As data and computational resources have become more and more accessible, building Machine Learning (ML) models is not as daunting today as it once was. Thus, businesses of different sizes and industries invest in their data science teams to deliver business value through ML.
However, the real challenge goes beyond just building an ML model. In contrast to conventional software systems, the performance of ML systems can degrade faster, requiring close monitoring and frequent retraining. Thus, the key challenge is building an integrated ML pipeline and continuously operating it in production.
This article discusses how you can develop and operate ML systems by applying DevOps (Development and Operations) principles to ML systems by covering the following topics:
MLOps (ML Operations) applies DevOps principles to ML systems. More specifically, it is a set of practices, paradigms, and developer tools to help data scientists and software engineers develop and operate large-scale ML systems.
Practicing MLOps means that you advocate for collaboration, automation, and continuous improvement at all steps of building and operating an ML system. The key to successful MLOps is people, processes, and tooling. For more information on how to implement a holistic MLOps approach, you can refer to this Whitepaper.
DevOps vs. MLOps
MLOps is to ML systems what DevOps is to traditional software systems. Both are based on the same concepts of collaboration, automation, and continuous improvement. Yet the differences between common software and machine learning systems lead to different considerations. Mainly, DevOps and MLOps differ in team composition, development process, and infrastructure management.
DevOps is a set of practices, paradigms, and developer tools for developing and operating large-scale software systems. It aims to enable a flexible and efficient software development and delivery process, which helps developers reliably build and operate machine learning systems at scale, ultimately leading to better business outcomes.
This is done by setting systems in place to improve collaboration among different teams, using automation to accelerate processes, and applying continuous improvement concepts.
Two core concepts for continuous improvement in DevOps you need to know are:
- Continuous Integration (CI) is a software development practice where developers regularly merge code changes into a central repository, triggering an automated build and a set of tests to ensure that the new code doesn’t break the existing functionality. CI helps improve code quality and thus reduces the time it takes to validate and release new software updates.
- Continuous Delivery (CD) extends the principles of CI by automating the process of deploying code changes to staging or production environments. It is a software development practice where code changes are automatically prepared for a release to production after successful integration. The CD helps make the software delivery faster and more reliable and ensures that the software is always in a deployable state by providing deployment-ready build artifacts.
In traditional software development, CI/CD is used to automate testing, building, and deploying software, which can also be adapted to ML projects.
While a machine learning system is a software system, and similar practices apply in MLOps, there are significant differences between ML systems and software systems. As shown in the below figure, in traditional software systems, developers define rules and patterns that determine how the system processes and responds to specific inputs. In contrast, ML systems learn the patterns and relationships between the inputs and outputs through training.
DevOps vs MLOps: Team Composition
One difference between DevOps and MLOps lies in their team composition. While some roles are present in both, some are unique to MLOps teams.
Typical roles in both DevOps and MLOps teams are:
- Product Manager: Defines what solutions to build and works with different stakeholders to prioritize and execute projects.
- Software Engineer: Specializes in software engineering and building production-ready solutions. Also integrates ML capabilities into existing applications in MLOps.
- DevOps/MLOps engineer: Deploys and monitors production systems, including ML platforms in MLOps.
MLOps teams include a few additional roles to accommodate the unique nature of ML projects:
- Data Engineer: Manages the data infrastructure and builds data pipelines, aggregation, storage, and monitoring.
- Data Scientist and Machine Learning Engineer: Develops, trains, and evaluates ML models.
For an in-depth explanation of the roles in an ML project, you can learn more in Lecture 13 of The Full Stack’s “Deep Learning Course.”
DevOps vs MLOps: Development Process
This section covers some of the considerations and challenges unique to MLOps by discussing which aspects of developing an ML system are different from developing software systems and their implications:
- Development: Unlike developing a software system, developing a machine learning model is an experimental process. The development of an ML model is an iterative process that involves running many experiments with different features, models, and hyperparameter configurations to find the best-performing solution for the business case.
