNet이 어떻게, 그리고 왜 작동하는지 이해하고 직접 구축하는 방법을 알아봅니다. PyTorch와 PyTorch Image Models (TIMM)을 사용해 ResNet 모델을 구현합니다. 이 글은 AI 번역본입니다. 오역이 있을 경우 댓글로 알려 주세요.
Created on September 12|Last edited on September 12
Comment
딥러닝은 컴퓨터 비전 분야에 혁신을 가져와, 기계가 인간에 가까운 정확도로 이미지를 인식하고 분류할 수 있게 했습니다. 이 분야에서 가장 영향력 있는 아키텍처 중 하나는 잔차 신경망, 널리 알려진 ResNet.
카이밍 허 등 연구진이 2015년 논문에서 처음 소개한 “이미지 인식을 위한 딥 잔차 학습이후 ResNet은 딥러닝 커뮤니티의 표준이 되었으며, 많은 이미지 분류 작업에서 출발점으로 자주 사용됩니다.
이 글에서는 ResNet의 동작 원리를 살펴보고, 왜 그렇게 효과적인지 이해한 뒤, 다음을 사용해 ResNet 모델을 구현해 보겠습니다. PyTorch 그리고 PyTorch Image Models (TIMM).
이 글은 이론과 실습 구현을 함께 다룹니다. Python과 PyTorch를 사용할 예정이므로, 이에 대한 기본적인 이해가 있으면 좋습니다. 또한 다음을 사용할 것입니다. TIMM, PyTorch용 사전 학습 모델과 학습 스크립트를 제공하는 라이브러리입니다.
💡
ResNet을 영상으로 학습하는 것을 선호하신다면, 제가 만든 ResNet 논문 읽기 영상을 참고하셔도 좋습니다:
이번 글에서 다룰 내용은 다음과 같습니다:
목차
딥 네트워크의 문제점ResNet의 등장PyTorch와 TIMM으로 ResNet 구현하기순수 PyTorch로 처음부터 ResNet 만들기PyTorch에서 기본 빌딩 블록 학습하기데이터셋 전처리모델 생성네트워크 학습네트워크 평가결론
시작해 봅시다!
딥 네트워크의 문제점
ResNet에 들어가기 전에, 먼저 이들이 해결하고자 한 문제를 이해해 봅시다. 일반적으로 신경망의 깊이를 늘리면 성능이 향상되기를 기대합니다. 하지만 2015년에 ResNet 논문 저자들은 흥미로운 현상을 관찰했습니다. BatchNorm을 사용했음에도 불구하고, 더 많은 레이어를 사용한 네트워크가 더 적은 레이어를 사용한 네트워크보다 성능이 떨어진 것입니다. 게다가 두 모델 사이에는 깊이를 제외하고는 다른 차이가 없었습니다.
흥미로운 점은 이 차이가 검증 세트뿐 아니라 학습 세트에서도 관찰되었다는 것입니다. 즉, 이것은 일반화 문제에 그치지 않고 학습 자체의 문제였습니다.
원문에서:
의외로 이러한 성능 저하는 과적합 때문이 아니라, 이미 충분히 깊은 모델에 층을 더 추가하면 학습 오류가 오히려 커지기 때문입니다. 이는 [이전에 보고된 바] 있으며, 우리의 실험으로 철저히 검증되었습니다.
학술 논문에서는 이 과정을 다소 난해하게 설명하지만, 개념 자체는 아주 간단합니다. 먼저 충분히 잘 학습된 20층 신경망을 두고, 아무 일도 하지 않는 36개 층을 추가합니다(예를 들어 선형 층일 수 있습니다). 그러면 20층 신경망과 완전히 동일하게 동작하는 56층 네트워크가 만들어지며, 이는 항상 학습 가능해야 하는 깊은 네트워크가 존재함을 증명합니다. 적어도 그에 못지않게 좋다 얕은 네트워크만큼이나. 하지만 이상하게도 확률적 경사 하강법(SGD)은 그런 해를 찾아내지 못하는 듯합니다.
