A guide to large language models (LLMs)
Learn about the history of LLMs, including the groundbreaking GPT series and how they work, and explore developments like human-guided reinforcement learning.
Created on March 16|Last edited on July 17
Comment
In this article, we will delve into the fascinating world of large language models (LLMs) and their incredible ability to understand and generate human-like language. We'll discuss the history and evolution of these models, touching upon significant milestones such as GPT and its successors.
We'll also explore the different types of LLMs, their applications, and the inner workings of the Transformer architecture that underpins many of the most advanced models. Furthermore, we'll examine cutting-edge developments like human-guided reinforcement learning and how it empowers AI performance.
By the end of this article, you'll have a thorough understanding of large language models, their immense potential, and the exciting future that lies ahead for this groundbreaking technology.
Here's what we'll be covering:
Table of Contents
What Is a Large Language Model?What Was the First Large Language Model?What Are the Types of Large Language Models?Autoencoder-Based ModelSequence-to-Sequence ModelTransformer-Based ModelsRecursive Neural Network ModelsHierarchical ModelsHow Do Large Language Models Work?1- Word Embedding2- Positional Encoding3- Transformers4- Text GenerationEmpowering AI Performance With Human-Guided Reinforcement LearningExamples of Large Language ModelsBERTGPT-4Future of Large Language Models
Let's get started!
What Is a Large Language Model?
When we talk about large language models, we're referring to a type of software that can "speak" in human-like language. These models are pretty amazing - they're able to gather the context and generate responses that are not only coherent but also feel like they're coming from a real human.
These language models work by analyzing vast amounts of text data and learning the patterns of language usage. They use these patterns to generate text that's almost indistinguishable from something a person might say or write.
If you've ever chatted with a virtual assistant or interacted with an AI customer service agent, you might have interacted with a large language model without even realizing it! These models have a wide range of applications, from chatbots to language translation to content creation.
Some of the most impressive large language models are developed by OpenAI. Their GPT-3 model, for example, has over 175 billion parameters and is able to perform tasks like summarization, question-answering, and even creative writing! In case you are still not sure how good such a model can get, I suggest that you go in and try Chat GPT yourself.
What Was the First Large Language Model?
As we mentioned earlier, when talking about large language models, we're basically talking about software that excels at generating human-like language. The first model that really caught people's attention was the GPT (Generative Pre-trained Transformer) model developed by OpenAI in 2018. The well-known ChatGPT is basically GPT-3.5.
What made the GPT model so special was that it was one of the first language models to use the transformer architecture. This is a type of neural network that's great at understanding long-range dependencies in text data, which made it possible for the model to generate highly coherent and contextually relevant language output. With 117 million parameters, the GPT model was a real game-changer for natural language processing.
Since then, we've seen the development of even larger and more impressive language models, like GPT-2, GPT-3, and BERT. These models can generate text that's even more sophisticated and human-like than the GPT model. But even though the GPT model might not be the biggest or the best anymore, it's still an important milestone in the history of language models and has had a major impact on the field of natural language processing.
What Are the Types of Large Language Models?
There are several different types of large language models, each with its own set of strengths and weaknesses.
Autoencoder-Based Model
One type of large language model is the autoencoder-based model, which works by encoding input text into a lower-dimensional representation and then generating new text based on that representation. This type of model is especially good for tasks like summarizing text or generating content.
Sequence-to-Sequence Model
Another type of large language model is the sequence-to-sequence model, which takes an input sequence (like a sentence) and generates an output sequence (like a translation into another language). These models are often used for machine translation and text summarization.
Transformer-Based Models
Transformer-based models are another popular type of large language model. These models use a neural network architecture that's great at understanding long-range dependencies in text data, making them useful for a wide range of language tasks, including generating text, translating languages, and answering questions.
Recursive Neural Network Models
Recursive neural network models are designed to handle structured data like parse trees, which represent the syntactic structure of a sentence. These models are useful for tasks like sentiment analysis and natural language inference.
Hierarchical Models
Finally, hierarchical models are designed to handle text at different levels of granularity, such as sentences, paragraphs, and documents. These models are used for tasks like document classification and topic modeling.
How Do Large Language Models Work?
The most well-known Large Language Model (LLM) architecture is the transformer architecture. A typical Transformer model consists of four main steps in processing input data and we'll discuss each below:
First, the model performs word embedding to convert words into high-dimensional vector representations. Then, the data is passed through multiple transformer layers. Within these layers, the self-attention mechanism plays a crucial role in understanding the relationships between words in a sequence. Finally, after processing through the Transformer layers, the model generates text by predicting the most likely next word or token in the sequence based on the learned context.
Let's dig in a little further, shall we?
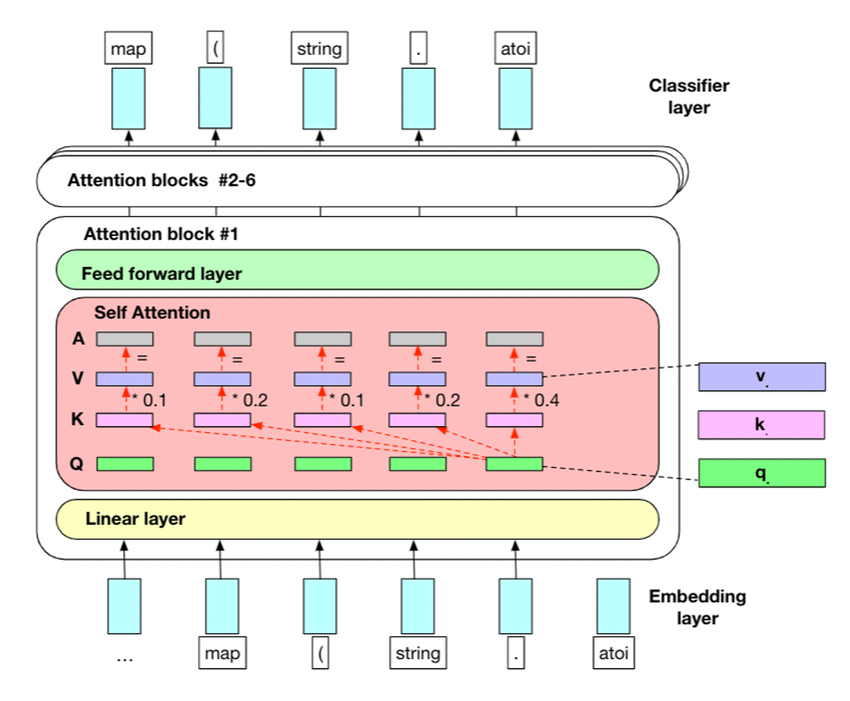
1- Word Embedding
When building a large language model, word embedding is a crucial first step. This involves representing words as vectors in a high-dimensional space where similar words are grouped together. This helps the model to understand the meaning of words and make predictions based on that understanding.

