Image Generation Based on Abstract Concepts Using CLIP + BigGAN
Is the state-of-the-art text-prompted image generation model aware of abstract, high-level concepts?
Created on March 11|Last edited on April 16
Comment
Introduction
OpenAI's CLIP model aims to learn generic visual concepts with natural language supervision. This is because standard computer vision models only work well on specific tasks, and require significant effort to adapt to a new task, hence have weak generalization capabilities. CLIP bridges this gap via learning directly from raw text about images at a web scale level (dataset of size 400M). Such dataset is also relatively easier to obtain in today's digital world with abundant image-caption pairs generated by internet users.
Note that CLIP does not directly optimize for the performance of a benchmark task (e.g. CIFAR), so as to keep its "zero-shot" capabilities for generalization. More interestingly, CLIP shows that scaling a simple pre-training task - which is to learn "which text matches with which image", is sufficient to achieve competitive zero-shot performance on many image classification datasets.
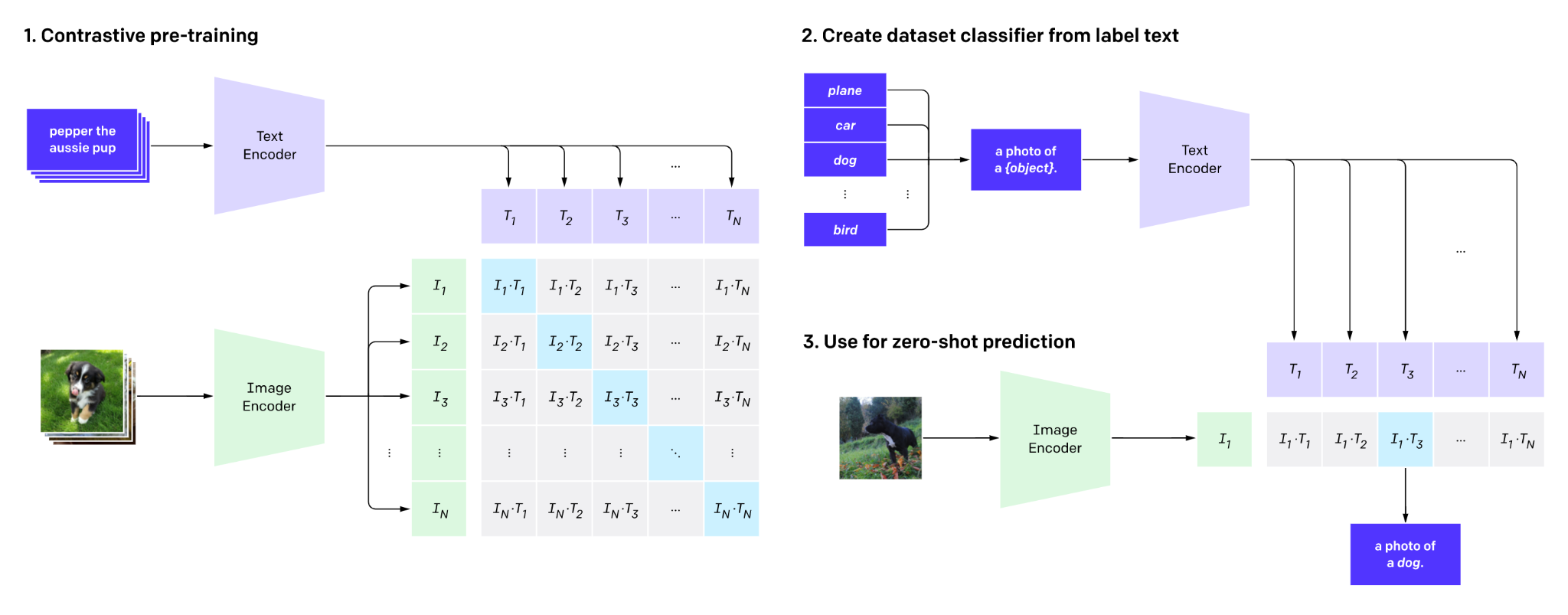
CLIP trains a text encoder (Bag-of-Words or Text Transformer) and an image encoder (ResNet or Image Transformer) which learns feature representations of a given pair of text and image. The scaled cosine similarity matrix of the image and text feature is computed, and the diagonal values are minimized to force the image feature match its corresponding text feature.
In this experiment, we will focus on using CLIP with BigGAN for image generation. A wonderful prior work has been done by Ryan Murdock known as BigSleep, which our code is largely adapted from. We are interested in answering the question: is CLIP + BigGAN able to generate realistic images given abstract, high-level concepts? This is, in our opinion, a crucial question to answer for high-level representation learning in ML models.
How BigSleep Works