이러한 성능 저하는 과적합 때문이 아니라 매우 깊은 네트워크를 최적화하기가 어렵다는 데서 비롯되었습니다. 이를 다음과 같이 부릅니다: 기울기 소실 문제

논문에서도 다음과 같이 설명합니다:
더 깊은 네트워크가 수렴하기 시작할 수 있게 되면 성능 저하 문제가 드러납니다. 네트워크의 깊이가 증가함에 따라 정확도가 포화 상태에 이르고(이는 그다지 놀랍지 않을 수 있습니다) 이후 급격히 떨어집니다. 의외로 이러한 성능 저하는 과적합 때문이 아니며, 이미 충분히 깊은 모델에 층을 더 추가하면 모델은 더 높은 학습 오류로 이어진다, 우리의 실험으로 검증되었습니다.
위 그림에서 볼 수 있듯이, 56층 네트워크는 테스트 오류가 더 높을 뿐만 아니라 학습 오류도 더 높습니다. 이는 성능 저하가 과적합 때문이 아니라 네트워크의 복잡성에서 비롯되었음을 의미합니다.
경사 기반 학습법과 역전파로 신경망을 학습할 때, 각 가중치는 매 훈련 반복마다 현재 가중치에 대한 오류 함수의 기울기에 비례하는 양만큼 업데이트됩니다.
문제는 어떤 경우에는 기울기가 극도로 작아져 가중치가 사실상 값이 변하지 못하게 된다는 점입니다.최악의 경우 신경망의 추가 학습이 완전히 중단될 수 있습니다.
역전파 알고리즘이 연쇄 법칙을 사용해 기울기를 계산할 때, n층 네트워크에서 “앞단” 층들의 기울기를 구하려면 이런 작은 수들을 n번 곱하게 됩니다. 그 결과 기울기(오류 신호)는 n에 비례해 지수적으로 감소하고, 앞단 층들은 매우 느리게 학습됩니다.
여기서 독자가 해볼 만한 좋은 실험은 위 그림을 복제해 보면서, 실제로 56층 모델이 20층 모델보다 더 나쁜 결과를 내는지 확인하는 것입니다. 그렇다면 35층에서는 차트가 어떻게 나올까요?
💡
ResNet의 등장
ResNet은 소실되는 기울기 문제를 해결하기 위해 새로운 아키텍처를 도입했습니다. ResNet의 핵심 아이디어는 이른바 아이덴티티 쇼트컷 연결 다음 그림과 같이 한 층 또는 여러 층을 건너뛰는 연결:

그림은 ResNet의 기본 블록을 보여줍니다. 여기서, 블록의 입력이며 학습해야 할 잔차 매핑을 나타냅니다. 연산 쇼트컷 연결과 원소별 덧셈으로 수행됩니다.
쇼트컷 연결(스킵 연결)의 아이디어는 모델이 일부 층을 건너뛰도록 하여 소실되는 기울기 문제를 완화합니다. 이러한 연결은 기울기가 초기 층까지 직접 역전파되도록 해 네트워크를 더 쉽게 최적화할 수 있게 합니다.
그 스킵 연결로 우리가 얻은 것은 무엇일까요? 핵심은, 현재 상태에서 그 추가된 36개 층이 항등 매핑, 하지만 그들은 매개변수, 즉 그것들은 학습 가능한그래서 36개의 층을 추가하더라도, 모델은 그 층들을 건너뛸 수 있으므로 새 모델은 최소한 20층짜리 모델만큼은 성능을 낼 수 있습니다. 이후 그 추가된 36개 층은 가장 유용해지도록 만드는 매개변수를 학습할 수 있습니다.
이제 ResNet의 기본 개념을 이해했으니, 먼저 TIMM을 사용해 ResNet을 구현하고, 이어서 PyTorch로 처음부터 직접 구현해 보겠습니다.
PyTorch와 TIMM으로 ResNet 구현하기
먼저 다음을 설치해야 합니다 timm 패키지입니다. pip으로 다음과 같이 설치할 수 있습니다:
bashCopy codepip install timm
다음으로 필요한 라이브러리를 임포트하겠습니다:
import torchimport timm
다음을 사용해 ResNet 모델을 생성할 수 있습니다 create_model 에서의 함수 timm여기서는 ResNet50 모델을 생성합니다:
model = timm.create_model('resnet50', pretrained=True)
그 pretrained=True 인자는 사전에 학습된 모델을 사용한다는 의미이며, 학습 데이터셋은 다음과 같습니다 ImageNet 데이터셋이를 통해 수백만 장의 이미지로 학습하며 이미 축적된 모델의 지식을 활용할 수 있습니다.
