
"W&B is a much better home for our experimentation results. Plus it’s super easy to use."

Dan Nissenbaum
Principle Research Software Development Engineer
An ink-first experience with Journal
Microsoft Journal is designed from the ground up to be an amazing freeform ink notetaking experience using touch and pen on Windows. This means user experience adaptations like large touch surfaces, ink-ready inputs for micro-interactions like searching or creating a new journal, and of course, the page-based canvas that leans so heavily on the familiarity of a paper notebook. But it also means using machine learning models to understand the natural gestures that people make while inking and the intrinsic structure in the content they create to provide an experience perfectly suited for journaling using only touch and pen as outputs.
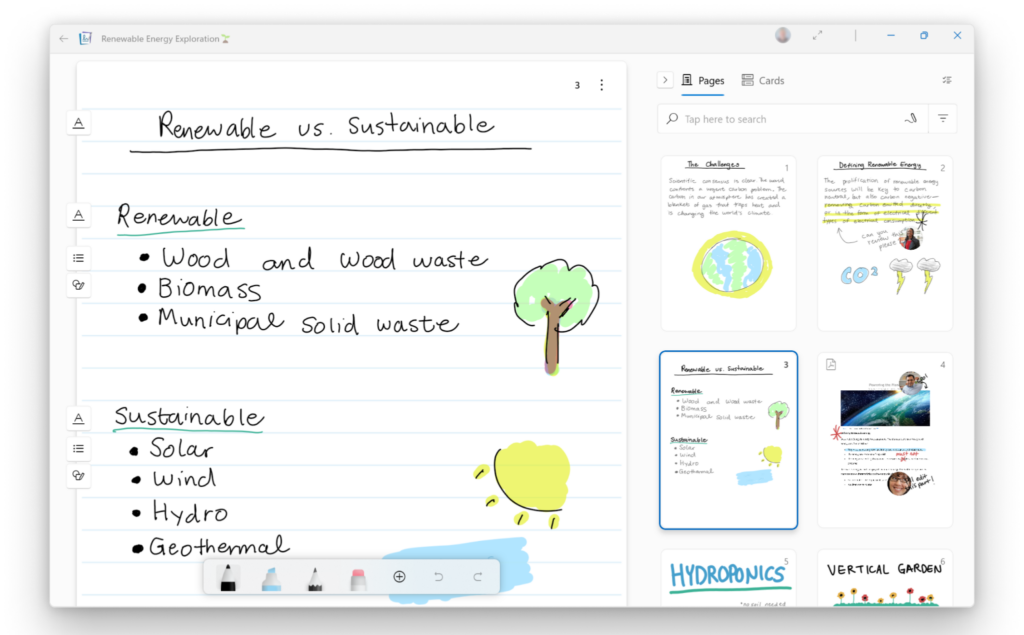
Think about the way you jot down a note during a meeting. In addition to writing words, sentences, and paragraphs, you might also underline headings, create lists, and draw diagrams. You might scribble out a mistake or annotate your notes with other notes. Journal needs to understand not just the words that you have written, but the structure, relationship, and meaning of all these components of your notes so that it can offer delightful and seamless real-time experiences like scratching out to erase or tapping to progressively select larger scopes of related content.
Here’s where it gets complicated. The boundaries of content on a freeform canvas are not crisp. For example, diagrams can be related to and also contain words. So, where does the diagram begin and end? Or, a star on the edge of a page can be used to highlight important content. But what is that star associated with? The list item or the whole list? And which ink strokes are a star anyway? None of the structure or meaning behind these constructs is conveyed in the underlying ink stroke data.
The more you consider what actual real-world notes look like, the more issues you’ll see cropping up. So how did the Journal team build the algorithm that made the product work the way their designers intended? With clever modeling and a whole lot of smart collaboration with Weights & Biases.
Embracing Remote Collaboration with W&B
Let’s start with a reality we all understand: teams are more distributed than ever and knowledge sharing is more difficult because of this. In turn, this makes collaboration more difficult. For machine learning practitioners, this challenge is even heftier. That’s because the data they’re using is often in different places and different states of readiness. Model training times for a project like this can take weeks and missteps and misunderstandings can add months to product development.
