Confidently Iterate on GenAI Applications with Evaluations
Developers building with LLMs need to continuously evaluate the performance of their models in order to constantly iterate and deliver robust performance in production.
Use Evaluations to easily organize and compare any performance metric of your application. Measure and validate the accuracy of models across a wide variety of scenarios. Build rigor with systematic evaluations to score different aspects of your non-deterministic GenAI applications and deploy with confidence.
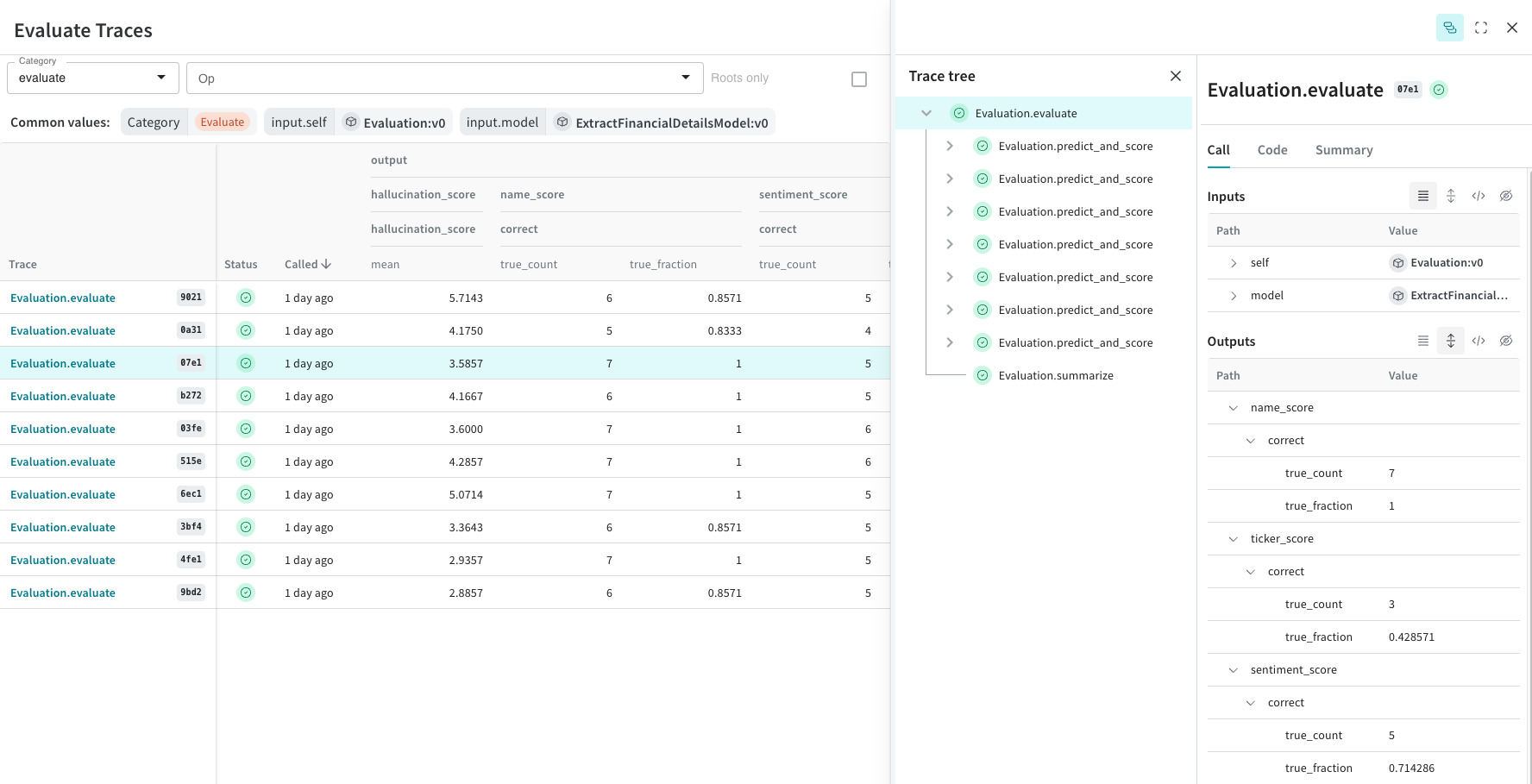
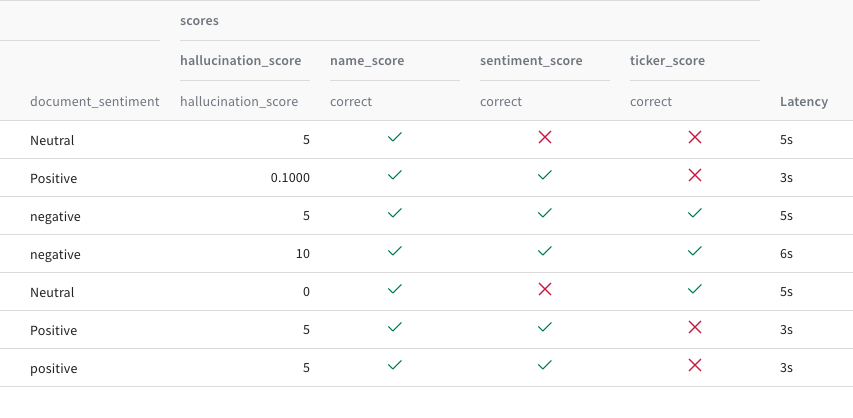
Score your GenAI applications in a lightweight, customizable way
