A Deep Dive Into OpenCLIP from OpenAI
This article explores an open re-implementation of OpenAI's CLIP model for zero-shot classification and covers its additional uses and its potential issues.
Created on November 7|Last edited on February 13
Comment
In early 2021 OpenAI announced CLIP, a model that 'efficiently learns visual concepts from natural language supervision'.
CLIP is incredibly powerful and has seen usage far beyond what the original creators anticipated, powering everything from data filtering and search to AI art creation.
In this article, we'll look at how CLIP works and dive into the OpenCLIP project responsible for creating and training an open-source implementation.

A CLIP self-portrait, created with CLIP and Stable Diffusion using the prompt "contrastive language-image pretraining visualized by CLIP (digital art)"
Here's what we'll be exploring in this article:
How Does The CLIP Model Work?OpenCLIP & LAION: An Interview with Romain Beaumont Using OpenCLIP for Zero-Shot ClassificationAdditional UsesPotential IssuesFinal ThoughtsRelated Reading
Let's dig in!
How Does The CLIP Model Work?
CLIP (Contrastive Language-Image Pre-training) is a method created by OpenAI for training models capable of aligning image and text representations. Images and text are drastically different modalities, but CLIP manages to map both to a shared space, allowing for all kinds of neat tricks.
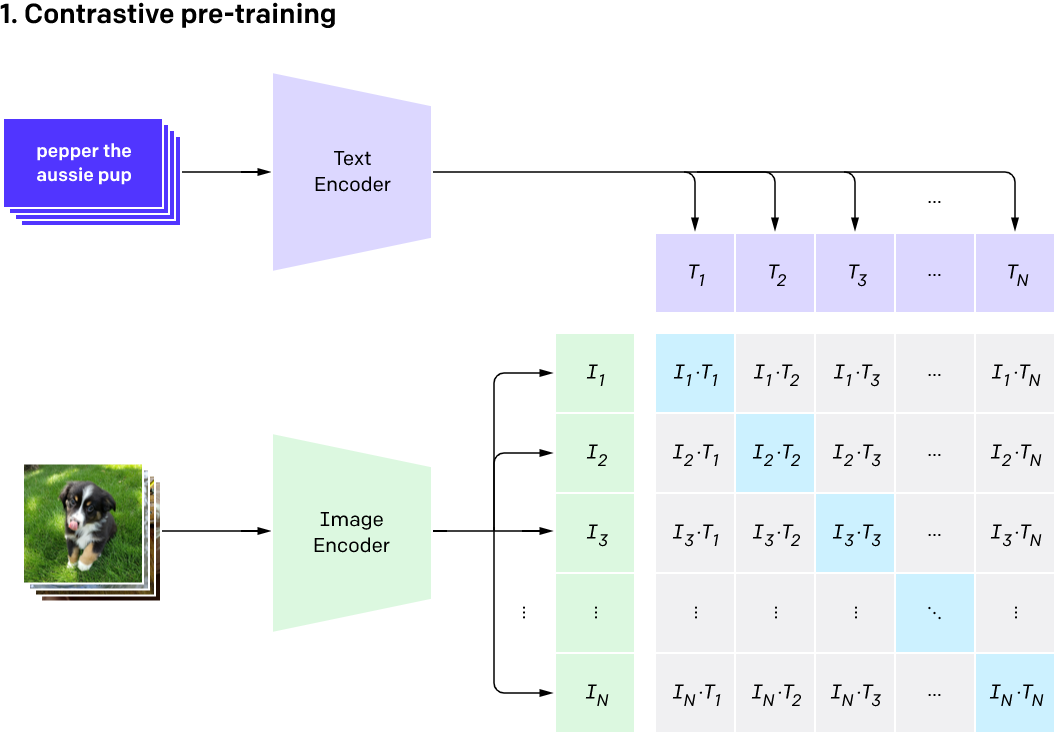
During training, CLIP takes in image-caption pairs. The images are fed through an image encoder model (based on a resnet or ViT backbone) and transformed into an embedding vector (I in the diagram above). A second model (typically a transformer model of some sort) takes the text and transforms it into an embedding vector (T in the diagram).
