
„W&B ist ein viel besserer Ort für unsere Experimentierergebnisse. Außerdem ist es super einfach zu bedienen.“

Dan Nissenbaum
Leitender Forschungs- und Softwareentwicklungsingenieur
Ein Tintenerlebnis mit Journal
Microsoft Journal wurde von Grund auf als fantastisches Erlebnis zum Freihandschreiben von Notizen mithilfe von Touch und Stift unter Windows konzipiert. Dies bedeutet Anpassungen der Benutzererfahrung wie große Touch-Oberflächen, tintenfähige Eingaben für Mikrointeraktionen wie das Suchen oder Erstellen eines neuen Journals und natürlich die seitenbasierte Leinwand, die so stark auf der Vertrautheit eines Notizbuchs aus Papier basiert. Es bedeutet aber auch, Modelle des maschinellen Lernens zu verwenden, um die natürlichen Gesten zu verstehen, die Menschen beim Schreiben von Notizen machen, und die inhärente Struktur des von ihnen erstellten Inhalts, um ein Erlebnis zu bieten, das perfekt zum Journaling geeignet ist, bei dem nur Touch und Stift als Ausgabe verwendet werden.
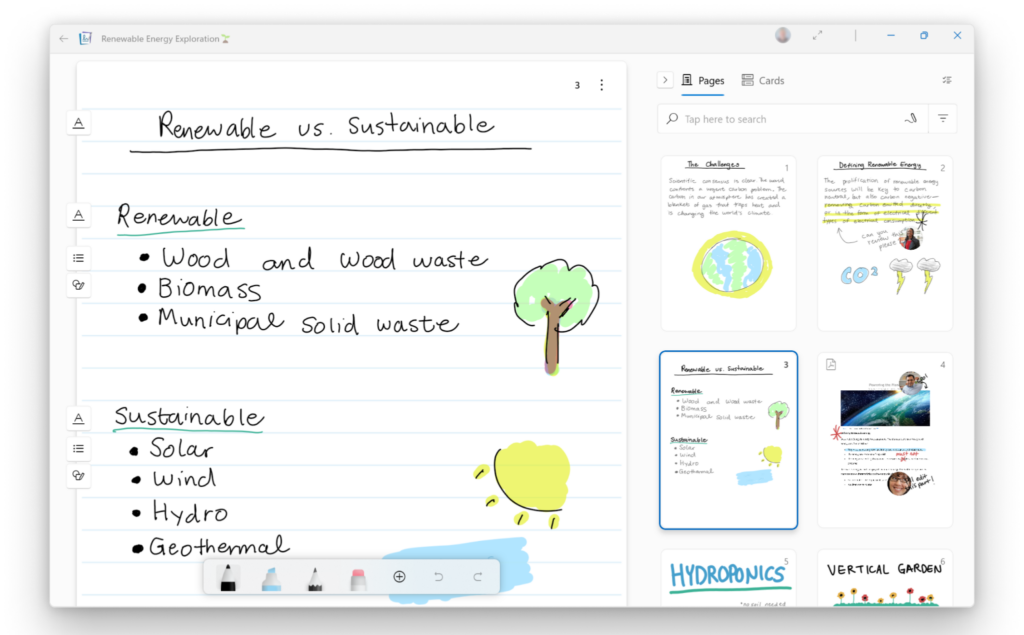
Denken Sie darüber nach, wie Sie sich während eines Meetings Notizen machen. Neben dem Schreiben von Wörtern, Sätzen und Absätzen unterstreichen Sie möglicherweise auch Überschriften, erstellen Listen und zeichnen Diagramme. Sie streichen möglicherweise einen Fehler durch oder kommentieren Ihre Notizen mit anderen Notizen. Journal muss nicht nur die Wörter verstehen, die Sie geschrieben haben, sondern auch die Struktur, Beziehung und Bedeutung all dieser Komponenten Ihrer Notizen, damit es angenehme und nahtlose Echtzeiterlebnisse bieten kann, wie das Durchstreichen zum Löschen oder das Tippen, um nach und nach größere Bereiche verwandter Inhalte auszuwählen.
Hier wird es kompliziert. Die Grenzen des Inhalts auf einer Freiform-Leinwand sind nicht scharf. Diagramme können beispielsweise mit Wörtern verknüpft sein und auch Wörter enthalten. Wo also beginnt und endet das Diagramm? Oder ein Stern am Rand einer Seite kann verwendet werden, um wichtigen Inhalt hervorzuheben. Aber womit ist dieser Stern verknüpft? Mit dem Listenelement oder mit der gesamten Liste? Und welche Tintenstriche sind überhaupt Sterne? Nichts von der Struktur oder Bedeutung hinter diesen Konstrukten wird in den zugrunde liegenden Tintenstrichdaten übermittelt.
Je mehr Sie sich überlegen, wie echte Notizen aussehen, desto mehr Probleme werden Sie feststellen. Wie also hat das Journal-Team den Algorithmus entwickelt, mit dem das Produkt so funktioniert, wie es die Designer beabsichtigt haben? Mit cleverer Modellierung und einer Menge intelligenter Zusammenarbeit mit Weights & Biases.
