Most AI investments don’t underperform because the models are bad. They underperform because the infrastructure to support them was never built.

Many organizations have spent years funding AI, but find the models still aren’t working the way anyone hoped.
The pattern is familiar. Budgets were approved. Talented teams were hired. Initiatives launched. A few made it to production, and those are now quietly degrading. No one has flagged it yet.
The models weren’t the problem. The systems around them were.
That’s the gap MLOps closes.
This guide explains what MLOps is, why it’s a business problem as much as a technical one, and how platforms like Weights & Biases give organizations the visibility and control they need to turn AI investments into AI outcomes. It also covers how MLOps fits alongside DevOps and LLMOps, and what a practical strategy looks like for leaders who need their AI programs to start delivering.

Most executives who’ve invested seriously in machine learning know the feeling: the model demo was impressive, the AI team is talented, and yet somehow the project still isn’t in production six months later. Or it is in production, and nobody’s quite sure if it’s still working right. Both situations are more common than anyone likes to admit, and both have the same root cause.
MLOps is the answer to that root cause. It’s the operational backbone that determines whether your AI investments deliver consistent value or generate models that work in notebooks and nowhere else, and questionable ROI. The organizations running fifty governed, monitored models in production aren’t luckier or more talented than the ones running five fragile pilots. They just invested earlier in the systems that make machine learning repeatable.
As regulatory pressure grows, from the EU AI Act to sector-specific requirements in financial services and healthcare, MLOps is also becoming the difference between organizations that can demonstrate accountability for their models and those that discover, mid-audit, that they cannot. Done right, it shortens deployment cycles, reduces operational risk, and gives leadership the visibility to make real decisions. Done wrong, or not done at all, you’re running blind.


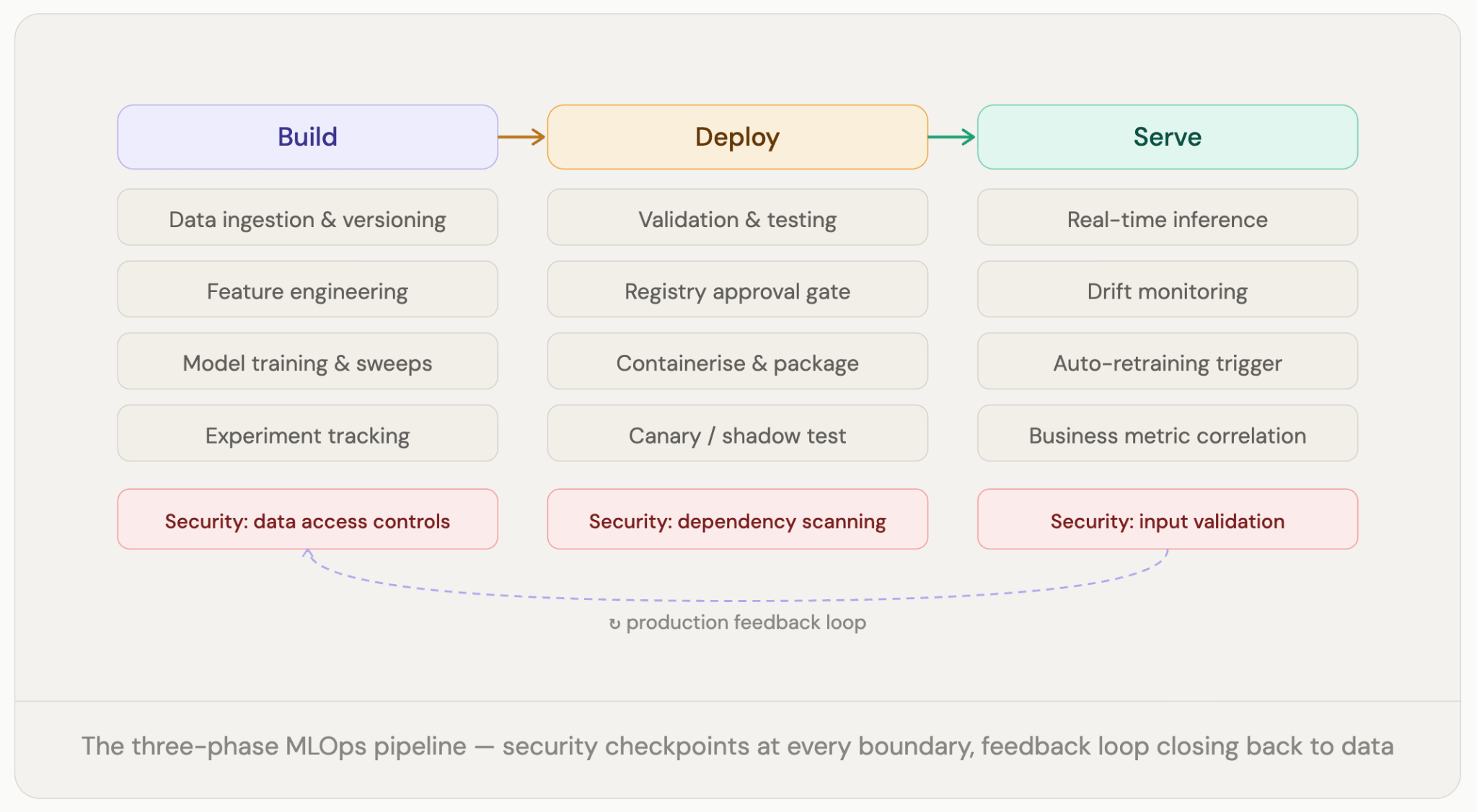
Machine learning doesn’t follow a straight line from data to deployment. It’s a loop. Production behavior feeds back into training decisions, better models change what production looks like, and monitoring closes the gap between the two. MLOps is the infrastructure that keeps that loop running, so each handoff between build, ship, and observe happens reliably rather than breaking down and depending on someone to manually pick up the pieces.

