
WEAVE
Observability and continuous improvement for production agents
Teams have tried to perfect agents offline, only to watch reliability collapse in production against failure modes no offline eval could catch. W&B Weave helps production agents learn and improve from real-world experience, so they can reach and maintain reliability.
Weave provides end-to-end observability to monitor agent behavior, out-of-the-box signals to surface failure modes, and a flexible evaluation framework to prevent regressions. Coding agents like Claude Code can connect to Weave and iterate on your agent continuously for exponentially compounding improvement.

Behavior monitoring with out-of-box signals
Monitoring millions of incoming traces and manually scoring them to extract signals is virtually impossible. Built-in and custom signals automatically capture and classify agent interactions, so you always know how your agents are behaving. Alerts route what matters through Slack notifications and trigger webhook automations, turning every production insight into a fast iteration.
Deep analytics tailored for agentic systems
Generic observability tools were designed for individual calls and simple traces, not multi-turn, multi-agent systems. Weave organizes traces into sessions and turns from the ground up. That structure, paired with native analytics tools, makes it easy to trace behavior across multi-agent systems and pinpoint root cases for failure modes that would otherwise stay buried in raw logs.
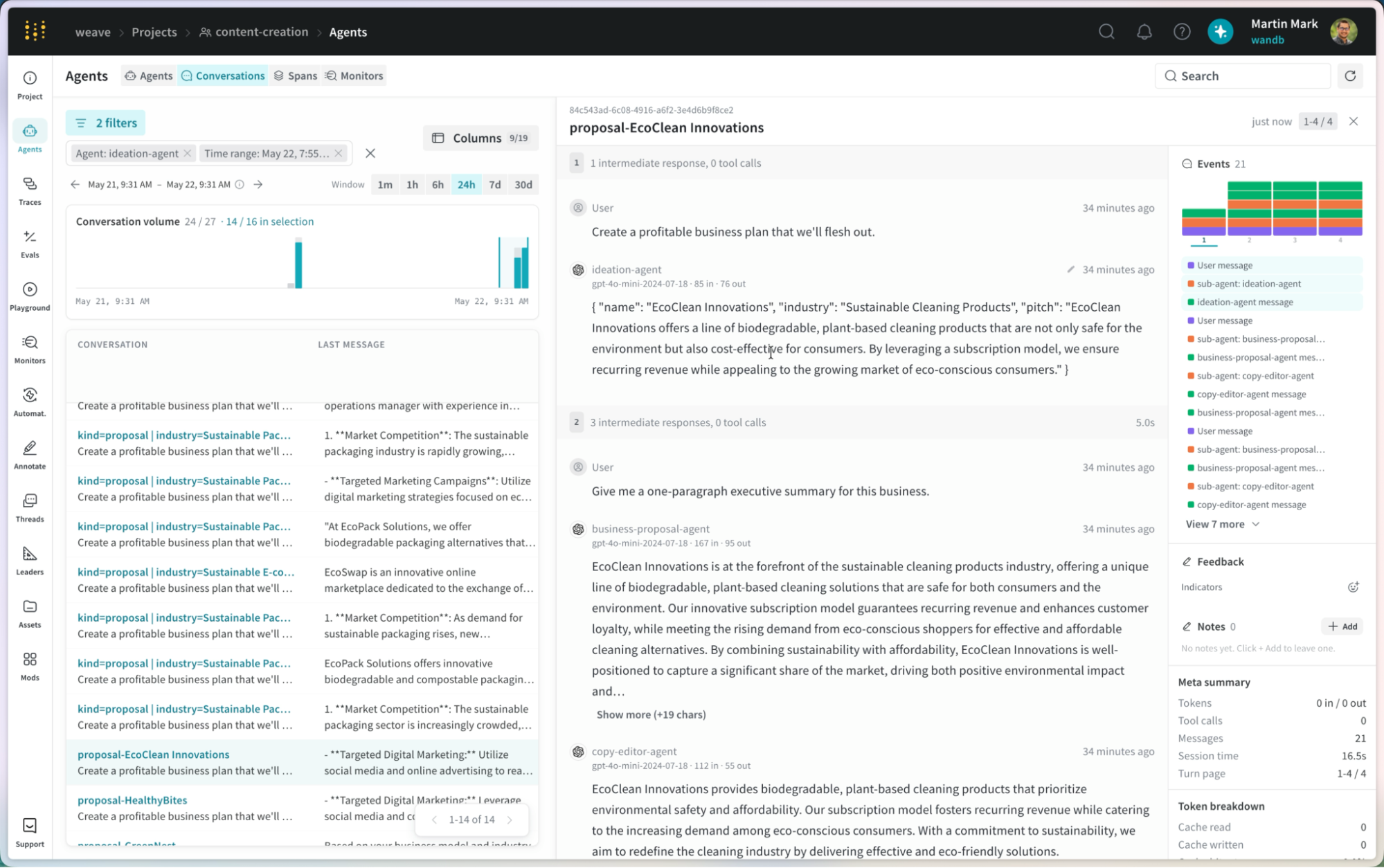

Agent-native tracing
Agent tracing is no longer just code tracing. Weave now brings sessions, turns, steps, tools, and sub-agents as first-class concepts, making it much easier to navigate an agent session the way the agent actually executed it.
