A Step-by-Step Guide to Tracking HuggingFace Model Performance
This article provides a quick tutorial for training Natural Language Processing (NLP) models with HuggingFace and visualizing their performance with W&B.
Created on May 7|Last edited on December 14
Comment
This article explains how to train a model (specifically, an Natural Language Processing (NLP) classifier) using the Weights & Biases and HuggingFace transformers Python packages.
- HuggingFace Transformers makes it easy to create and use NLP models. They also include pre-trained models and scripts for training models for common NLP tasks (more on this later!).
Table of Contents
Let's get started.
Setup
1. Installation
Both packages are available on PyPI, so we can install them like this:
pip install git+https://github.com/huggingface/transformers.gitpip install wandb
2. Connecting Weights & Biases
Open the Python shell (type python in the console) and type the following:
import wandbwandb.login()
That's it! Our wandb package will now log runs to our Weights & Biases account. So when we train our model, we'll be able to log onto app.wandb.ai and see statistics about training, while it's going on.
3. Downloading the Script
We're going to use a script provided by transformers in this tutorial. We can grab the script from the web using wget
wget https://raw.githubusercontent.com/huggingface/transformers/master/examples/pytorch/text-classification/run_glue.py
The GLUE Benchmark
By now, you're probably curious what task and dataset we're actually going to be training our model on. Out of the box, transformers provides great support for the General Language Understanding Evaluation (GLUE) benchmark.
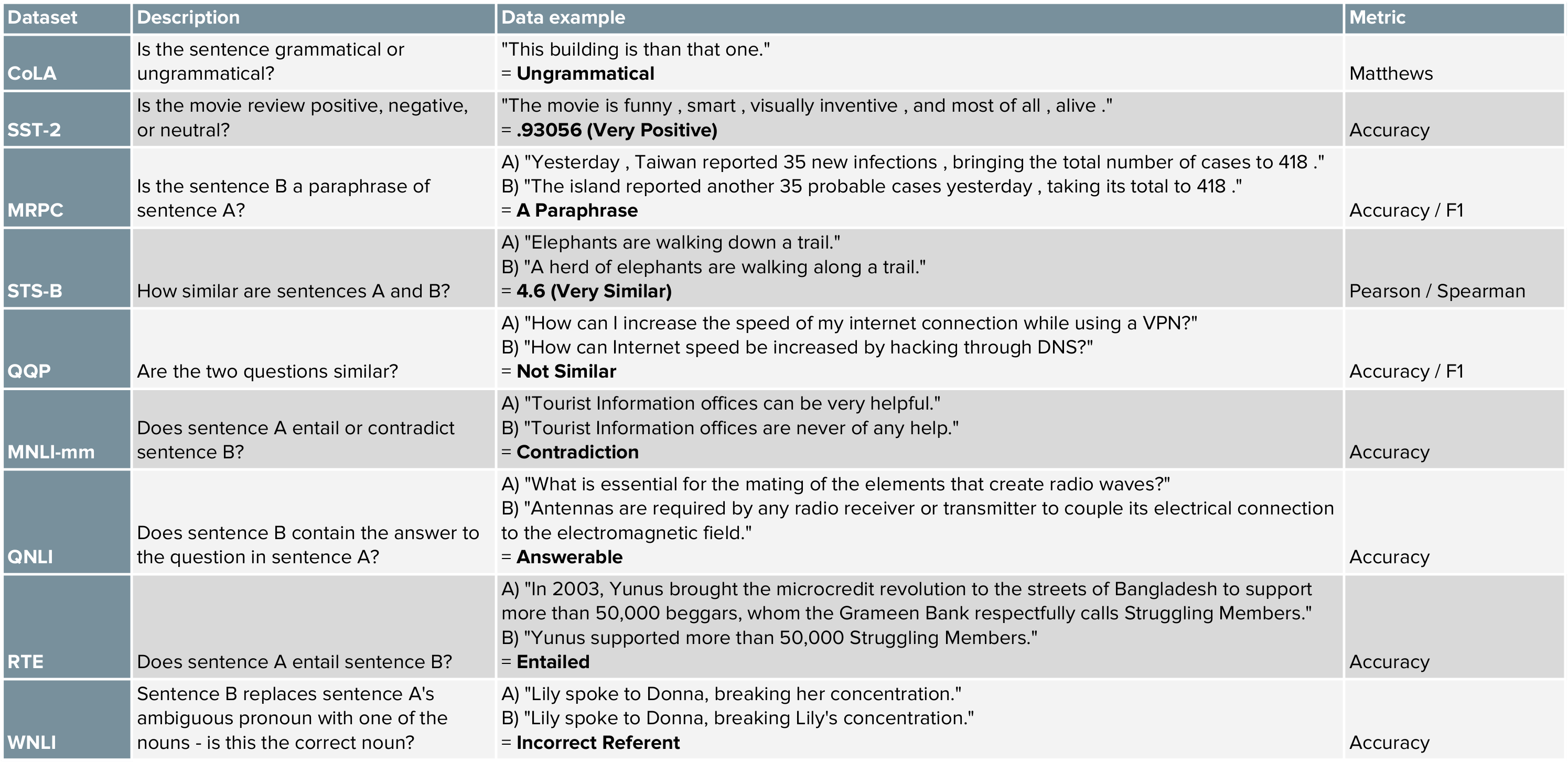
GLUE is really just a collection of nine datasets and tasks for training NLP models. If you train a good NLP model, it should be able to generalize well to all nine of these tasks. There's even a public leaderboard that shows the models that have achieved top performance across all the GLUE tasks.
Here's a quick description of each task:
Preparing for Training
Now, as you may have guessed, it's time to run run_glue.py and actually train the model. This script will take care of everything for us: processing the data, training the model, and even logging results to Weights & Biases. Before running it, we have two more things to decide on: the dataset and the model.
Choosing our model: DistilBERT
transformers provides lots of state-of-the-art NLP models that we can use for training, including BERT, XLNet, RoBerta, and T5 (see the repository for a full list). They also provide a model hub where community members can share their models. If you train a model that achieves a competitive score on the GLUE benchmark, you should share it on the model hub!
It's up to you which model you choose to train. For this tutorial, we're going to use DistilBERT. DistilBERT is a Transformer that's 40% smaller than BERT but retains 97% of BERT's accuracy.

Choosing our dataset: CoLA
Our training script (run_glue.py) supports all of the GLUE tasks. We're going to use the CoLA (Corpus of Linguistic Acceptability) dataset, but we could fine-tune our model on any of the nine datasets we've already downloaded. Feel free to choose another dataset (or model!) when you test out the training script.
Training the Model
In Section 2, we decided to fine-tune DistilBERT on the CoLA dataset. We're going to supply these two pieces of information as arguments to run_glue.py:
export WANDB_PROJECT=huggingface-demoexport TASK_NAME=COLA!python run_glue.py \--model_name_or_path bert-base-uncased \--task_name $TASK_NAME \--do_train \--do_eval \--max_seq_length 256 \--per_device_train_batch_size 32 \--learning_rate 2e-5 \--num_train_epochs 6 \--output_dir /tmp/$TASK_NAME/ \--overwrite_output_dir \--logging_steps 50
I've just chosen default hyperparameters for fine-tuning (learning rate , for example) and provided some other command-line arguments. (If you're unsure what an argument is for, you can always run python run_glue.py --help.)
Add a comment

Jon Capriola •
This is genius are my immediate thoughts
Reply

Iterate on AI agents and models faster. Try Weights & Biases today.