Remote-Zusammenarbeit mit W&B
Beginnen wir mit einer Realität, die wir alle kennen: Teams sind verteilter als je zuvor und deshalb ist der Wissensaustausch schwieriger. Dies wiederum erschwert die Zusammenarbeit. Für Machine-Learning-Experten ist diese Herausforderung sogar noch größer. Das liegt daran, dass die von ihnen verwendeten Daten oft an unterschiedlichen Orten und in unterschiedlichen Bereitschaftszuständen vorliegen. Die Modelltrainingszeiten für ein Projekt wie dieses können Wochen dauern und Fehltritte und Missverständnisse können die Produktentwicklung um Monate verlängern.
„Die einfachen Dinge an der Plattform beeindrucken mich immer wieder“, sagte Dan Nissenbaum, Principal Research Software Development Engineer. „Es ist schön, sich keine Gedanken darüber machen zu müssen, ‚hey, welche Daten verwenden wir? Ist es Version 16 oder 17?‘“ Stattdessen greift das Team für seine Einzelstrichdaten einfach auf W&B Artifacts zurück.
Man kann sich Artefakte als Lesezeichen in der Zeit vorstellen. Anhand eines einzelnen Artefakts wissen Sie, welche Daten später für das Training verwendet wurden, welche Erweiterungen sie durchlaufen haben, auf welche Abhängigkeiten sie sich stützen und sogar ganz einfach, welchen Datensatz Sie tatsächlich verwenden.
Wie Sie wahrscheinlich erwarten würden, wurden beispielsweise einige der Trainingsdaten für die Ink-Modelle erweitert. Tintenstriche sind von Natur aus chaotisch, daher sind Erweiterungen wie das Verzerren des Strichs, das Hinzufügen von Jitter und das Vergrößern genauso wichtig wie bei echten Bildern. Beim Training ist es jedoch entscheidend zu wissen, ob diese Daten bereinigt oder erweitert wurden – im Wesentlichen, wo befinden sie sich in der Pipeline? Sind sie neu? Alt? Das einfache Verständnis der Datenherkunft ist für jedes Projekt von entscheidender Bedeutung, aber bei Projekten mit langen Trainingszeiten und Terabyte an Daten sind Fehler hier noch kostspieliger.
Durch geschickten Einsatz von Artefakten, die Dan „Porzellan“ nannte, lieferte W&B die Bausteine, mit denen er ein System aufbauen konnte, das Einzeldaten von unterschiedlichen Standorten in der gesamten Organisation abruft und deren Herkunft und Abhängigkeiten sofort erkennt. So muss das Team weniger Zeit damit verbringen, doppelt und dreifach zu prüfen, ob es die neuesten Informationen verwendet, und kann stattdessen einfach wissen, dass dies der Fall ist. Denken Sie daran, dass Artefakte anpassbar sind und die Informationen protokollieren können, die für Ihr Team wertvoll sind. Sie sind ein Lesezeichen in der Zeit, das dem gesamten Team eine gemeinsame Grundwahrheit vermittelt. Wie er es ausdrückte, ist es ein „grundsolides Versionierungssystem, das sicherstellt, dass Daten verfolgt und nicht beschädigt werden“. Einfach, aber von Natur aus leistungsstark.
Wenn Sie wissen – und nicht raten –, dass Sie mit dem arbeiten, womit Sie arbeiten sollen, wird die Zusammenarbeit viel einfacher. Sie können sicher sein, dass Ihr Kollege mit denselben Daten arbeitet wie Sie, selbst wenn er sich mehrere Zeitzonen entfernt befindet, indem er einfach dasselbe Artefakt aufruft.
Darüber hinaus machte W&B das Modelltraining transparenter. Anstatt einfach zu wissen, woher die Daten kamen, konnte man mit W&B leicht erkennen, ob es zu Überanpassungen kam. So konnten die Trainingsläufe früher statt später beendet werden, was wertvolle Rechenleistung und Iterationszeit sparte. Sie konnten einfach sehen, was sie taten, was ihr Team tat, und mit weitaus mehr Informationen, als manche Screenshots und Tabellenkalkulationen liefern, intelligentere Entscheidungen treffen. Das Journal-Team führte alle seine Experimente ebenfalls mit W&B durch und fand, dass es eine enorme Verbesserung gegenüber Tensorboard darstellte.
„Wir haben uns für W&B entschieden, weil wir erkannt haben, dass unser bisheriger Ansatz mit einem Remote-Team und einer zunehmenden Anzahl von Trainingsservern mit so vielen Läufen, die oft Monate auseinander liegen und die im Auge behalten werden müssen, einfach nicht funktioniert“, sagte Dan. „W&B ist ein viel besserer Ort für unsere Experimentierergebnisse. Außerdem ist es super einfach zu bedienen.“
Das Komplexe einfach machen
Zusammenfassend lässt sich sagen, dass Microsoft einen komplexen Prozess vereinfacht und dem Team die Gewissheit gegeben hat, dass es zur richtigen Zeit mit den richtigen Informationen arbeitet. Außerdem haben sie einen Prozess des Experimentierens mit neuronalen Netzwerken gefestigt, um die Visualisierung von Hunderten von Variationen sowohl während der Ausführung als auch Monate später zum einfachen Vergleich zu vereinfachen – und das alles bei vollständigem Verständnis der Daten und der Modellherkunft. Wie Dan sagte, sind die einfachen Dinge manchmal tatsächlich die wichtigsten.