- Validation and testing: While CI in DevOps typically involves unit and integration tests to test and validate code and components, in MLOps, you also need to test and validate data and models.
- Deployment: While CD in DevOps typically involves the deployment of a single software package or service, CD in MLOps can refer to the deployment of the ML model or even the deployment of an entire ML pipeline, which automatically deploys an ML system, depending on the level of MLOps.
- Production monitoring: Unlike common software systems, ML systems can break more quickly after they are deployed. The performance of an ML model is sensitive to shifts in the feature distribution as well as the data distribution. Thus, the model’s performance and the distribution of input data need to be monitored in production to be able to react with the proper countermeasures, such as rollback or model updates.
This article discusses how an MLOps pipeline considers these unique MLOps challenges in detail in the section “The MLOps Pipeline.”
DevOps vs MLOps: Infrastructure Management
DevOps and MLOps also differ in infrastructure management. The main difference lies in data storage, precisely artifact version control. Version control in DevOps and MLOps ensures traceability, reproducibility, rollback, debugging, and collaboration.
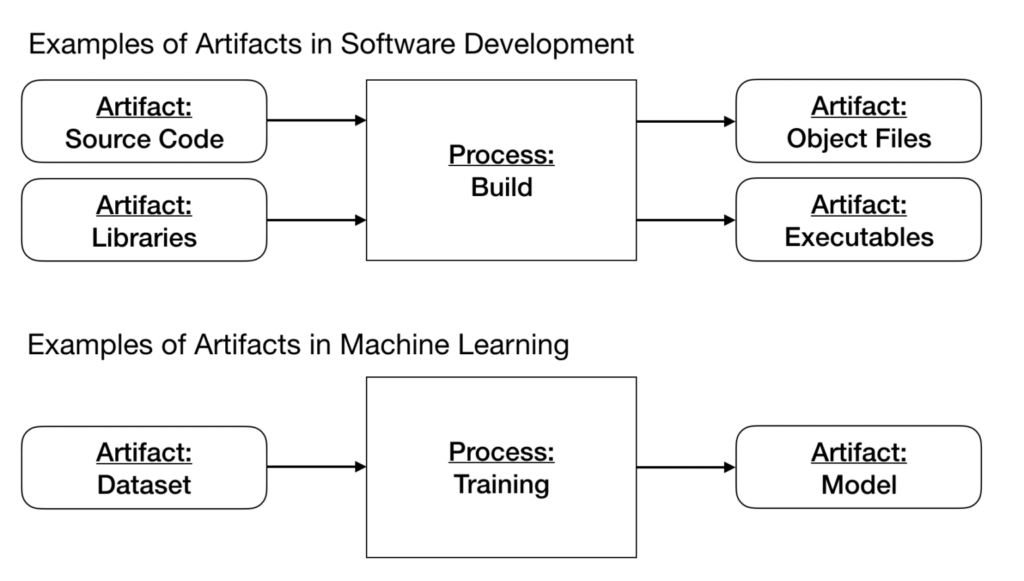
The core artifacts in a software system are source code, libraries, object files, and executables, which are versioned in a code versioning system and artifact storage. However, in an ML system, you have additional artifacts of datasets and models, which require separate versioning systems (see Intro to MLOps: Data and Model Versioning).
MLOps For Compliance and Regulations
Recently, both the European Union and US Government have started looking into meaningfully regulating machine learning and it’s a safe bet these laws are the beginning of increased scrutiny versus the end. The regulations themselves do vary in meaningful ways, but there’s some overlap here:
- Companies or federal agencies whose machine learning systems could affect fundamental rights like privacy or equal protection will face higher levels of scrutiny. As an example, models that touch on surveillance or financial fairness will almost certainly be regulated, whereas an internal LLM system that lets employees query systems likely would not.
- Larger, more impactful models are much more likely to be effective. Think of the distinction here between LLMs with billions of parameters versus something like a recommendation system.
- Data lineage and governance should be top of mind for engineers and companies building ML systems. Data should not lead to harmful outcomes that could compound over time.