BigSleep uses CLIP to steer images generated by BigGAN to be semantically closer to the text prompt.
Firstly, let's clarify the inputs and outputs of the CLIP and BigGAN models respectively. BigGAN takes in a noise vector, and outputs a realistic image; whereas CLIP can take in (i) an image, and output the image features; or (ii) a text, and output text features. The relevance between image and text features can be represented by the cosine similarity of the learnt feature vectors.
How can we combine CLIP and BigGAN to generate image from a given text? The key idea of BigSleep is to steer the generation of BigGAN based on the relevance of the generated image, and the given text prompt, assessed by CLIP. Think of an actor-critic pair, where BigGAN is the actor that generates images, and CLIP is the critic which gives feedback to steer the generation towards the given text representation.
The key code block is shown as below, which is in the ascend_txt() function which formulates the loss terms for optimization. Attached below is the commented version of the code:
def ascend_txt():# generate image with BigGAN model, using latent vectors lats() which corresponds to a dogout = model(*lats(), 1)cutn = 128p_s = []# post-process generated imagefor ch in range(cutn):size = int(sideX*torch.zeros(1,).normal_(mean=.8, std=.3).clip(.5, .95))offsetx = torch.randint(0, sideX - size, ())offsety = torch.randint(0, sideX - size, ())apper = out[:, :, offsetx:offsetx + size, offsety:offsety + size]apper = torch.nn.functional.interpolate(apper, (224,224), mode='nearest')p_s.append(apper)into = torch.cat(p_s, 0)into = nom((into + 1) / 2)# get image features using CLIP modeliii = perceptor.encode_image(into)llls = lats()# according to the author, lat_1 and cls_1 are used to "prevent latent and class vectors growing too large"lat_l = torch.abs(1 - torch.std(llls[0], dim=1)).mean() + \torch.abs(torch.mean(llls[0])).mean() + \4*torch.max(torch.square(llls[0]).mean(), lats.thrsh_lat)for array in llls[0]:mean = torch.mean(array)diffs = array - meanvar = torch.mean(torch.pow(diffs, 2.0))std = torch.pow(var, 0.5)zscores = diffs / stdskews = torch.mean(torch.pow(zscores, 3.0))kurtoses = torch.mean(torch.pow(zscores, 4.0)) - 3.0lat_l = lat_l + torch.abs(kurtoses) / llls[0].shape[0] + torch.abs(skews) / llls[0].shape[0]cls_l = ((50*torch.topk(llls[1],largest=False,dim=1,k=999)[0])**2).mean()# final loss is the relevance between the text prompt features (t) and the image featuresreturn [lat_l, cls_l, -100*torch.cosine_similarity(t, iii, dim=-1).mean()]
Experiments
Below we use BigSleep to generate images based on the following abstract concept text prompts: color, emotion, spatial direction, and number counting. All generation uses the same latent code (which decodes into a dog image) as the starting point, and the training process is halted when we find the generated image no longer shows significant changes / improvement as compared to the last displayed epoch. The images generated are logged using the wandb library.
Reproduce the results with this Colab Notebook
Color
Run set
32

The model performs well on color-related prompts, and the color traits are obviously demonstrated in the image, although the entire image is not necessarily realistic.
Emotion
Run set
32
In general, the model also performs well on emotion-related prompts. For example, the "happy" prompt generates images with smiley "faces", the "sad" prompt generates images with tear drops and frowning-like "faces", the "shocked" prompt generates a surprised-like facial expression (of a bird or fish?). The "calm" prompt is extremely interesting because it generates scenery-like images that makes you feel calm when looking at it. The only prompt which does not perform well is "energetic", which generates a bird-like object but without any strong relevance with the prompt.
Counting
Run set
32
The model does not perform well on counting-related prompts, as pointed out in the paper as well. We try to input text prompts from "one cup" to "three cups", but it only generates cup-related images (e.g. a beer-like image for "one cup", and several cup-like objects for the other two prompts). It seems like the model has ignored the contextual information provided by numbers, and pays more attention to the noun object.
Spatial Directions
Run set
32
The model also perform weakly on spatial direction related prompts in general. The slightly better ones might be " a dog beside a cat" and "a cup on top of a box", which vaguely shows such spatial information. For the remaining prompts, although the generated image shows relevance to the noun objects ("dog" and "cat"), but the spatial information are largely ignored.
Conclusion
In conclusion, we find several strengths and limitations of using CLIP + BigGAN model for image generation based on abstract concepts:
- The model is able to capture the noun objects in the text prompt (e.g. dog, cat, cup, etc.). Although the generated object might not be realistic enough, it does show high level of relevance to the corresponding noun object.
- The model also performs well on attributes with strong visual cues, e.g. color, and emotion that are relatively straight-forward to identify (e.g. happy, sad, shocked).
- However, the model is still unable to have common sense reasoning capabilities, e.g. it fails on counting-related prompts and spatial-direction prompts. It seems like the model ignores the numbers and spatial information, and focus only on the noun objects.
There is still a long way for (pre-trained) deep learning models to accurately capture abstract, high level concepts in both visual and text cues under zero-shot learning conditions. However, combining computer vision and natural language processing would continue to be an interesting approach to further improve the frontiers of this research domain.
Add a comment
Tags: Intermediate, Computer Vision, GenAI, OpenAI, Experiment, BigGAN, CLIP, GAN, Panels, Plots, CIFAR10, TMP

Iterate on AI agents and models faster. Try Weights & Biases today.