
PLAYGROUND
Experiment with prompts and models
W&B Weave Playground allows you to explore models and prompting techniques before building an AI agent or application, as well as troubleshoot prompts to resolve production issues.
You can test new LLMs and custom models against production traces, assessing their performance for your specific use cases. Testing models against production traces also helps you understand potential improvements achievable through the latest model advancements and customizations.
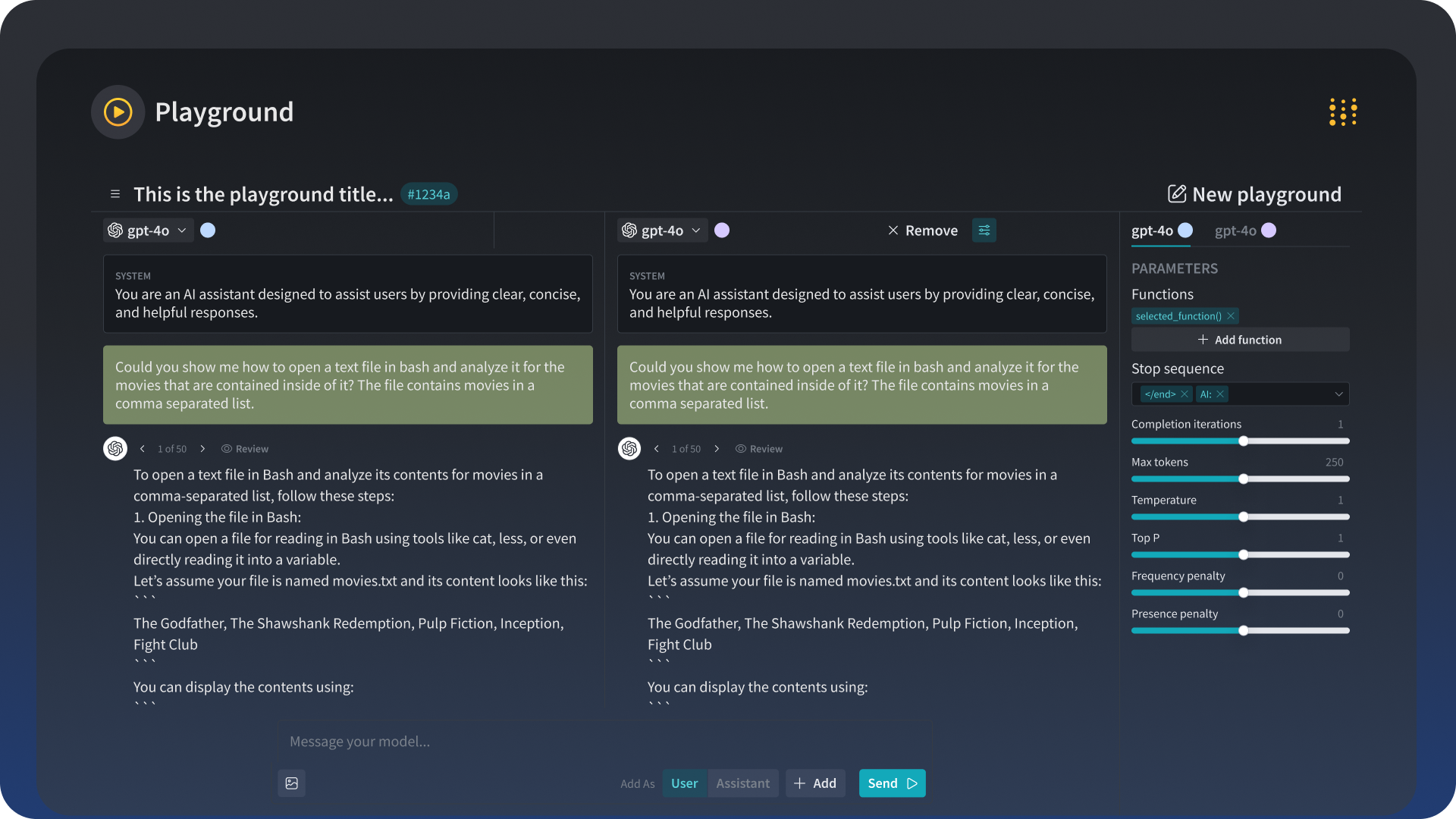

Test drive the newest LLMs
Compare different models to find the best fit. Easily test the same prompt across multiple models to determine which performs best for your use case. We make new models available within days, often hours, of their release.
Bring your custom models—or use 3rd party models
Weave Playground offers a broad selection of models, including Azure OpenAI, Gemini, Amazon Bedrock, Together AI, and Llama. You can also bring your own custom models into the playground to compare alongside our out-of-the-box options which is particularly useful if you fine-tune models for specific use cases.


Run trials to get statistical results
Generate multiple outputs for the same prompt to assess response consistency. Review individual trials to identify inconsistencies or outliers, then use these insights to fine-tune your LLM settings and implement effective guardrails.
Refine prompting techniques
Load production traces into the playground to troubleshoot prompt issues. Iterate on system prompts until the models return optimal responses. Adjust model settings such as temperature and maximum tokens to further optimize prompts specifically for your application.

Explore Weights & Biases
Learn more about Weave
The Weights & Biases platform helps you streamline your workflow from end to end
Models
Experiments
Track and visualize your ML experiments
Sweeps
Optimize your hyperparameters
Registry
Publish and share your ML models and datasets
Automations
Trigger workflows automatically
Weave
Traces
Explore and
debug LLMs
Evaluations
Rigorous evaluations of GenAI applications