Interestingly, both laws also encourage innovation, both within government and industry. They’re an attempt to regulate possible downstream ill effects but not to stymie research or blunt the cutting edge of ML.
MLOps For Audit Trails and Documentation
An experiment tracking solution that logs data and model lineage is not only table stakes for serious machine learning pipelines—it’s vital for compliance.
Compliance regimes—including the regulations above—require reporting on which data informs which models, how models were trained, and, to the extent possible, model interpretability. Spreadsheets and half measures will not satisfy those requirements.
Instead, you’re advised to track as much of the model training pipeline as possible. While this has additional benefits (think debugging, stopping poor performers early, maximizing GPU usage, etc.) being able to trace your model lineage, performance, and outputs are frequently what regulators will ask for. Weights & Biases is made to do precisely this.
The MLOps Pipeline
After the business use case is defined and its success criteria are established, the MLOps pipeline involves the following stages, as illustrated in the image below:
This section briefly discusses each of these stages. They can be completed manually or by an automatic pipeline, as discussed in the section “The Three Levels of MLOps.”
Data Engineering
In contrast to traditional software systems, ML models learn patterns from data. Thus, data is at the core of any machine learning project and the MLOps pipeline states here. The data engineering team usually conducts this stage. Before the data can be used for model training in the next stage, it needs to go through a few essential steps:
The first step is the data collection. First, you must what data you need and identify if relevant data exists and where it exists. Then you can select and collect the relevant data for your ML task from various data sources and integrate them into one cohesive format.
Next, you conduct data exploration to ensure the data quality as well as gain an understanding of the data by performing an exploratory data analysis (EDA).
- Data quality checks ensure that the data is accurate, complete, and consistent by checking e.g., distributional expectations.
- The EDA aims to gain an understanding of the data schema and characteristics and identifies the data preparation and feature engineering needed for the model (see next steps).
To enable transparency, this early-stage analysis step must be documented and reproducible. For this, you can use W&B Tables or W&B Reports.

Finally, in the data preparation step, the data is processed for the next stage of the MLOps pipeline. The data preparation can include:
- Data preprocessing, such as data cleaning, outlier handling, filling of missing values, etc.
- Feature engineering, such as aggregation features, label encoding, scaling, etc., to help the model solve the target task.
- Dataset partitioning, such as splitting the dataset into training, validation, and testing data.
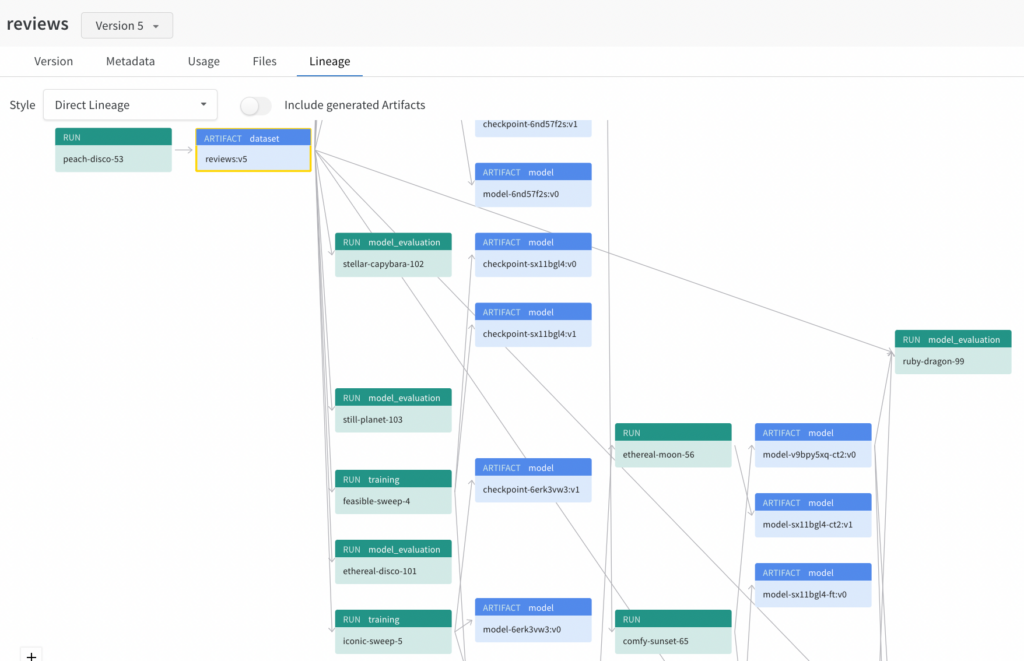
The output of this step is the data splits in the prepared format. As this step modifies the source data, it is recommended to apply some sort of data version control, such as W&B Artifacts, which is the practice of storing, tracking, and managing the changes in a dataset. This ensures the data is centralized, versioned, and easily accessible between different teams. Data versioning can also be used as a reliable record of your data that shows data sources, data usage information, and data lineage, which enables better collaboration.
