
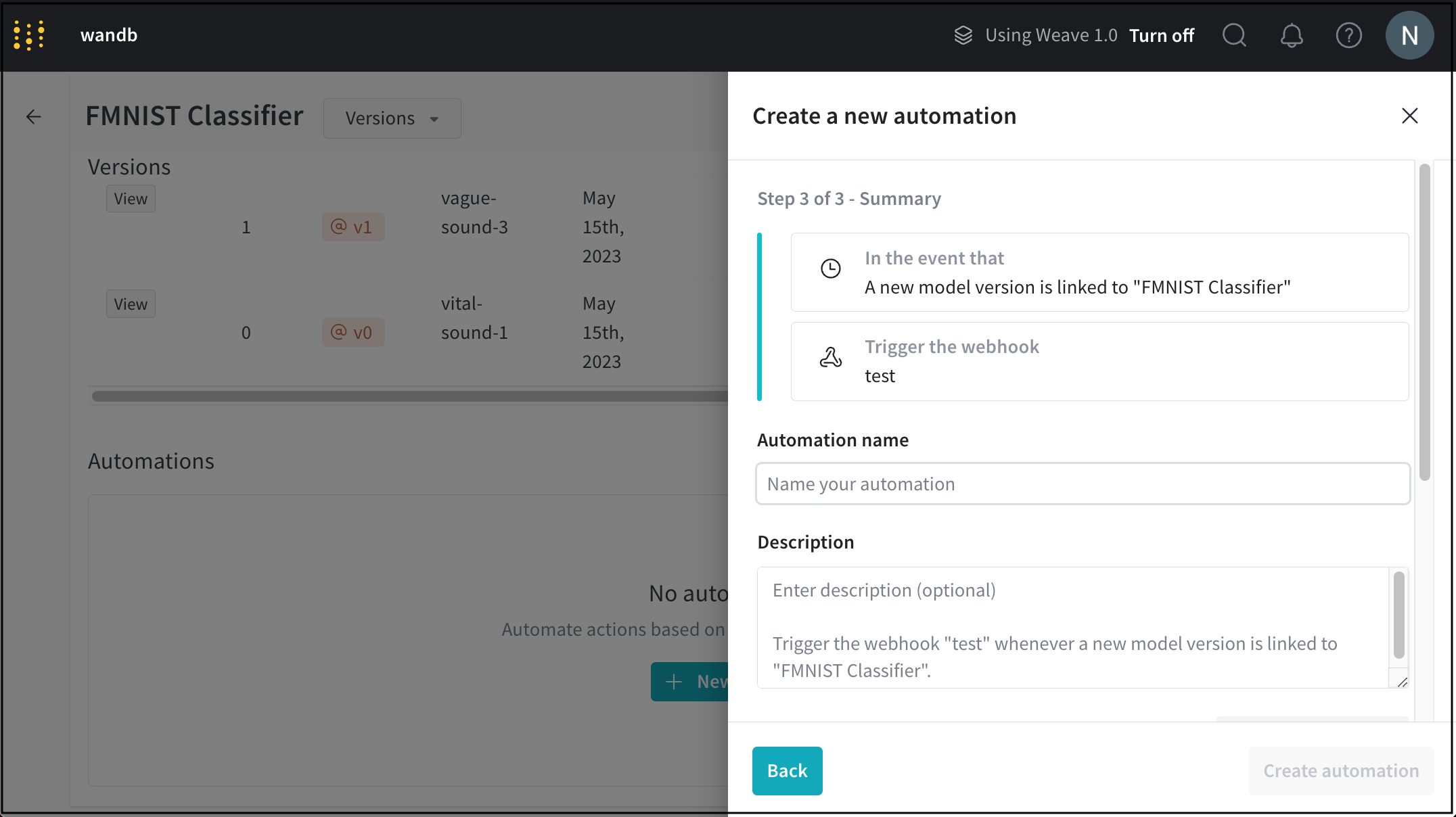
Connect events to downstream actions with Automations
Streamline your machine learning pipeline and implement sophisticated CI/CD processes by automatically executing workflow steps. Use W&B Automations to ensure that when certain events take place in your Model Registry, the appropriate downstream action is triggered in response.

Automate critical steps from centralized model registry hub
Trigger key events from the model registry to ensure seamless and automatic model handover for evaluation or deployment. Some examples of specific event types that can be automated include adding specific aliases to model versions such as “staging” or “QA”, adding new Artifact versions, or kicking off creation of a W&B Report with evaluation results.
Ensure high-performing models in production at all times with CI/CD
Deliver high-performing models in production at all times with an automated and continuous hand-off of model checkpoints from development to testing to deployment. Trigger GitHub Action workflows to consume models and run tests on it. Kick off hyperparameter sweeps or model training jobs every time you get a new dataset or refreshed training data. Deliver peace of mind with an automated, reliable and secure workflow.

Maintain data governance, security, and privacy with Secrets
Use Secrets for authentication or authorization when creating webhooks to ensure full data privacy and security. Obfuscate private strings such as credentials, API keys, passwords, tokens and more to protect plain text content. Secrets are available for Azure, GCP and AWS deployments.
The Weights & Biases end-to-end AI developer platform
Weave
Models
The Weights & Biases platform helps you streamline your workflow from end to end
Models
Experiments
Track and visualize your ML experiments
Sweeps
Optimize your hyperparameters
Registry
Publish and share your ML models and datasets
Automations
Trigger workflows automatically
Weave
Traces
Explore and
debug LLMs
Evaluations
Rigorous evaluations of GenAI applications