Crucially, both of these embeddings are the same shape, allowing for direct comparison. Given a batch of image-caption pairs, CLIP tries to maximize the similarity of image and text embeddings that go together (the blue diagonal in the diagram) while minimizing the similarity between non-related pairs.
The result: an image encoder and a text encoder that tend to produce embeddings in a shared space, where similar concepts (either visual or textual) are closer together than unrelated concepts. These embeddings capture rich semantic information from images and text, which are incredibly useful for various downstream tasks such as zero-shot image classification (explored below).
OpenCLIP & LAION: An Interview with Romain Beaumont
OpenAI trained a number of model variants on their internal dataset of 400 million image-caption pairs. They did share model weights but not the data used for training.
Enter OpenCLIP, an open-source replication effort that has successfully created a CLIP implementation and released a number of trained models for anyone to use. To find out more about how a project like this comes about, I spoke with Romain Beaumont, who helped found LAION and has been heavily involved with every step of the OpenCLIP process, from dataset creation to model training:
Q: OpenAI had 400 million image-caption pairs to train with, so a large part of re-creating their models was assembling a similar dataset. Can you tell us briefly about LAION and how that all came together?
About 1.5 years ago, as of this writing, OpenAI released their awesome blog posts and corresponding papers about CLIP and DALL-E, proving that it was possible to build models capable of zero-shot classification, retrieval, and image generation based on this kind of data.
A group of people talking in the EleutherAI Discord thought it would be cool to provide this kind of big dataset openly and set out to do just that. Eventually, that resulted in the creation of the LAION organization and the release of a dataset of 400 million pairs and then a larger version with 5 billion pairs.
These datasets have been used in many text+image models, including Stable Diffusion, OpenCLIP, Imagen, Phenaki, Make-A-Video, and many more.
Q: You and Ross Wightman recently trained some big new models, with one claiming the new state-of-the-art for zero-shot imagenet classification with a CLIP model. I'm guessing there's a bit more to training a big model like this than just running train.py and hoping for the best!
I notice your open-clip Weights & Biases workspace has ~350 runs logged and counting - what are some of the experiments you're trying?
For about one year, we've been playing with reproducing CLIP. Initially, that was done at a very low-scale setup with the OpenCLIP initial paper: training using about 10M samples and for less than a thousand GPU hours. That's how the initial code was developed, and it proved there was something to do there.
We continued this effort by getting grants at JUWELS supercomputer, where we reproduced all the OpeAI CLIP models up to L/14, the largest experiment using some 100k GPU hours. Then we received more compute grants in the Stability cluster and used 200k GPU hours to train that state-of-the-art H/14 model.
At each step of this process, we experimented a lot to find the right hyperparameters (lr, batch size, what formulation of the loss, with/without gradient checkpointing, with/without dataset resampling).
For that latest iteration (H/14), new challenges appeared: making things work at the 200k GPU hours scale without crashing constantly. To do this, I developed some tools to find the bad GPUs.
Another big challenge was that bigger models mean unstable models; I had to try some 15 variants of parameters to eventually find that changing the precision from float16 to bfloat16 fixed it.
Weights & Biases was super-useful there to quickly notice when the loss curve didn't behave
Q: Once a full training run has started, how involved are you in the process?
I'm guessing you're constantly checking the logs, stopping and resuming with new settings, and watching metrics to make sure it is still improving... what does a typical day look like for you while training is ongoing?
The workflow usually looks like this:
- Starting the run, checking it doesn't crash in the text logs
- Checking the loss curve is decreasing in W&B, no huge spike
- Starting a companion eval run that also reports to W&B, checking the metrics are indeed improving
- Resuming (automatically most of the time) when the job crashes
- Sometimes stopping it completely and investigating in case something looks wrong
Q: Thank you for your time. Any final thoughts or tips for others interested in learning how to approach big projects like this themselves?