Model Development
Once the data is ready, you can start developing and training your machine learning model. This stage on the MLOps pipeline requires the most ML knowledge and is usually done by the data science team. Model development is an iterative process, which requires multiple experiments on model training, evaluations, and validations on their feasibility and estimate of their business impact before making the decision on what model will be promoted to production:
As ML models learn patterns from data through a training process, model training is an integral part of model development. Usually, it is beneficial to build a simple baseline model and then iteratively improve the model e.g., by tweaking the model architecture or applying hyperparameter tuning (see Intro to MLOps: Hyperparameter Tuning). To confirm functionality and accuracy, you can e.g., use cross-validation testing.
As experimentation is an iterative process that includes iterations with different stages, it is important to establish rapid iteration and collaboration with stakeholders and different teams. To be able to collaborate, replicate an experiment, and reproduce the same results effortlessly, the training process should track datasets, metrics, hyperparameters, and algorithms through experiment tracking (see Intro to MLOps: Machine Learning Experiment Tracking). W&B Experiments can facilitate these tasks.
![]()
Next, the model goes through the model evaluation step. The purpose of model evaluation is to ensure model quality. The model quality is evaluated on a holdout test set, an additional test set that is disjoint from the training and validation sets. The output of this step is a set of logged metrics to assess the quality of the model.
The final step of the model development stage is the model validation step. The purpose of the model validation is to determine whether the model improves the current business metrics and should proceed to the deployment stage. While this step can be done manually, it is recommended to use CI/CD.
In addition to running unit and integration tests for each release, conducting A/B tests to verify that your new model is better than the current model can be useful. To enable A/B testing and observability of your deployment workflows, it is necessary to version and track your model deployment candidates, which is an artifact of the MLOps pipeline. This model artifact can be logged to a model registry, such as the W&B model registry, to record a link between the model, the input data it was trained on, and the code used to generate it.
Model Deployment
After a model is developed and its performance is confirmed for production, the next step in the MLOps pipeline is deploying the trained model to the production environment to serve predictions and realize business value.