Flexible evaluation framework
Iterating on agent context, harnesses and models without rigorous evaluation is a guessing game. Wins in one area can quietly regress others. Measure every improvement to your harnesses and models with confidence with a flexible imperative evaluation API. Weave provides powerful evaluation comparisons and visualizations to catch regressions before they reach users and keeps the iteration loop linear.
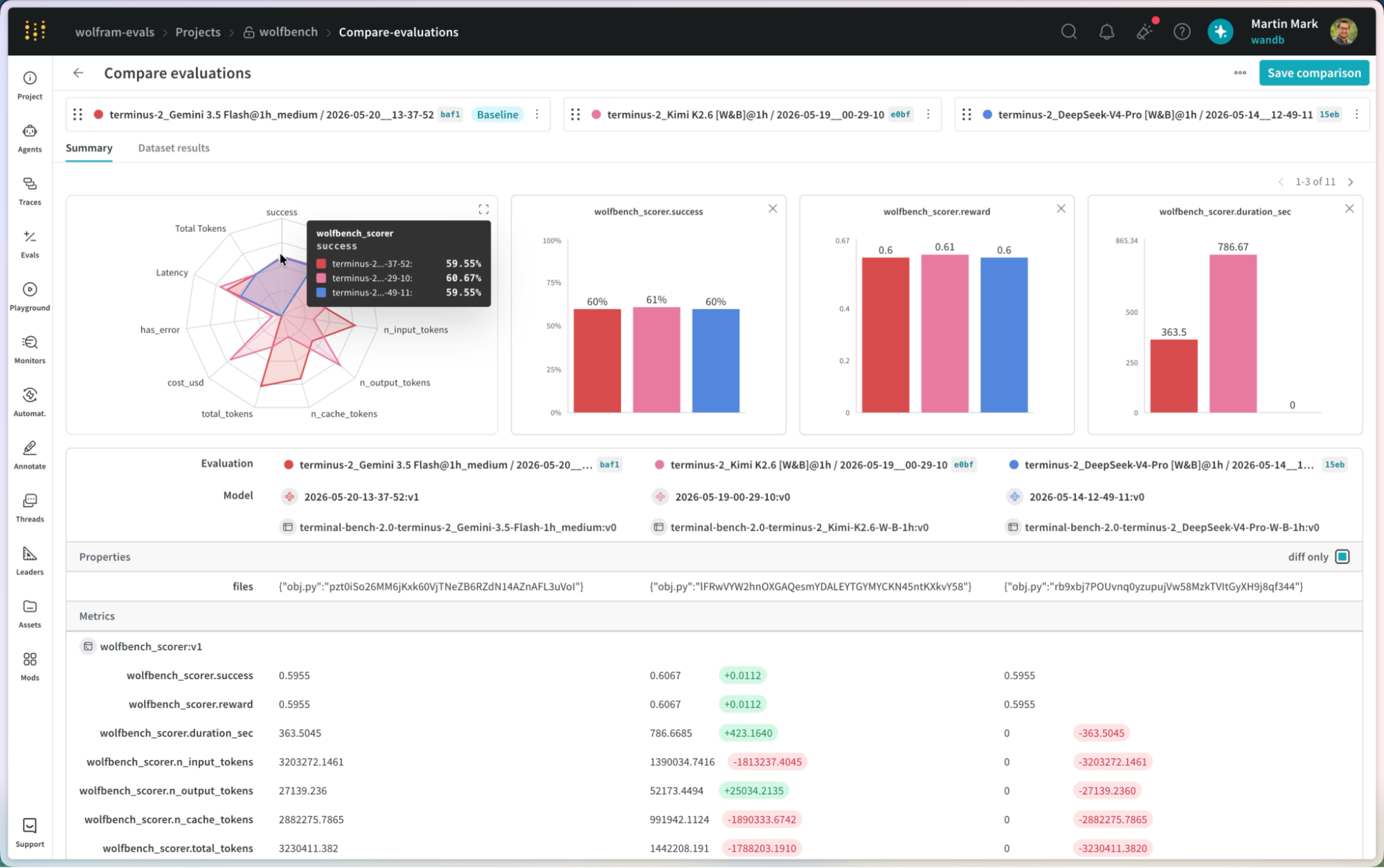