LAION is still building more datasets (audio, video, text, ...) and cooperating with people to train interesting models, such as a multi-lingual CLIP model, which is currently in development.
It's an open org and discord, if you're interested, feel free to join and propose your help. We can guide people in how best to contribute.
Using OpenCLIP for Zero-Shot Classification
Remember, these models were only trained to align image captions - so how do we use them for classification?
A trained CLIP model can give us a 'similarity score' between an image and a text description. To use this for classification, we first turn our class labels into text via a prompt such as 'a photo of a {label}' and embed these text descriptions with the CLIP text encoder.
Then we embed our image and see which text embedding best aligns with the image embedding using a measure such as cosine similarity. If all goes well, the best match will be the caption containing the correct label.
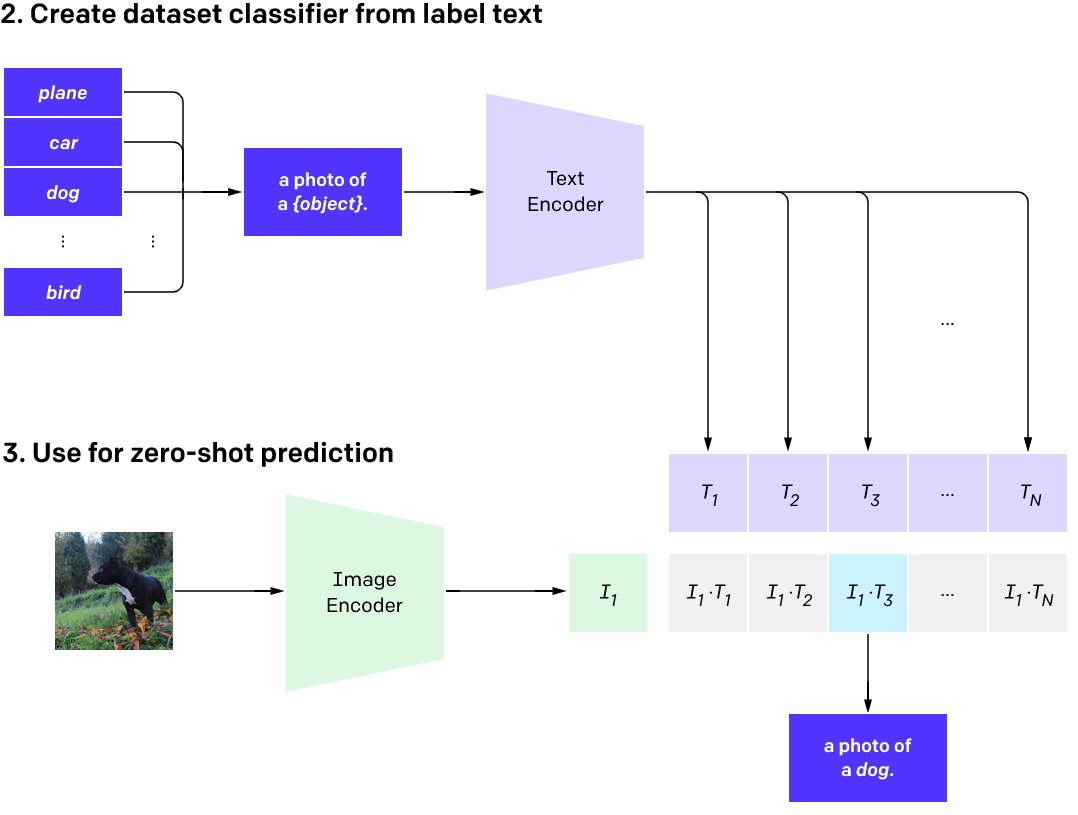
Using this approach, we can see how well some different CLIP models perform on a few image classification tasks. Following the example code in the OpenCLIP GitHub repository, I set up a notebook to load 256 images at a time and classify them based on the class labels.