Built with the developer experience in mind, Evaluations allows for easy logging and comparison of LLM performance. Use our scorers, or define your own Evaluations score to create functions as complex or as simple as you need for your use case in evaluating different dimensions of your application performance.
Move beyond "vibe checks"
Build out automatic evaluations so you can reliably iterate. Drill into difficult examples, see what data was used for each intermediate input, and root cause exactly where the issue lies.
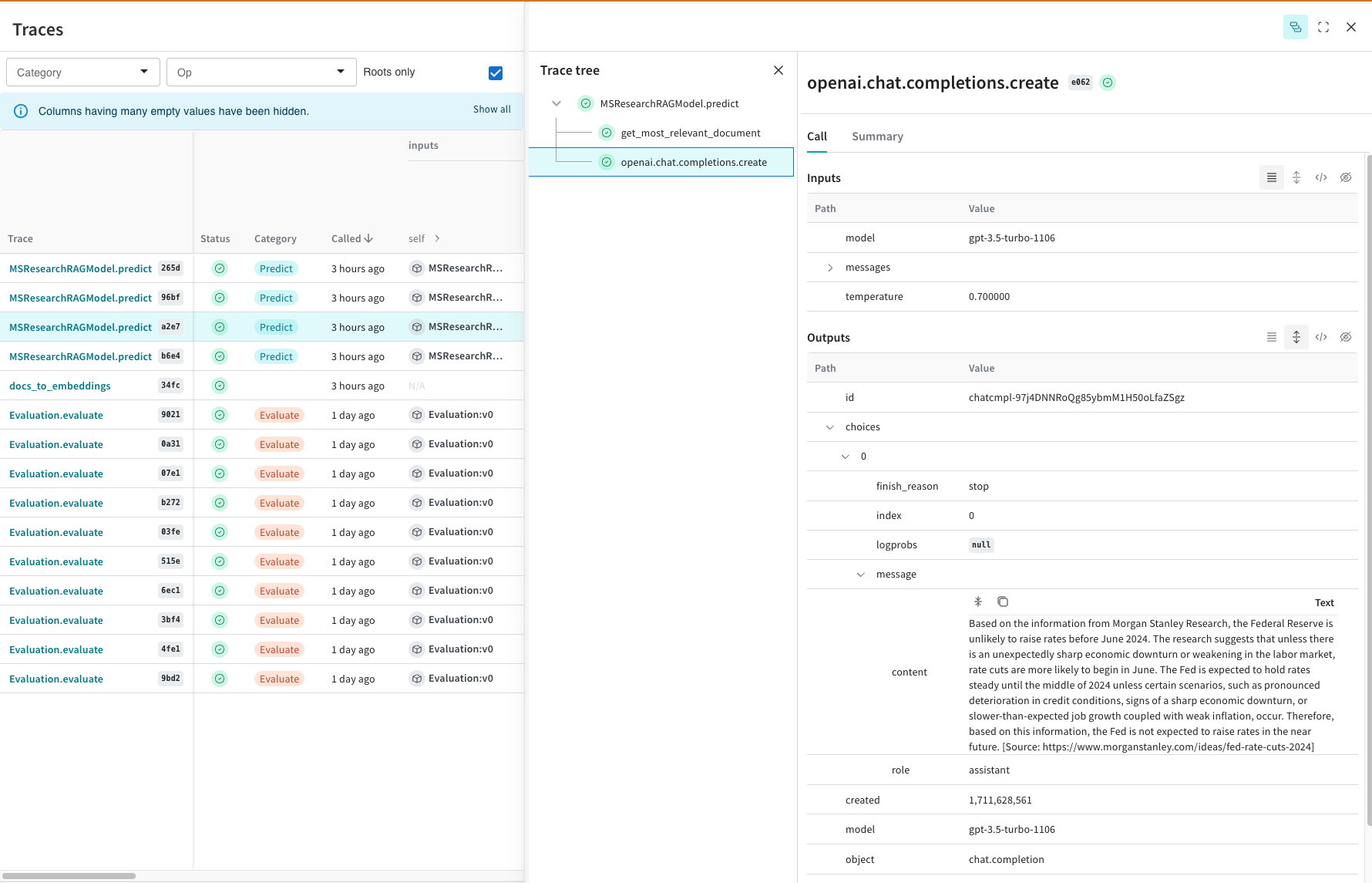
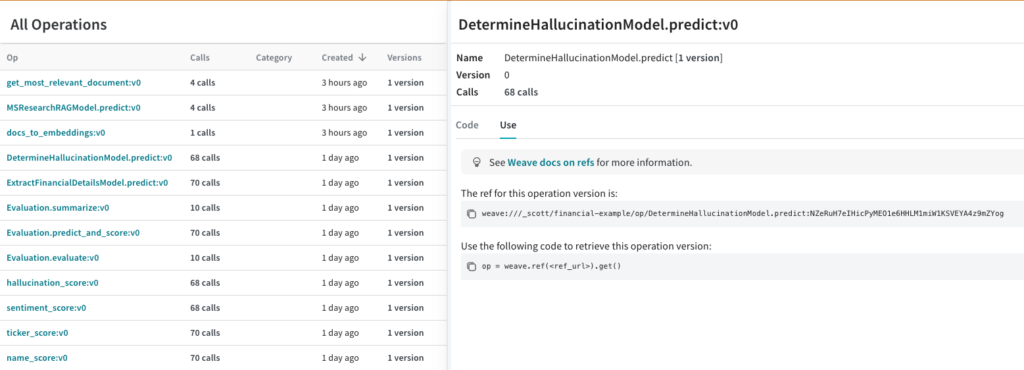
Build rigor with a systematic and organized evaluation framework
Empower your team with the confidence needed to deploy GenAI applications by tracking and managing all essential elements in one unified location. Scale up your evaluations so you can confidently experiment with the latest model, prompt or technique.
The Weights & Biases platform helps you streamline your workflow from end to end
Models
Experiments
Track and visualize your ML experiments
Sweeps
Optimize your hyperparameters
Model Registry
Register and manage your ML models
Automations
Trigger workflows automatically
Launch
Package and run your ML workflow jobs
Weave
Traces
Explore and
debug LLMs
Evaluations
Rigorous evaluations of GenAI applications