Digging Into StyleGAN-NADA for CLIP-Guided Domain Adaptation
In this article, we take a deep dive into how StyleGAN-NADA achieved the task of CLIP-guided domain adaptation and explore how we can use the model itself.
Created on June 22|Last edited on January 23
Comment
The unprecedented ability of generative adversarial networks (GANs) to capture and model image distributions through a semantically-rich latent space have revolutionized countless fields, including image enhancement, editing, and recently even discriminative tasks such as classification and regression.
Typically, the scope of these models is restricted to domains where you can collect large sets of images. This requirement severely constrains their applicability. Indeed, in many cases, such as paintings by specific artists or imaginary scenes, there may not exist sufficient data to train a GAN. There may not even be any data at all. The question then:
Can a generative model be trained to produce images from a specific domain, guided only by a text prompt, without seeing any image? In other words: can an image generator be trained “blindly”?
This is the question the authors of the paper StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators attempt to answer. In this paper, the authors present a text-driven method that allows shifting a generative model to new domains, all without having to collect even a single image.
This is achieved by leveraging the semantic power of large-scale Contrastive-Language-Image-Pretraining (CLIP) models. The authors also show that through natural language prompts and a few minutes of training, the proposed method can adapt a generator across a multitude of domains characterized by diverse styles and shapes.
In this article, we take a deep dive into how StyleGAN-NADA achieved this monumental task and explore how we can use the model itself.
Here's what we'll be covering:
Table of Contents
Let’s Talk About the PrecursorsA Deep Dive Into StyleGAN-NADAResultsAdvantages and Limitations of StyleGAN-NADAConclusionSimilar Articles
Translating Photos to Sketches
1
Further training to turn these happy faces into sad ones
1
This article was written as a Weights & Biases Report which is a project management and collaboration tool for machine learning projects. Reports let you organize and embed visualizations, describe your findings, share updates with collaborators, and more. To know more about reports, check out Collaborative Reports.
💡
Let’s Talk About the Precursors
StyleGAN
In recent years, StyleGAN and its variants have established themselves as the state-of-the-art unconditional image generators. The StyleGAN generator consists of two main components:
- A mapping network converts a latent code , sampled from a Gaussian prior, to a vector in a learned latent space .
- These latent vectors are then fed into the synthesis network, to control feature (or convolutional kernel) statistics.
By traversing , or by mixing different codes at different network layers, prior works such as GANSpace and StyleCLIP have demonstrated fine-grained control over semantic properties in generated images. These latent-space editing operations, however, are typically limited to modifications that align with the domain of the initial training set.
StyleCLIP
In this recent work, the generative power of StyleGAN is combined with the semantic knowledge of CLIP to discover novel editing directions, using only a textual description of the desired change.
The authors of StyleCLIP outline three approaches for leveraging the semantic power of CLIP. The first two aim to minimize the CLIP-space distance between a generated image and some target text. They use direct latent code optimization or train an encoder (or mapper) to modify an input latent code. The third approach (adapted in the case of StyleGAN-NADA) uses CLIP to discover global directions of disentangled change in the latent space. The authors modify individual latent-code entries and determine which ones induce an image-space change that is co-linear with the direction between two textual descriptors (denoting the source and desired target) in CLIP-space.
Shortcomings of the Precursors
All these aforementioned approaches share the limitation common to latent space editing methods - the modifications they can apply are largely constrained to the domain of the pre-trained generator.
As such, they can allow for changes in hairstyle and expressions or even convert a wolf to a lion if the generator has seen both. But, importantly, they cannot convert a photo to a painting or produce cats when trained on dogs.
Enter StyleGAN-NADA.
A Deep Dive Into StyleGAN-NADA
The goal of domain adaptation is to shift a pre-trained generator from a given source domain to a new target domain, which in this case is described only through textual prompts, with no images. In the case of StyleGAN-NADA, the authors use only a pre-trained CLIP model as a source of supervision. The task is approached through two key questions:
- How can the semantic information encapsulated in CLIP be distilled in the best manner?
- How should the optimization process be regularized in order to avoid adversarial solutions and mode collapse?