To give another example, let's consider the words "cat" and "dog." These two words will usually be closer to each other when compared to another pair of words, such as "cat" and "burgers." These words are similar in that they are both common pets that are often associated with being furry and friendly. In word embedding, these words would be represented as vectors that are located close to each other in the vector space. This allows the model to recognize that these two words have similar meanings and can be used in similar contexts. With that said, how is the word embedding process performed?
Creating word embeddings involves training a neural network on a large corpus of text data, such as news articles or books. During training, the network learns to predict the likelihood of a word appearing in a given context based on the words that come before and after it in a sentence. The vectors that are learned through this process capture the semantic relationships between different words in the corpus. A similar approach is followed with the words "King," "Queen," "Man," and "Woman."

Once the word embeddings are created, they can be used as inputs to a larger neural network that is trained on a specific language task, such as text classification or machine translation. By using word embeddings, the model can better understand the meaning of words and make more accurate predictions based on that understanding.
2- Positional Encoding
Positional encoding is all about helping the model figure out where words are in a sequence. It doesn't deal with the meaning of words or how they relate to each other, like how "cat" and "dog" are pretty similar. Instead, positional encoding is all about keeping track of word order. For example, when translating a sentence like "The cat is on the mat" to another language, it's crucial to know that "cat" comes before "mat." Word order is super important for tasks like translation, summarizing stuff, and answering questions.
During the training phase, the neural network is presented with a vast corpus of text data and is trained to make predictions based on that data. The weights of the neurons in the network are adjusted iteratively using a backpropagation algorithm in order to minimize the difference between the predicted output and the actual output.
3- Transformers
Advanced large language models utilize a certain architecture known as Transformers. Consider the transformer layer as a separate layer that comes after the traditional neural network layers. In fact, the transformer layer is often added as an additional layer to the traditional neural network architecture to improve the LLM's ability to model long-range dependencies in natural language text.
The transformer layer works by processing the entire input sequence in parallel rather than sequentially. It consists of two essential components: the self-attention mechanism and the feedforward neural network.