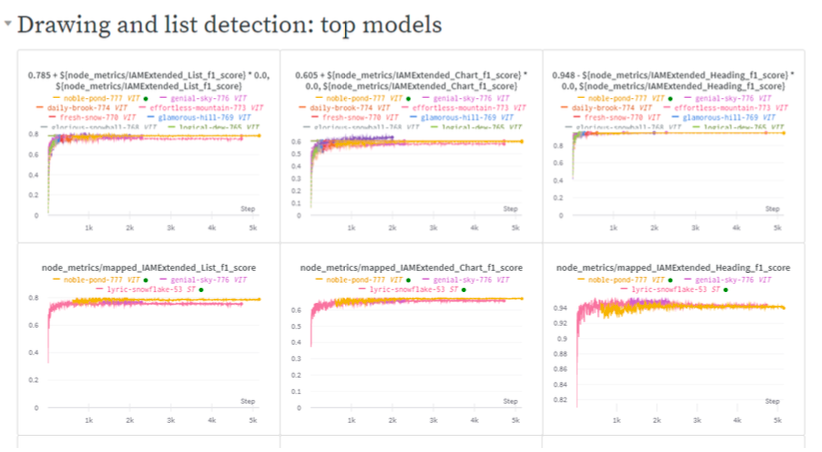
“The simple things about the platform continue to impress me,” said Dan Nissenbaum, Principle Research Software Development Engineer. “It’s nice to not have to worry about asking ‘hey, what data are we using? Is it version 16 or 17?’” Instead, the team is just pulling from W&B Artifacts for their single-stroke data.
One way to think about Artifacts is that they’re bookmarks in time. From a single Artifact, you know what data was used downstream for training, what augmentations it went through, what dependencies it’s relying on, and even, simply, what dataset you’re actually using.
For example, as you’d probably expect, some of the training data for the Ink models were augmented. Ink strokes are inherently messy, so augmentations such as skewing the stroke, adding jitter, and zooming in are just as important as they are for real-world images. But when training, it’s vital to know if that data’s been cleaned, if it’s augmented–essentially, where does this live in the pipeline? Is it new? Old? Simply understanding the lineage of data is vital for any project, but for projects with long training times and terabytes of data, mistakes here are even more costly.
With a clever use of Artifacts that Dan called “Porcelain,” W&B provided the building blocks so he could build out a system that called single-stroke data from disparate locations across their org and immediately understand its lineage and dependencies so the team could spend less time double and triple-checking if they were using the latest information and instead just know that they were. Remember, Artifacts are customizable and can log the information that’s valuable to your team. They’re a bookmark in time that lets their whole team understand a shared ground truth. As he put it, it’s a “rock solid versioning system to make sure data is tracked and not corrupted.” Simple but inherently powerful.
Knowing–not guessing–that you’re working with what you’re supposed to be working with makes collaboration so much easier. You can be assured your colleague is working with the same data you are, even if they’re a few time zones away, simply by calling the same Artifact.
Past that, W&B also made model training more transparent. Instead of knowing just where the data came from, W&B made it easy to see if things were overfitting so they could stop training runs earlier instead of later, saving valuable compute and valuable iteration time. They could simply see what they were doing, what their team was doing, and made smarter decisions with vastly more information than what some screenshots and spreadsheets provide. The Journal team ran all their experiments through W&B too, finding it a massive upgrade over Tensorboard.
“We were drawn to W&B because we realized our existing approach just didn’t work with a remote team and an increasing number of training servers with so many runs to keep track of, often separated by months,” Dan said. “W&B is a much better home for our experimentation results. Plus it’s super easy to use.”
Making the Complex Simple
In summary, Microsoft simplified a complex process and gave the team confidence that they were working with the right information at the right time. And, they solidified a process of neural network experimentation to make it easy to visualize hundreds of variations both while they run and months later for easy comparison, all with complete understanding of data and model lineage. Like Dan said, sometimes, the simple things are indeed the most important.