이제 이 모델을 사용해 예측을 수행하는 방법을 살펴보겠습니다. 먼저 입력으로 사용할 무작위 텐서를 하나 생성하겠습니다:
x = torch.randn(1, 3, 224, 224)
이 텐서는 이미지 배치를 나타냅니다. 차원은 다음과 같습니다: 배치에는 이미지 1장, 색상 채널 3개(빨강, 초록, 파랑), 높이와 너비는 각각 224픽셀입니다.
이 텐서를 모델에 통과시켜 출력을 얻을 수 있습니다:
output = model(x)
출력은 다음 형태의 텐서입니다 (1, 1000)으로, ImageNet 데이터셋의 1000개 클래스 각각에 속할 확률을 나타냅니다.
인사하세요. 방금 TIMM을 사용해 ResNet 모델을 구현했습니다.
순수 PyTorch로 처음부터 ResNet 만들기
이제 코드로 들어가 순수 PyTorch에서 ResNet을 처음부터 구현하는 방법을 살펴보겠습니다.
먼저 ResNet의 기본 구성 요소인 잔차 블록을 정의해 봅시다:
import torchfrom torch import nnclass ResidualBlock(nn.Module):def __init__(self, in_channels, out_channels, stride=1):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,stride=stride, padding=1, bias=False)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,stride=1, padding=1, bias=False)def forward(self, x):out = self.conv2(self.relu(self.conv1(x)))out += xout = self.relu(out)return out
위 코드에서 볼 수 있듯이, 그림을 완전히 따르고 있습니다. 여기서, 다음과 같이 정의됩니다 self.conv2(self.relu(self.conv1(x)))다음으로, 우리는 그냥 추가합니다 으로 다음과 같이 out += x마지막으로 ReLU를 한 번 더 적용한 뒤 출력을 반환합니다.
PyTorch에서 ResNet 블록을 처음부터 구현하는 데 필요한 것은 사실상 이것만으로 충분합니다!
하지만 위에서 살펴본 기본 형태의 ResNet 블록만으로는 전체 ResNet 아키텍처를 구현하기에 충분하지 않습니다. 실제 현업이나 라이브러리에서 resnet-34, resnet-50, resnet-101 같은 다양한 ResNet 변형을 보신 적이 있을 겁니다. 논문에 따르면, 이러한 ResNet 아키텍처 변형은 다음 그림과 같이 정의됩니다.
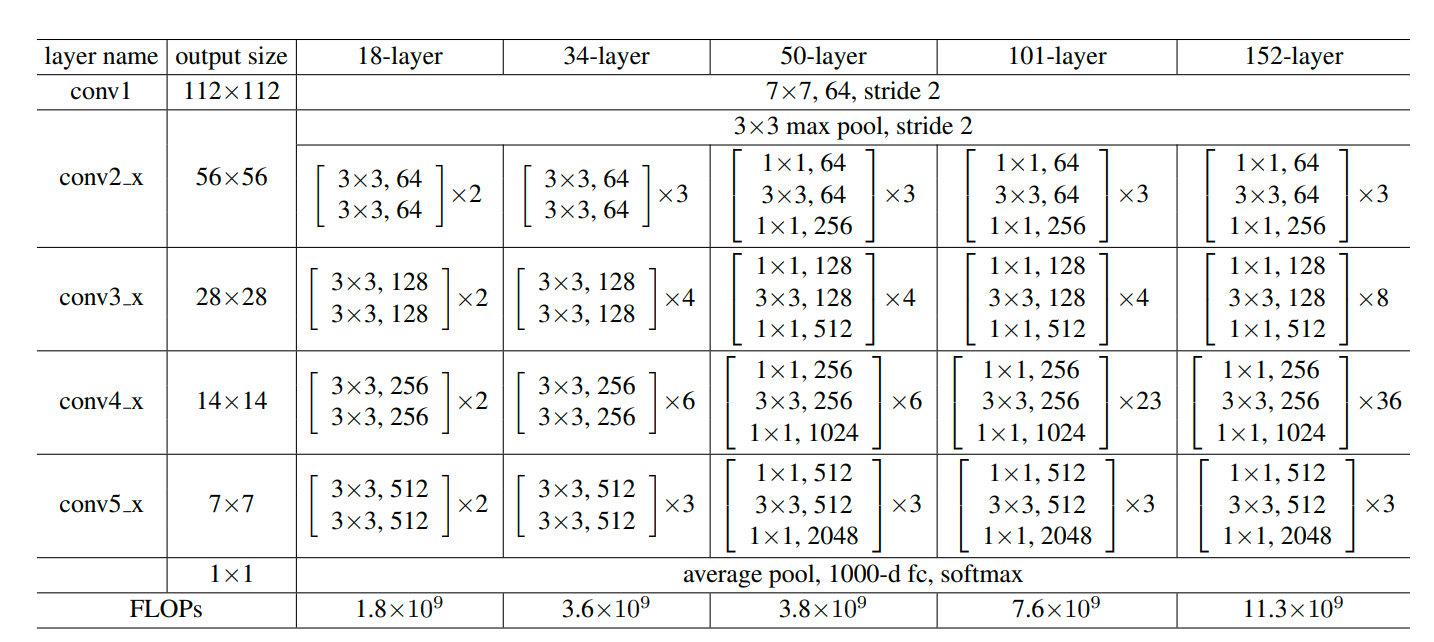
위의 아키텍처 정의에서 볼 수 있듯이, 출력 크기를 줄이는 동시에 채널 수를 64 → 128 → 256 → 512로 증가시킬 수 있어야 합니다. 따라서 기본 ResNet 블록 구현을 다음과 같이 업데이트합니다.