I chose to begin with the Imagenette dataset, a small subset of the well-known Imagenet dataset containing 10 easy-to-classify classes. We compare a Resnet50 model trained on 12 million captioned images (RN50 + cc12M), a ViT-based model ('Base' size, patch size 32) from OpenAI trained on their internal dataset of 400M images, an equivalent model trained on LAION 400M by OpenCLIP and a larger ('Huge' size, patch size 14) ViT model trained on 2 billion images (LAION2B).
As expected, the largest model takes the top spot for accuracy, but the smaller ViT models from both OpenAI and OpenCLIP weren't far behind, were nearly 10X faster, and are much smaller to download (600MB vs. nearly 4GB).
Moving to a slightly harder dataset: Imagewoof. This consists of 10 dog breeds, which are much harder to tell apart. Here the small ResNet-based model trained on a relatively tiny dataset really suffers compared to the other models:
Amazingly, the largest model can correctly match the images with the correct class ~94% of the time. Not bad for a model that was never trained for dog breed classification! The best models trained from scratch on Imagewoof only score about 90% accuracy.
Additional Uses
When CLIP was released, it was likely assumed that it would find a niche as a pretraining method for image classification and for tasks such as zero-shot classification or retrieval. However, CLIP was quickly co-opted by enthusiastic developers for a multitude of other creative uses, including many of the AI art techniques that sprang up shortly afterward.
Very rarely does a single model prompt such an explosion of creativity!

An image created by optimizing the parameters of an imstack to match the CLIP prompt 'watercolor painting of an underwater submarine'
An Incomplete List of Additional Uses for CLIP:
- Image Retrieval, where images are compared with an input text query enabling powerful search capabilities. A good example is Clip front which lets you search LAION
- Generated Image Ranking. Some text-to-image models (such as CRAIYON) generate a number of images and use CLIP to select the results that best match the text prompt
- Semantically Rich Embeddings as Conditioning for Text-to-Image models. CLIP learns rich representations of images and text, and these are often used as conditioning information for text-to-image models such as Stable Diffusion.
- Guiding Image Generation. CLIP can also be used directly to guide generative processes such as diffusion or even as a loss function to directly optimize the pixels of an image or the parameters of an image generator like VQGAN. In my course (The Generative Landscape), we use CLIP to steer all manner of image generators, guide unconditional diffusion models, tweak the parameters of Neural Cellular Automata and navigate the latent space of GANs.
Potential Issues
Like any model trained on raw data from the internet, CLIP is not without its flaws.
Representation is skewed by historical factors surrounding who creates and uploads the most images, language use, and caption trends. Thus many model variants contain biases that can negatively affect some subsets of the population and cause harm in a number of ways.
For example, SEO spam in the captions of adult content sites has resulted in some CLIP model variants associating even seemingly innocuous words with NSFW content. If you're considering using these models in production, then it is on you to test thoroughly and to make sure that you do so as responsibly as possible.
Final Thoughts
CLIP has proven to be an incredibly powerful and versatile tool, and thanks to the efforts of the OpenCLIP project, it is one that is accessible to everybody. I hope this deep dive has inspired you to add this to your toolbox, and I can't wait to see what other uses we will invent for it!
Related Reading
Implementing CLIP With PyTorch Lightning
This article explores how to use PyTorch Lightning to implement the CLIP model for natural language-based image search to find images for a set of given prompts.
Google Bakes A FLAN: Improved Zero-Shot Learning For NLP
Google Research has improved zero-shot learning abilities for NLP with FLAN. But what is it?
Add a comment

Thomas Capelle •
This is a great read!
1 reply

Iterate on AI agents and models faster. Try Weights & Biases today.