If your organization already runs mature DevOps, you have a head start, but not as big a one as most engineering teams assume. The instincts carry over: automate what can be automated, version everything, test before you ship, and watch what happens after. All of that still applies.
But here’s where it breaks down. When you ship software, the code sits there and does its job. It does not change on its own. A machine learning model does not work that way. You can put a model into production, not touch it for six months, and it quietly gets worse. Not because anything broke, but because the world it is running on changed, and nobody noticed. User behavior shifted. New patterns emerged that the training data never captured. The model was never told. That kind of failure does not happen with normal software. Your DevOps tools are not looking for it.
Large language models make it even more complicated. With an LLM, the prompt is part of the system. Change a word, and you can change the output entirely. There is often no clean right or wrong answer to check against. The information the model draws on gets outdated. Every inference costs money. None of that fits neatly into the monitoring and testing frameworks most teams already have in place.
You do not need a separate team for this. But you do need to think about it differently. The question is not whether your current tools can technically handle machine learning. Most can. The question is whether they were designed for it. They were not.


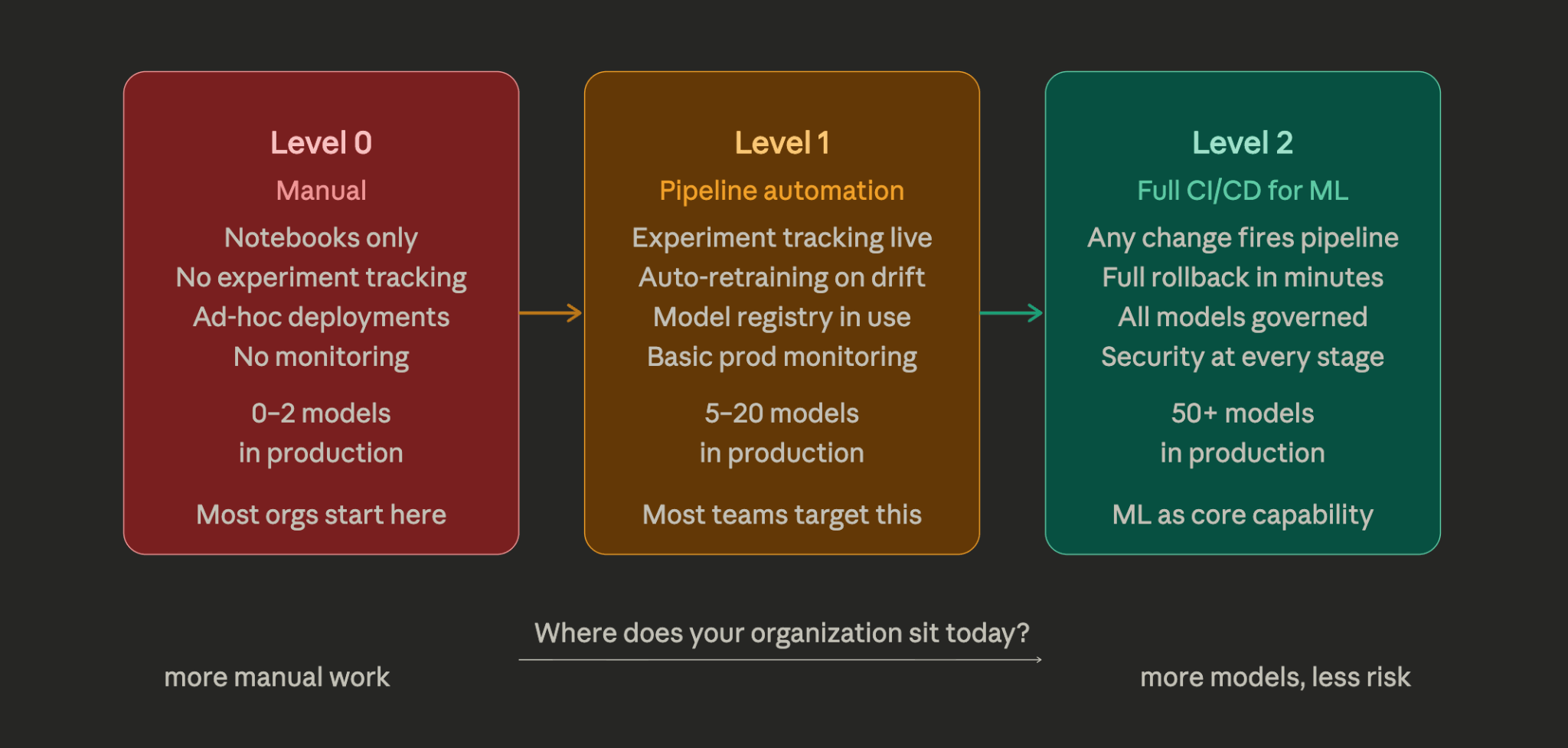