import torchfrom torch import nnclass ResidualBlock(nn.Module):def __init__(self, in_channels, out_channels, stride=1):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.shortcut = nn.Sequential()if stride != 1 or in_channels != out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(out_channels))def forward(self, x):out = self.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x)out = self.relu(out)return out
이 블록은 두 개의 합성곱 층으로 구성되며, 각 층 뒤에는 배치 정규화 층과 ReLU 활성화 함수가 이어집니다. 입력과 출력의 차원이 일치하지 않으면, 입력을 필요한 차원으로 변환하는 숏컷(스킵) 연결을 추가합니다.
이제 전체 ResNet 아키텍처를 정의할 수 있습니다. ResNet은 이러한 블록을 여러 개 쌓아 올려 구성합니다. 아래는 ResNet의 간단한 구현 예시입니다.
class ResNet(nn.Module):def __init__(self, block, num_blocks, num_classes=10):super(ResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)self.linear = nn.Linear(512, num_classes)def _make_layer(self, block, out_channels, num_blocks, stride):strides = [stride] + [1]*(num_blocks-1)layers = []for stride in strides:layers.append(block(self.in_channels, out_channels, stride))self.in_channels = out_channelsreturn nn.Sequential(*layers)def forward(self, x):out = self.relu(self.bn1(self.conv1(x)))out = self.layer1(out)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = out.view(out.size(0), -1)out = self.linear(out)return out
이 코드에서는 _make_layer 이 함수는 네트워크의 각 레이어를 생성하는 데 사용되며, 동일한 출력 크기를 갖는 여러 개의 잔차 블록으로 구성됩니다. 각 레이어의 첫 번째 블록(첫 번째 레이어는 예외)에는 stride를 2로 설정하여 출력의 공간 해상도를 절반으로 줄이므로, 효과적으로 다운샘플링 레이어 역할을 합니다.
그 forward 이 함수는 네트워크의 순전파 과정을 정의합니다. 입력은 각 레이어를 차례대로 통과한 뒤, 최종적으로 형태를 변환하여 완전연결층을 거쳐 출력이 생성됩니다.
이로써 PyTorch에서 ResNet의 완전한 구현을 마쳤습니다! 이 모델은 이미지 분류를 포함한 다양한 작업에 대해 학습할 수 있으며, 많은 벤치마크에서 최신 성능을 달성했습니다.
PyTorch에서 기본 빌딩 블록 학습하기
이제 기본 빌딩 블록과 전체 ResNet 아키텍처를 정의했으니, 모델을 학습해 보겠습니다. PyTorch 라이브러리를 사용하여 우리의 ResNet을 대상으로 학습을 진행하겠습니다. ImageNette 데이터셋.