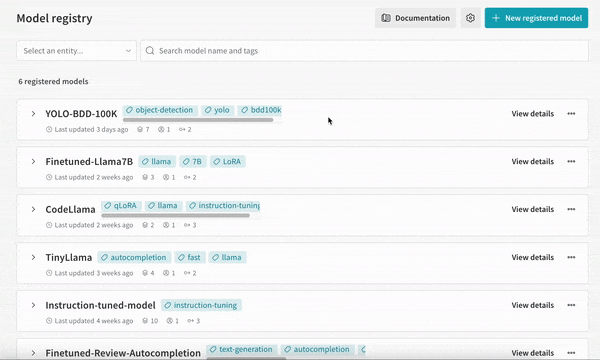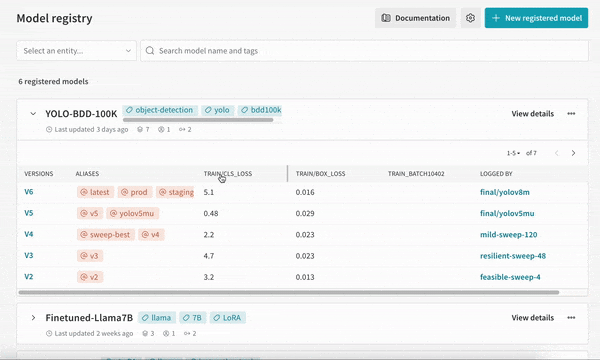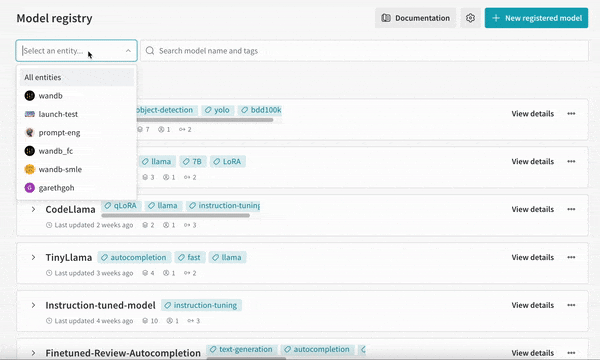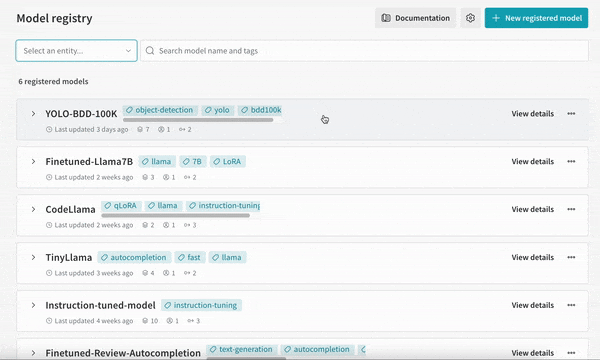
Is is when the MLOps pipeline moves to the “Ops” stage. This stage is usually conducted by the MLOps team. To enable a smooth and streamlined transition between the ML and Ops teams, the model artifact is usually stored in a model registry, such as the W&B model registry. A model registry is a central repository for models and is commonly used in model version control, which is the practice of storing, tracking, and managing the changes to an ML model.
Deploying a model to production can be done using common deployment strategies (e.g., Blue/Green Deployment, Shadow Deployment, Canary Deployment). Furthermore, deployment can be done manually or automated with a CI/CD pipeline.
Production Monitoring
Once the machine learning model has been deployed to production, it needs to be monitored to ensure that the ML model performs as expected and to detect performance decay early on.
While you could only monitor the model’s performance by monitoring the business metrics associated with your ML project, it can be helpful to also monitor the inputs to the model. By monitoring the input data distribution, you can detect and react to data drift more quickly.
Ideally, you should have automatic and systematic monitoring coupled with an alerting system when monitoring models in production. This can help you automatically trigger model retraining when necessary.
The Three Levels Of MLOps
The level of automation of these steps defines the maturity of the ML process, which reflects the velocity of training new models given new data or training new models given new implementations. The following sections describe the three levels of MLOps according to Google, starting from a completely manual level (Level 0), over a partly automated level (Level 1), up to automating both ML and CI/CD pipelines (Level 2).
Note that the following describes a simplified version of the three levels of MLOps. For more details, please refer to the original source.
Usually, organizations just starting with ML projects don’t have a lot of automation and follow a manual workflow. However, as your organization becomes more experienced with ML projects, you may want to gradually implement a more automated MLOps pipeline to drive business value.
Level 0 MLOps: Manual
In level 0 MLOps, every step and every transition in the MLOps pipeline – from data engineering to model deployment – is manual. There is no CI, nor is there any CD. The absence of automation usually results in a lack of active production monitoring.