AWS’s MLOps framework defines three levels of automation maturity, and it’s become the most useful shorthand the industry has for diagnosing where an organization actually is versus where it thinks it is.
Most organizations are at Level 0 and think they’re at Level 1. The tell is usually the model registry, if it’s a shared folder or an S3 bucket with an informal naming convention, that’s Level 0 governance dressed up in Level 1 language.
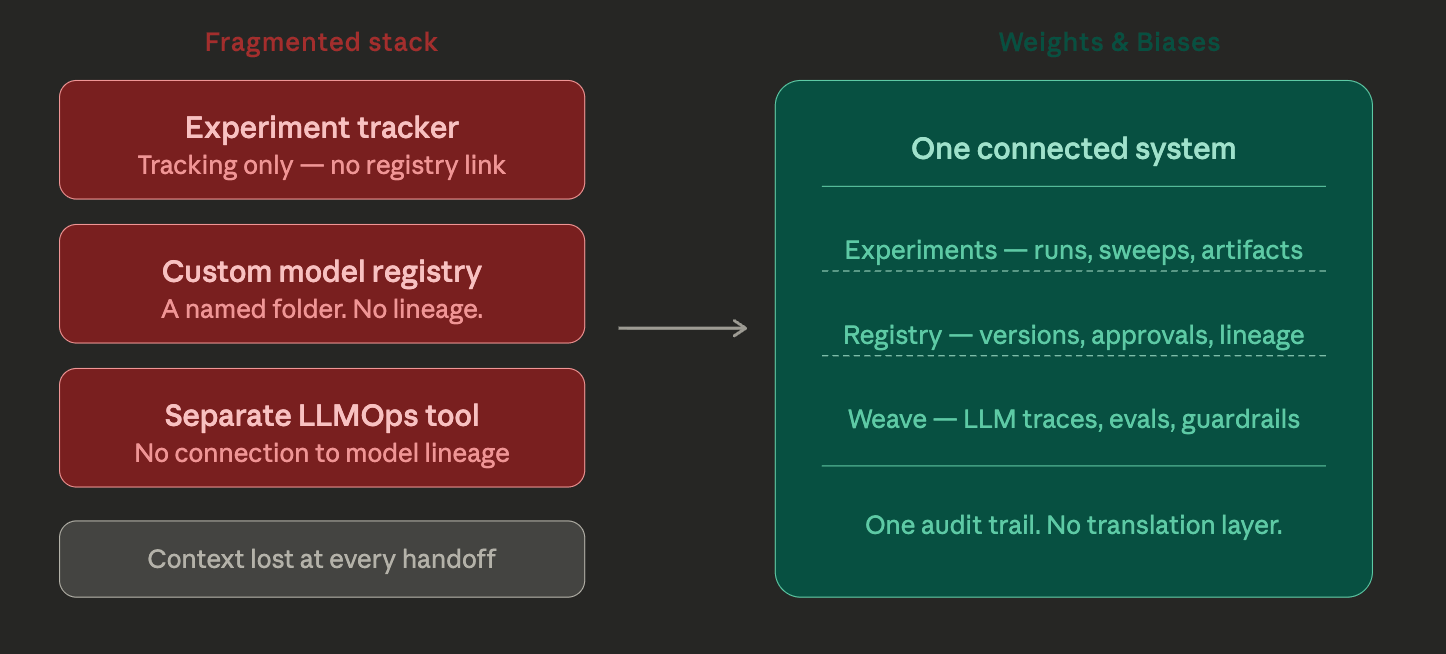
Most MLOps tool stacks are assembled from parts: an experiment tracker here, a model registry there, a separate monitoring solution, and another tool for LLMs. It works, technically. But the friction of moving data and context between disconnected systems is a real cost, and it tends to accumulate in the places that matter most: handoffs between experimentation and deployment, and between deployment and production observability.
Weights & Biases was designed as a unified system for the full machine learning lifecycle, which means that what a machine learning engineer logs during experimentation is the same record the registry pulls from during approval, which is the same lineage the monitoring system references when an alert fires. No translation layer. No context lost between stages.
W&B Experiments tracks every training run: parameters, metrics, system stats, and artifacts automatically. W&B Registry adds versioning, approval workflows, and production aliases with full lineage back to the original experiment. W&B Weave extends the same model to LLMOps: tracing LLM calls, running structured evaluations, managing prompts, and monitoring production agents. One platform, one audit trail, from first notebook to production LLM.