Training Setup
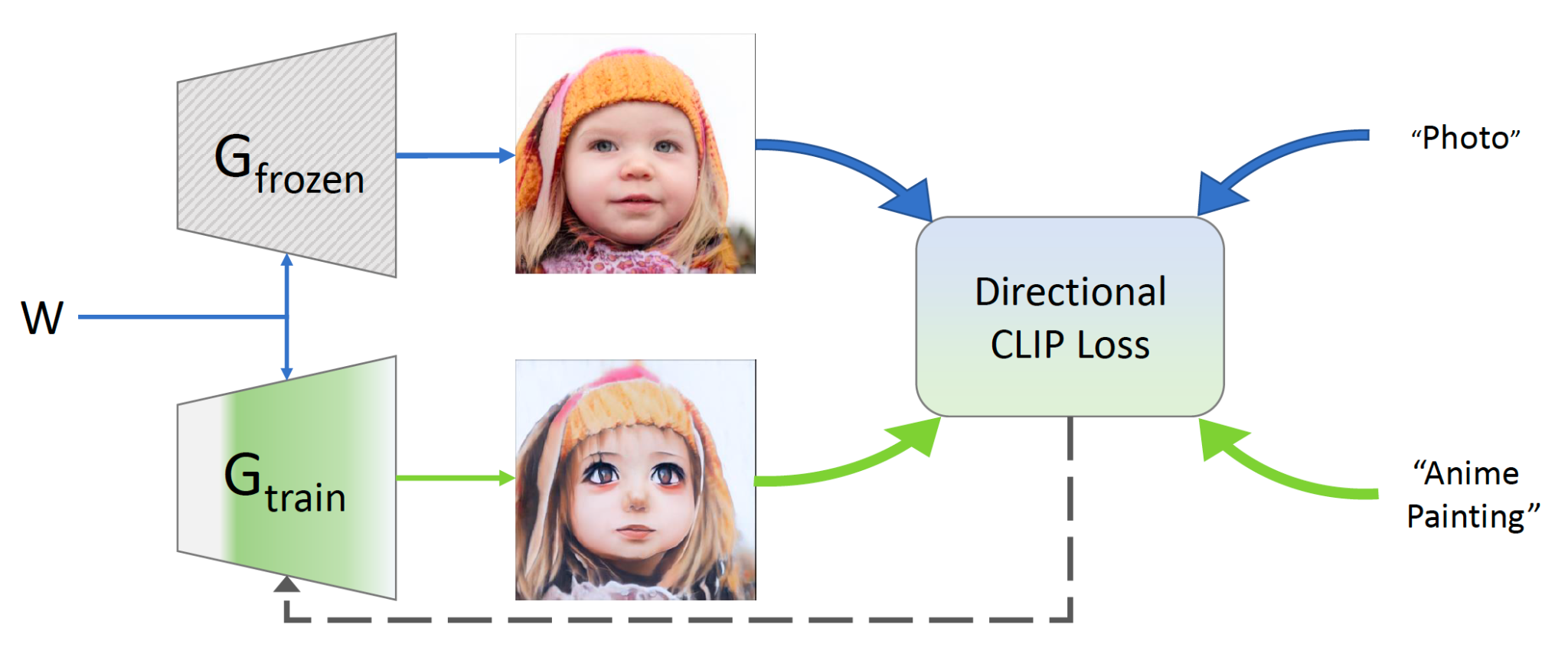
Source: Figure 2 from the paper
The authors initialize two generators and using the weights of a generator pre-trained on images from a source domain, such as FFHQ. remains fixed throughout the process while is modified through optimization and an iterative layer-freezing scheme. The process shifts the domain of according to a user-provided textual direction while maintaining a shared latent space.
CLIP-based Guidance
Global Loss
As mentioned before, the authors rely on a pre-trained CLIP model to serve as the sole source of supervision for the target domain. As a naive solution, the direct loss from StyleCLIP could be used. This loss function is given by...
...where:
- is the image generated by the latent code fed to the generator
- is the textual description of the target class
- is the CLIP-space cosine distance
- the loss is named global, as it does not depend on the initial image or domain.
However, the authors observe that there are some caveats to using this loss in practice for training the generator:
- The loss leads to adversarial solutions. In the absence of a fixed generator that favors solutions on the real-image manifold, optimization overcomes the classifier (CLIP) by adding pixel-level perturbations to the image.
- It sees no benefit in maintaining diversity. A mode-collapsed generator producing only one image may be the best minimizer for the distance to a given textual prompt.