The following diagram shows the workflow of a level 0 MLOps pipeline:
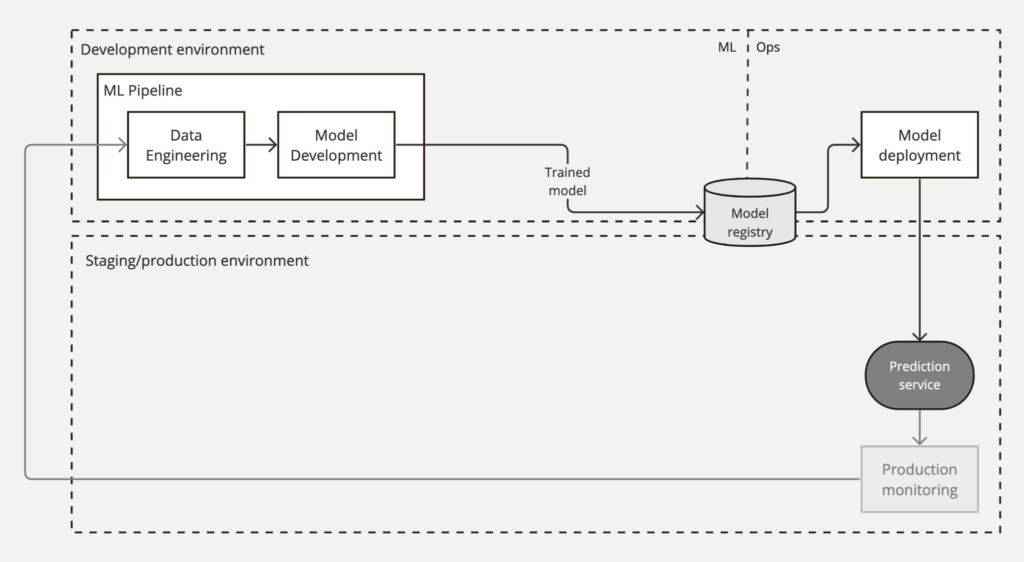
Level 0 MLOps is common in businesses just starting to use machine learning. This manual process might be sufficient when you only have a few models that rarely change (e.g., only a couple of times per year). However, in practice, ML models often break when they are deployed in the real world and need to be constantly monitored and updated frequently. Thus, active production monitoring and automating the ML pipeline can help address these challenges as described in the following level of MLOps.
Level 1 MLOps: Pipeline Automation
In level 1 MLOps, active performance monitoring is introduced and the MLOps pipeline is automated to continuously re-train the model on specific triggers and to achieve CD of the model. For this, you need to introduce automated data and model validation steps and pipeline triggers.
The following diagram shows the workflow of a level 1 MLOps pipeline:
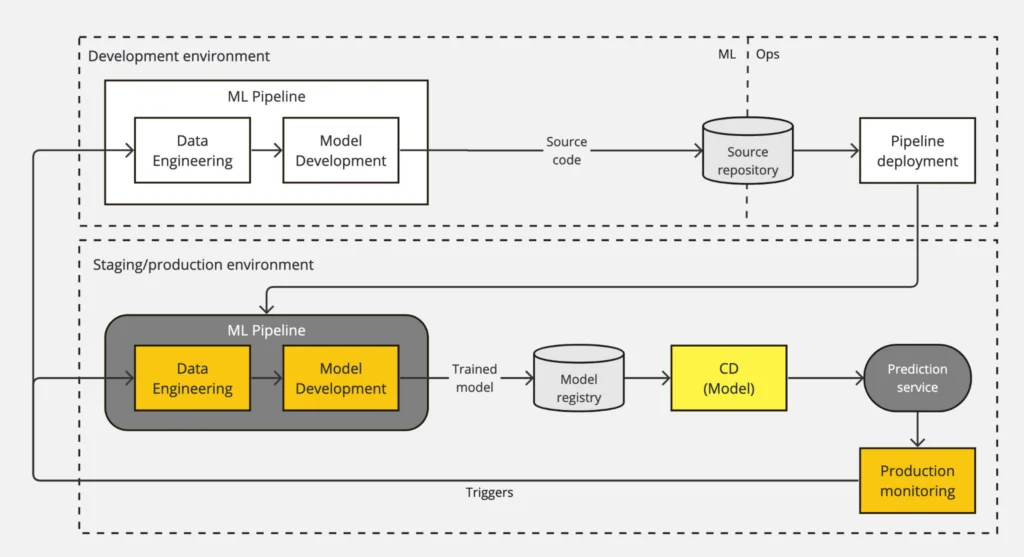
Level 1 MLOps differs from level 0 in the following aspects:
- What is deployed: Instead of deploying a trained model as a prediction service, in level 1, a whole training pipeline is deployed to production. This ML pipeline orchestrates the steps of the ML experiment and automatically and recurrently re-trains the model based on one or more triggers.