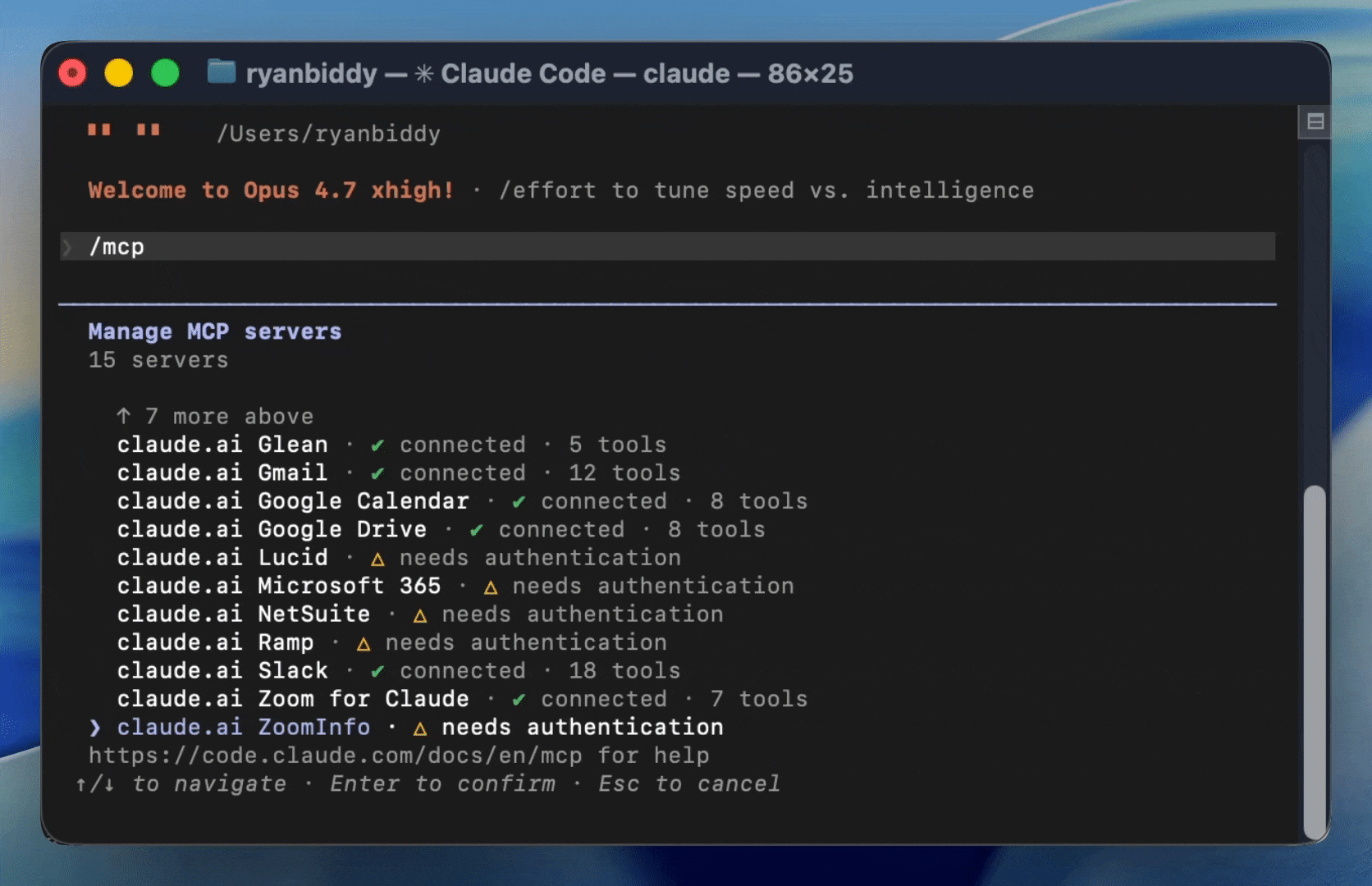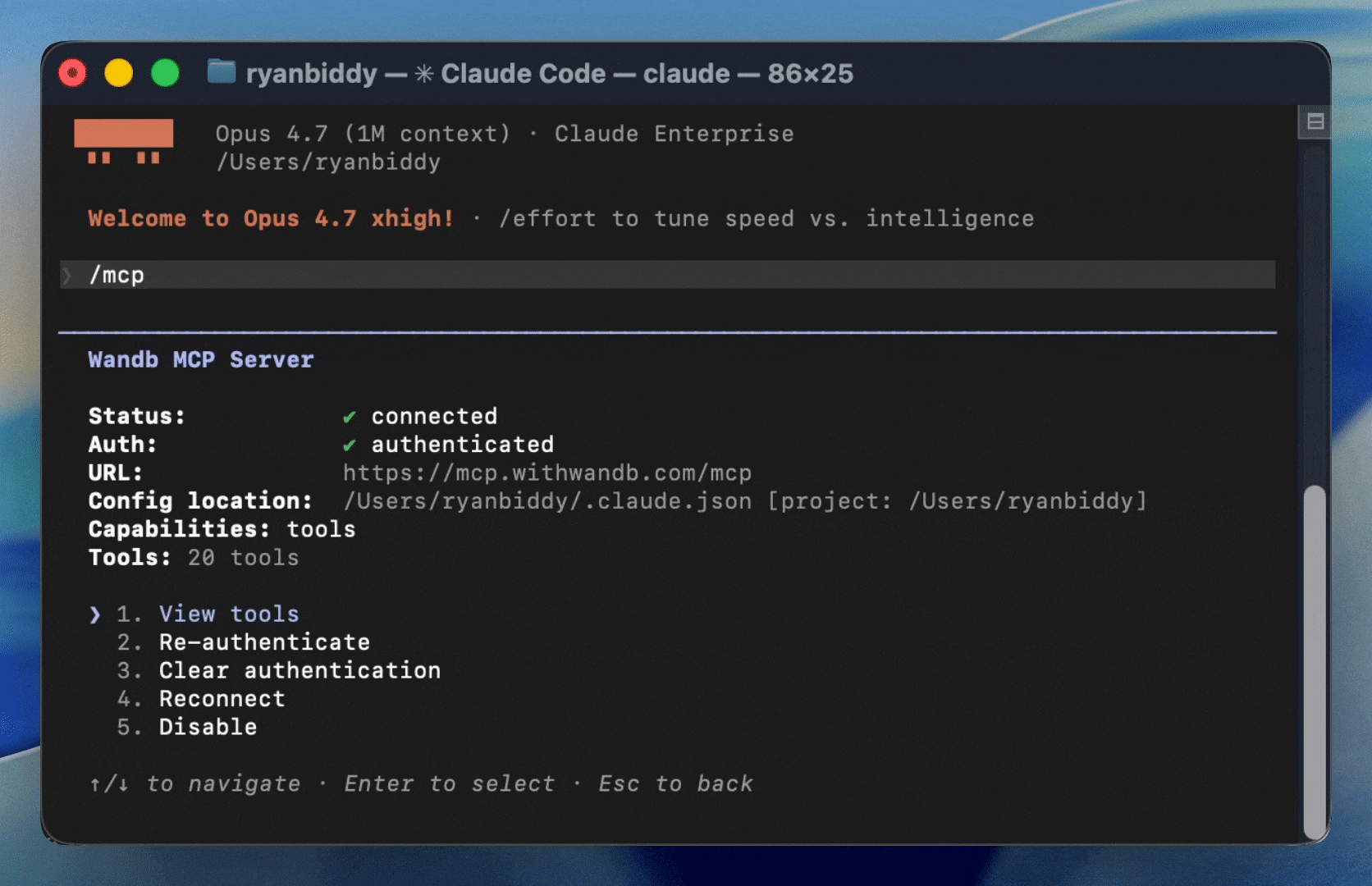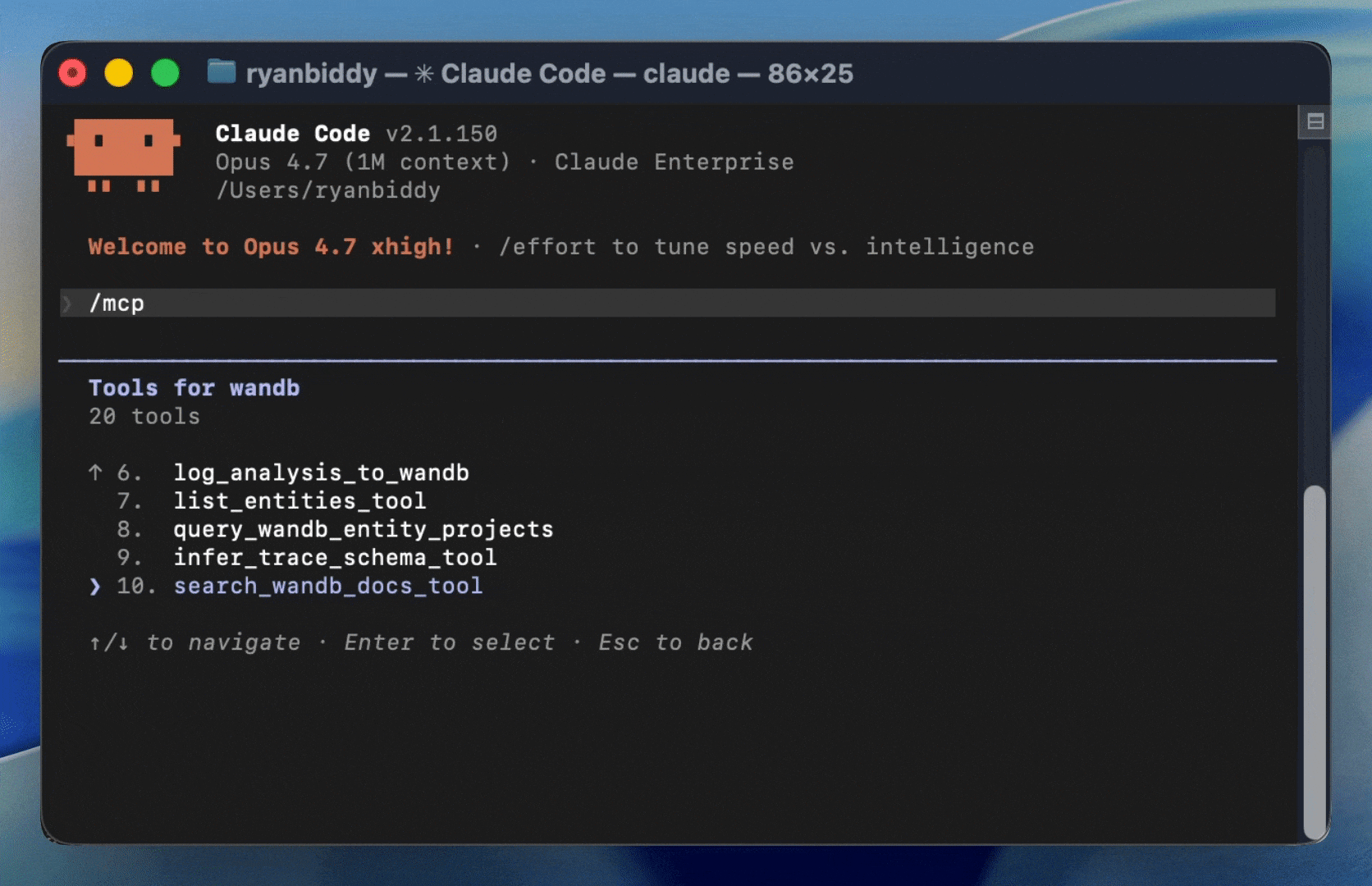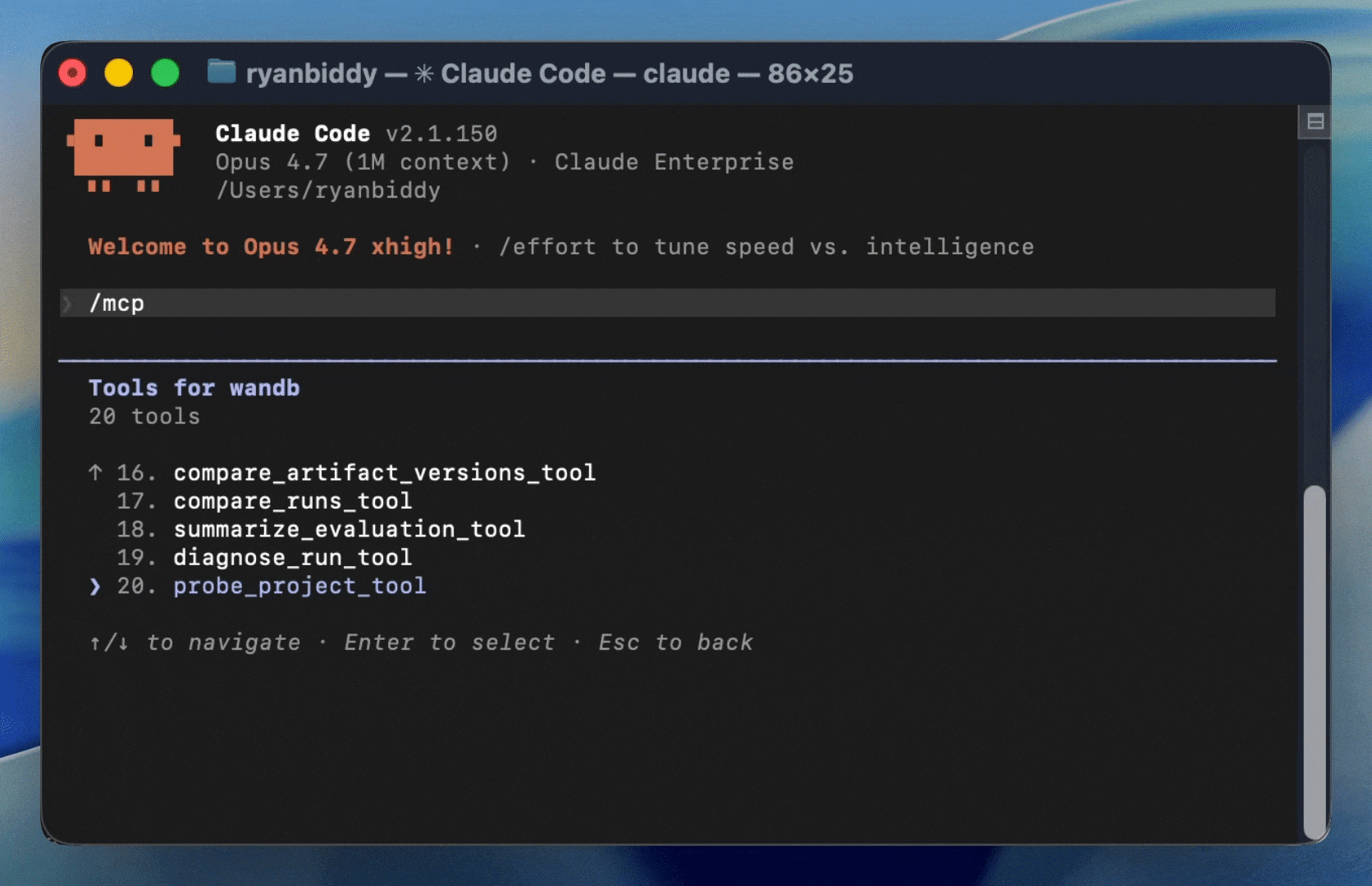
Enable autonomous improvement
Automatic self-improvement inspired by Andrej Karpathy’s autoresearch is becoming essential not only to keep pace, but to pull ahead. Using W&B skills and the MCP server, coding agents like Claude Code connect to Weave. They can read live production data, run evaluations, and execute automatic iteration loops on their own, driving exponentially compounding improvement in reliability.
Iterate on prompts and models with Playground
Playground lets you explore models and prompting techniques before building an AI agent or application, as well as troubleshoot prompts to resolve production issues. You can test new LLMs and custom models against production traces, assessing their performance for your specific use cases.

Safeguard your users and brand with Guardrails
Weave Guardrails offers pre-built scorers for safety and quality to support responsible AI. Safety scorers include toxicity, bias, PII detection, and hallucinations, and quality scores include coherence, fluency and context relevance.
Find the best models for your use case with Leaderboards
Aggregate evaluations into leaderboards featuring the best performers and share them across your organization.

Get started with Weave
Explore Weights & Biases
Learn more about Weave
The Weights & Biases platform helps you streamline your workflow from end to end
Models
Experiments
Track and visualize your ML experiments
Sweeps
Optimize your hyperparameters
Registry
Publish and share your ML models and datasets
Automations
Trigger workflows automatically
Weave
Traces
Explore and
debug LLMs
Evaluations
Rigorous evaluations of GenAI applications