Directional CLIP Loss
To address the issues posed by the global StyleCLIP loss, the authors draw inspiration from StyleCLIP’s global direction approach. Ideally, we want to identify the CLIP-space direction between the source and target domains. Then, the generator will be fine-tuned so that the images it produces differ from the source only along this direction.
- In order to do so, the authors first identify a cross-domain direction in CLIP-space by embedding a pair of textual prompts describing the source and target domains (e.g. “dog” and “cat”).
- Then, the CLIP-space direction between images produced by the generator before and after fine-tuning must be determined. The authors do this using a two-generator setup. They begin with a generator pre-trained on a single source domain (e.g. faces, dogs, churches, or cars), and clone it.
- One copy is kept frozen throughout the training process. Its role is to provide an image in the source domain for every latent code. This generator is referred to as .
- The second copy is trained. It is fine-tuned to produce images that, for any sampled code, differ from that of the source generator only along the textually described direction. This generator is referred to as .
- In order to maintain latent space alignment, the two generators share a single mapping network which is kept frozen throughout the process.
The direction loss is given by:
where...
- is the vector connecting the source and target space
- and are the source and target class texts
- is the vector connecting the images generated by both the generators and in the CLIP space
- and are CLIP’s image and text encoders
Such a loss overcomes the global loss’ shortcomings:
- It is adversely affected by mode-collapsed examples. If the target generator only creates a single image, the CLIPspace directions from all sources to this target image will be different. As such, they can’t all align with the textual direction.
- It is harder for the network to converge to adversarial solutions because it has to engineer perturbations that fool CLIP across an infinite set of different instances.

Illustration of CLIP-space directions in the proposed directional loss. The images generated by both generators are embedded into CLIP-space and demand that the vector connecting them (denoted by ) is parallel to the vector connecting the source and the target space (denoted by ). Source: Figure 3 from the paper.
Layer Freezing
For domain shifts that are predominantly texture-based, such as converting a photo to a sketch, the training scheme described above quickly converges before mode collapse, or overfitting occurs. However, more extensive shape modifications require longer training, which in turn destabilizes the network and leads to poor results.
In the case of StyleGAN, it has been shown that codes provided to different network layers influence different semantic attributes. Thus, by considering editing directions in the space, the latent space where each layer of StyleGAN can be provided with a different code – we can identify which layers are most strongly tied to a given change. Building on this intuition, the authors suggest a training scheme where at each iteration...
- the most relevant layers are selected
- a single training step is performed where only these relevant layers are optimized while freezing all others
In order the select the most relevant layers, the authors mandate the following two steps:
- Firstly,
- number of latent codes belonging to are randomly sampled
- These latent codes are then converted to by replicating the same code for each layer
- Secondly,
- number of the StyleCLIP latent-code optimization method, using the aforementioned global loss
- The layers for which the latent code changed most significantly are selected

An illustration of the two-step adaptive layer-freezing mechanism. Source: Figure 4 from the paper
Note that this process is inherently different from selecting layers according to gradient magnitudes during direct training. Latent-code optimization using a frozen generator tends to favor solutions which remain on the real-image manifold. By using it to select layers, we bias training towards similarly realistic changes. In contrast, direct training allows the model more easily drift towards unrealistic or adversarial solutions.
💡
Latent-Mapper Mining
For some shape changes, the authors found that the generator does not complete a full transformation. For example, when transforming dogs into cats, the fine-tuning process results in a new generator that outputs both cats, dogs, and an assortment of images that lie in between. To alleviate this, the authors note that the shifted generator now includes cats and dogs within its domain. We thus turn to in-domain latent-editing techniques, specifically StyleCLIP’s latent mapper, to map all latent codes into the cat-like region of the latent space.
Results
In this section, we showcase the wide range of out-of-domain adaptations enabled by the proposed method. These range from style and texture changes to shape modifications and from realistic to fantastical, including zero-shot prompts for which real data does not exist (e.g., Nicolas Cage dogs!). All these are achieved through a simple text-based interface and are typically trained within a few minutes.
👉 Try Training StyleGAN-NADA on Google Colab
Results of Models adapted from StyleGAN2-FFHQ
In this section, we demonstrate image synthesis using models adapted from StyleGAN2-FFHQ to a set of textually prescribed target domains. All images were sampled randomly, using truncation with .