- Introduction of CD: After the ML pipeline, the model deployment is automated with CD to serve the trained model as the prediction service.
- Active Production Monitoring: Unlike level 0, level 1 introduces active production monitoring to collect input data and model performance statistics. Thus, active production monitoring requires automation of data validation and model validation steps. Ideally, the production monitoring is coupled with an alerting system that can send out triggers based on specific events.
The triggers that automatically execute the pipeline to re-train the ML model can be one or more of the following:
- On training-serving skew: At level 0, the ML and the Ops parts of the MLOps pipeline are usually disconnected. This disconnect can lead to a training-serving skew if, for example, the required features must be made available in production for low-latency serving.
- On model performance degradation: When the model performance deviates too far from the expected range.
- On data drift: When the input data distribution deviates too far from the expected values. Catching data drift early on can help improve the model before model performance degradation occurs.
- On availability of new training data: When new, freshly labeled data can be used to improve model performance.
- On new requirements: When the model must adapt to changing environments or requirements change.
- On demand: Ad-hoc manual execution of the pipeline.
- On a schedule: Scheduled execution of the pipeline (e.g., on a daily, weekly, or monthly basis). The schedule can depend on how frequently the data patterns change and how expensive it is to retrain your models.
Level 1 MLOps is common in businesses that deploy new models regularly but not frequently based on new data and only manage a few pipelines. However, if the ML model is at the core of your business, your ML team needs to constantly work on new ML ideas and improvements. To enable your ML team to rapidly build, test, and deploy new implementations of the ML components, you need a robust CI/CD setup described in the following level of MLOps.
Level 2 MLOps: CI/CD Pipeline Automation
In level 2 MLOps, the entire MLOps pipeline is an automated CI/CD system to enable data scientists to improve the ML models by rapidly iterating on new ideas rather than only on specific triggers. In addition to the CD of the ML model in level 1, CI/CD is introduced to the automated pipeline.
The following diagram shows the workflow of a level 2 MLOps pipeline.