The self-attention mechanism allows the model to assign a weight to each word in the sequence, depending on how valuable it is for the prediction. This enables the model to capture the relationships between words, regardless of their distance from each other.

So, after the self-attention layer finishes processing the sequence, the position-wise feed-forward layer takes in each position in the input sequence and processes it independently.
For each position, a fully connected layer takes in a vector representation of the token (word or subword) at that position. This vector representation is the output from the preceding self-attention layer.
The fully connected layers in this context serve to transform the input vector representations into new vector representations, which are better suited for the model to learn complex patterns and relationships between words.
During training, the transformer layer's weights are updated repeatedly to reduce the difference between the predicted output and the actual output. This is done through the backpropagation algorithm, which is similar to the training process for traditional neural network layers.
For more on Transformers, check this article.
4- Text Generation
Often the last step performed by an LLM model; after the LLM has been trained and fine-tuned, the model can be used to generate highly sophisticated text in response to a prompt or question. The model is typically "primed" with a seed input, which can be a few words, a sentence, or even an entire paragraph. The LLM then uses its learned patterns to generate a coherent and contextually-relevant response.
Text generation relies on a technique called autoregression, where the model generates each word or token of the output sequence one at a time based on the previous words it has generated. The model uses the parameters it has learned during training to calculate the probability distribution of the next word or token and then selects the most likely choice as the next output.

Empowering AI Performance With Human-Guided Reinforcement Learning

One of the most fascinating developments in the field of large language models (LLMs) is the incorporation of Reinforcement Learning from Human Feedback (RLHF). This cutting-edge technique allows LLMs to learn and improve through feedback from humans, making them even more dynamic and powerful tools in a wide range of applications.
In general terms, RLHF implies a form of continuous feedback provided by a human entity to the machine learning model. The feedback can be either explicit or implicit. In the case of LLMs, if the model does return a wrong answer, the human user can correct the model, improving the model’s overall performance.
For example, if the LLM generates text that is not grammatically correct or semantically relevant, a human can provide feedback to the LLM, indicating which parts of the generated text are correct or incorrect. Human users can even explain or define the meaning of a given word that the model does not understand. The LLM can then use this feedback to adjust its parameters and improve its performance in generating text that better matches the desired outcome.
Examples of Large Language Models
BERT

BERT, which stands for Bidirectional Encoder Representations from Transformers, is a pre-trained deep learning model developed by Google that is designed to understand and generate natural language.
BERT utilizes a bi-directional transformer architecture, which means that it can process input text in both forward and backward directions to better understand the context and relationships between words.
BERT is utilized in a wide range of tasks, such as question answering, sentiment analysis, named entity recognition, and text classification. It has achieved state-of-the-art results on several benchmarks, including the Stanford Question Answering Dataset (SQuAD) and the GLUE (General Language Understanding Evaluation) benchmark.
As a comparison measure, BERT base has 110 million parameters, while BERT large, the more sophisticated of the two, has 345 million parameters.
GPT-4

After much anticipation, OpenAI has unveiled its latest innovation in the GPT series: GPT-4, short for Generative Pre-trained Transformer 4. This groundbreaking large language model surpasses its predecessors with a staggering 100 trillion parameters, a considerable leap from the 175 billion parameters of GPT-3.
GPT-4's key advantage similar to GPT-3 lies in its extensive pre-training on an enormous corpus of text data, enabling it to learn an incredibly diverse range of language features and relationships. As a result, GPT-4 can be fine-tuned for specific natural language processing tasks using relatively few examples, making it an exceptionally efficient and versatile tool for a vast array of applications.
To truly appreciate the capabilities of GPT-4, consider the fact that it is 500 times more powerful than GPT-3, which was the language model that OpenAI utilized to develop ChatGPT. This impressive advancement in the field of AI promises even more human-like and accurate responses, revolutionizing the way we interact with and benefit from artificial intelligence.
Future of Large Language Models
You know what's really exciting about the future of large language models? They're going to keep on getting better and better at understanding and replying to us humans. Soon, they'll be so efficient that we can use them on pretty much any device, like our phones or even tiny gadgets. And they'll become experts in specific areas too, like medicine or law, which is super cool.
But that's not all. These language models will be able to handle not just text but also images and sounds, and they'll work with languages from all over the world. Plus, people are working hard to make sure these AI models are fair and responsible, so they'll be more open and less biased.
So, in a nutshell, these language models are going to be amazing partners for us, helping out with all sorts of tasks and making our lives a whole lot easier in countless ways.
Add a comment

Iterate on AI agents and models faster. Try Weights & Biases today.