데이터셋을 다운로드하려면 다음 명령을 실행하세요.
mkdir data && cd datawget https://s3.amazonaws.com/fast-ai-imageclas/imagenette2-160.tgztar -xvf imagenette2-160.tgz
이제 여러분은 …을 가지고 있어야 합니다 data 저장소에서 폴더 구조가 다음과 같은 디렉터리:
data/└── imagenette2-160├── train│ ├── n01440764│ ├── n02102040│ ├── n02979186│ ├── n03000684│ ├── n03028079│ ├── n03394916│ ├── n03417042│ ├── n03425413│ ├── n03445777│ └── n03888257└── val├── n01440764├── n02102040├── n02979186├── n03000684├── n03028079├── n03394916├── n03417042├── n03425413├── n03445777└── n03888257
데이터를 다운로드했으니, 이제 데이터셋을 전처리해 봅시다.
데이터셋 전처리
모델을 학습하기 전에 데이터를 불러오고 전처리해야 합니다. torchvision 라이브러리를 사용해 ImageNette 데이터셋을 로드하고 필요한 변환을 적용하겠습니다.
from torchvision import datasets, transforms# Define transformationstransform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# Load ImageNette datasettrainset = torchvision.datasets.ImageFolder(TRAIN_DATA_DIR, transform=transform)trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=4)testset= torchvision.datasets.ImageFolder(TEST_DATA_DIR, transform=transform)testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=4)
이제 데이터셋 준비가 끝났으니, 모델을 만들겠습니다.
모델 생성
resnet-34를 생성하고 다음과 같이 저장합시다 net.
import torch.optim as optim# Instantiate the networknet = ResNet(ResidualBlock, [3, 4, 6, 3])# Define loss function and optimizercriterion = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.001, momentum=0.9)# Move the network to GPU if availableif torch.cuda.is_available():net = net.cuda()
손실 함수와 옵티마이저도 생성합니다.
네트워크 학습
이제 네트워크를 학습할 수 있습니다. 학습 진행 상황은 W&B에 기록하겠습니다.
import wandb# Initialize wandbwandb.init(project="resnet-training")# Training loopfor epoch in range(10): # loop over the dataset multiple timesrunning_loss = 0.0for i, data in enumerate(trainloader, 0):# get the inputs; data is a list of [inputs, labels]inputs, labels = dataif torch.cuda.is_available():inputs = inputs.cuda()labels = labels.cuda()# zero the parameter gradientsoptimizer.zero_grad()# forward + backward + optimizeoutputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()if i % 2000 == 1999: # print every 2000 mini-batchesprint('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))running_loss = 0.0# Log the loss to wandbwandb.log({"loss": running_loss})print('Finished Training')
우리는 전체를 순회합니다 tranloader 그리고 전처리된 이미지를 ResNet-34 아키텍처에 전달해 모델 출력을 얻습니다. 다음으로 손실을 계산하고 역전파를 수행해 아키텍처의 파라미터를 업데이트합니다. 손실 값은 W&B에도 기록합니다.
네트워크 평가
네트워크 학습을 마친 뒤에는 테스트 세트에서 성능을 평가할 수 있습니다. 정확도는 W&B에도 기록합니다.
correct = 0total = 0with torch.no_grad():for data in testloader:images, labels = dataif torch.cuda.is_available():images = images.cuda()labels = labels.cuda()outputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the test images: %d %%' % (100 * correct / total))# Log the accuracy to wandbwandb.log({"accuracy": correct / total})
위 스크립트에서는 ResNet-34 아키텍처로부터 출력을 얻고, 예측 레이블도 생성합니다. 또한 다음과 같은 방법을 사용할 수도 있습니다 argmax 대신에 torch.max마지막으로, 우리의 정확도는 간단히 correct / total.
결론
이 글에서는 PyTorch를 사용해 ResNet 아키텍처를 처음부터 구현하고 학습하는 방법을 살펴보았습니다. ImageNette 데이터셋으로 모델을 학습해 양호한 정확도를 달성했으며, W&B를 통해 학습 진행 상황과 최종 정확도를 기록했습니다. 이는 ResNet의 강력함과 이미지 분류 작업에 어떻게 활용될 수 있는지를 잘 보여줍니다. 이제 이 지식을 바탕으로 다양한 구성과 데이터셋을 실험해 모델 성능을 더욱 향상시켜 보세요. 즐거운 학습 되세요!
���
Add a comment