Translating Photos to Mona Lisa Paintings
1
Transforming Humans to Werewolves
1
Transforming Humans to White Walkers from Game of Thrones
1
Transforming Humans to The Joker
1
Transforming Humans to Super Saiyans
1
Results of Models Adapted from StyleGAN2 and AFHQ-DOG
In this section, we demonstrate image synthesis using models adapted from AFHQ-DOG to a set of textually prescribed target domains. All images were sampled randomly, using truncation with .
Transforming Dogs to Nicolas Cage!!!
1
Transforming Dogs to Pigs
1
Transforming Churches to Huts
1
Transforming Churches to Cryengine Renderings of New York city
1
Transforming Cars to Ghost Cars
1
Transforming Chrome Wheels of Cars to TRON inspired wheels
1
Out-of-Domain Editing
In this section, we showcase out-of-domain editing through latent-code equivalence between the generators of StyleGAN-NADA. The image is inverted into the latent space of a StyleGAN2 FFHQ model using a pre-trained ReStyle encoder. The same latent code is then fed into the transformed generators in order to map the same identity to a novel domain.
Restyling an image of Yann LeCun
33
Advantages and Limitations of StyleGAN-NADA
Advantages
- The proposed method is trained blindly without any image, depending on a pre-trained CLIP model as the only source of supervision. By using CLIP to guide the training of a generator rather than an exploration of its latent space, we are able to affect large changes in both styles and shape far beyond the generator’s original domain.
- The ability to train generators without data leads to exciting new possibilities - from editing images in ways that are constrained almost only by the user’s creativity to synthesizing paired cross-domain data for downstream applications such as image-to-image translation.
Limitations
- By relying on CLIP, the proposed approach is limited to concepts that CLIP has observed.
- Textual guidance is also inherently limited by the ambiguity of natural language prompts. For example, when one describes a Raphael Painting, do they refer to the artistic style of the Renaissance painter, a portrait of Raphael's likeness, or an animated turtle bearing that name?
- The proposed method works particularly well for style and fine details, but it may struggle with large-scale attributes or geometry changes. Such restrictions are common also in few-shot approaches. The authors find that a good translation often requires a fairly similar pre-trained generator as a starting point.
Conclusion
In this article, we discuss the paper StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators in which the authors propose StyleGAN-NADA, a generative model that can be trained to produce images from a specific domain, guided only by a text prompt, blindly without seeing any image.
- The proposed method is trained blindly without any image, depending on a pre-trained CLIP model as the only source of supervision. By using CLIP to guide the training of a generator, rather than an exploration of its latent space, we are able to affect large changes in both style and shape, far beyond the generator’s original domain.
- We explored the training setup that consists of two generators initialized using the weights of a generator pre-trained on images from a source domain, such as FFHQ.
- We discussed StyleCLIP's global loss as a naive solution to train the generators for StyleGAN-NADA and its shortcomings. We also discussed the Directional CLIP loss proposed by the authors to train the generators and how it overcomes the aforementioned shortcomings.
- We further discussed the two-step adaptive layer-freezing mechanism in StyleGAN-NADA and how it resolves mode collapse or overfitting for domain shifts that are predominantly texture-based.
- We also discussed the Latent-mapper mining trick used by the authors to ensure the completion of a full transformation.
- We further showcased a wide range of out-of-domain adaptations that were enabled by the proposed method.
- We discussed and noted several advantages and disadvantages of the proposed approach.
- Finally, the authors hope this work can inspire others to continue exploring the world of textually-guided generation, particularly the astounding ability of CLIP to guide visual transformations.
"Perhaps, not too long in the future, our day-to-day efforts would no longer be constrained by data requirements - but only by our creativity." - The authors of the paper StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators.
Similar Articles
PoE-GAN: Generating Images from Multi-Modal Inputs
PoE-GAN is a recent, fascinating paper where the authors generate images from multiple inputs like text, style, segmentation, and sketch. We dig into the architecture, the underlying math, and of course, generate some images along the way.
EditGAN: High-Precision Semantic Image Editing
Robust and high-precision semantic image editing in real-time
Barbershop: Hair Transfer with GAN-Based Image Compositing Using Segmentation Masks
A novel GAN-based optimization method for photo-realistic hairstyle transfer
Modern Evolution Strategies for Creativity
In this article, we revisit evolutionary strategy algorithms for computational creativity and look at how they improve quality and efficiency in generating art.
Add a comment

Iterate on AI agents and models faster. Try Weights & Biases today.