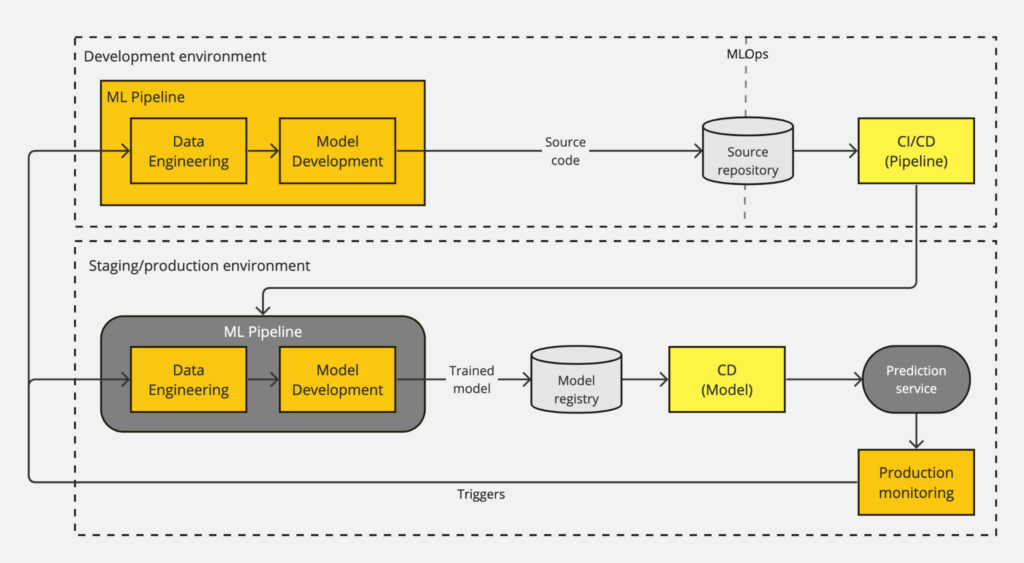
The main difference between level 2 MLOps and level 1 MLOps is the introduction of CI/CD to the MLOps pipeline. By doing this, the ML and Ops aspects are no longer disconnected. To accomplish this, the development of the ML pipeline must first be automated in parts (e.g., the data and model analysis steps are usually still manual processes). Then you can implement a CI/CD pipeline that is executed when new code for the ML pipeline is pushed to the source code repository:
- Pipeline CI: the pipeline and its components are built, tested, and packaged when new code is committed or pushed to the source code repository. The unit and integration tests also ensure that feature engineering, model training, inference, and monitoring function properly. The outputs of CI are pipeline components (packages, executables, and artifacts) to be deployed in a later stage.
- Pipeline CD: The artifacts produced by the CI stage are deployed to the target environment.
Level 2 MLOps is common in businesses with ML at their business’s core. This system allows data scientists and engineers to operate in a collaborative setting, rapidly explore new ideas, and automatically build, test, and deploy new pipeline implementations. A level 2 MLOps strategy allows frequent (daily, hourly) retraining of the model with fresh data and deploying updates to thousands of servers simultaneously.
Developing Your MLOps Strategy
There is no one-size-fits-all MLOps strategy. To develop the best MLOps strategy for your business case, you will need to establish the following:
- Defining your objectives: Are you just beginning to explore the potential of machine learning in your applications, or are you planning on having ML at the core of your business model?
- Understanding where you need to be: Your objective will determine the level of MLOps you need. How often and when do you plan to update your model? Will it be sufficient to update your ML models only on specific triggers, such as degrading performance, or do you need to stay on top of technological advances continuously to bring state-of-the-art ML capabilities to your customers?
- Team/capacity assessment: People are critical to a successful MLOps strategy. Not only is it essential to have a diverse and cross-functional team, but also to have a culture led by executives who understand how ML adds value to the business.
- Evaluating your infrastructure and environment: The required infrastructure investment highly depends on your production scale. You will not need any infrastructure if you have one simple ML application. However, as you move to larger-scale applications, potentially serving millions of requests an hour, you must move to a generalized or highly specialized infrastructure.
Having a clear picture of these points will help you develop a holistic approach to MLOps that drives business value, reduces risks, and increases the success rate for ML projects. As a first step to developing your MLOps strategy, you can start by conducting a maturity assessment based on 40 questions.
The Benefits Of A Strong MLOps Strategy
Whether your organization is just starting to experiment with machine learning projects or already building and operating ML applications at scale, having a strong MLOps strategy is a critical factor for success.
By applying the DevOps principles of collaboration, automation, and continuous improvement to your ML projects, you can achieve faster time-to-market for your ML applications, ultimately driving more business value at optimized costs and resource utilization. With a well-defined MLOps strategy, companies can bridge the gap between development and deployment, setting the stage for innovation and sustained success in the ever-evolving landscape of AI technologies.
As machine learning becomes a core component of your business, embracing MLOps becomes more than a strategic choice. It’s a necessity for organizations aiming to harness the full potential of their ML initiatives.