
„Durch die Verfolgung von Experimenten konnten wir unsere Geschwindigkeit verzehnfachen und die Ergebnisse viel schneller und nachvollziehbarer untereinander austauschen.“
Evan Cushing
Ingenieur für maschinelles Lernen
Der Mobilitätsmarkt entwickelt sich ständig weiter, da regelmäßig neue Verkehrsteilnehmer und Fahrzeuge wie Tretroller, Fahrzeuge der nächsten Generation, Elektrofahrräder und Mobility-as-a-Service-Systeme (MaaS) eingeführt werden und sich Fahrer und Autos entsprechend anpassen müssen.
Dieser ständige Zustand der Entwicklung ist es, der laut ML-Ingenieur Evan Cushing die Projekte, an denen er und sein Team bei Woven – einer Tochtergesellschaft der Toyota Motor Corporation für Mobilitätstechnologie, die sich auf die Förderung der Softwaretransformation innerhalb der Toyota-Gruppe konzentriert – arbeiten, so faszinierend macht.
„Wir arbeiten an wirklich interessanten, herausfordernden Problemen in einem Ausmaß, das man in keinem anderen Bereich oder Unternehmen findet“, sagte Cushing. „Was autonomes Fahren zu einem interessanten ML-Problem macht, das Tools wie Weights & Biases erfordert, ist, dass es ein hochdimensionales Problem ist. Eine dieser Herausforderungen ist die Notwendigkeit eines ML-Systems des kontinuierlichen Lernens.“
Die Mission des Teams besteht darin, sichere, intelligente und menschenzentrierte Lösungen für autonomes Fahren und Mobilität zu entwickeln. Fehlende Erkennungen stellen ein großes Sicherheitsrisiko für die Passagiere und die sie umgebende Gemeinschaft dar und setzen das Unternehmen und Evans ML-Team unter enormen Druck, innovative Modelle und Lösungen zu entwickeln.
Herausforderungen beim „Autonomy 1.0“-Workflow
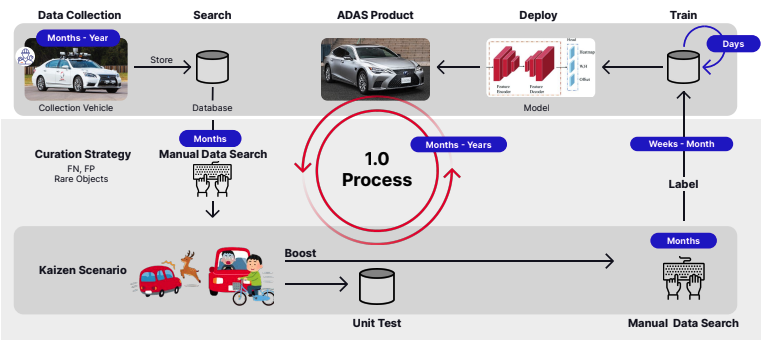 Cushing und sein Team erkannten mehrere Schwachstellen bei ihrem „1.0“-Prozess und dem traditionellen ML-Workflow für autonomes Fahren, von der Datenerfassung bis hin zu Training und Einsatz. Dazu gehörten:
Cushing und sein Team erkannten mehrere Schwachstellen bei ihrem „1.0“-Prozess und dem traditionellen ML-Workflow für autonomes Fahren, von der Datenerfassung bis hin zu Training und Einsatz. Dazu gehörten:
- Eine Methode zur Datenerfassung – bei der Testfahrzeuge feste Routen abfahren, ohne die umfangreichen und vielfältigen Datenverteilungen realer Fahrsituationen vollständig zu erfassen – war nicht skalierbar.
- Daten von Testfahrzeugen müssen manuell kuratiert werden, um sie in das Testset aufzunehmen, das zum Benchmarking verwendet wird. Teammitglieder würden Videos überprüfen, um geeignete Szenen für das Training zu finden und zu kuratieren, Kaizen-Szenarien, die für ML-Modelle oder KI-Systeme eine Herausforderung darstellen könnten, wie z. B. Tiere auf der Straße. Dies war auch nicht skalierbar.
- Ein langsamer und zeitaufwändiger Datenbeschriftungsprozess in Zusammenarbeit mit einem Datenanmerkungsdienst eines Drittanbieters, der bis zu einem Monat dauern kann.
10-fache Verbesserung durch die Anwendung der Kaizen-Prinzipien
Kaizen ist ein japanischer Begriff, der „kontinuierliche Verbesserung“ oder wörtlicher „Veränderung zum Besseren“ bedeutet. Im Kern betont es die Philosophie, im Laufe der Zeit kontinuierlich kleine, schrittweise Verbesserungen vorzunehmen, um bedeutende Fortschritte zu erzielen und gleichzeitig Verschwendung und Ineffizienzen in Prozessen zu beseitigen. Cushing sah in diesem Denkprozess den Schlüssel zur Bewältigung ihrer Herausforderungen und suchte nach Bereichen, in denen Kaizen im gesamten Arbeitsablauf implementiert werden konnte.
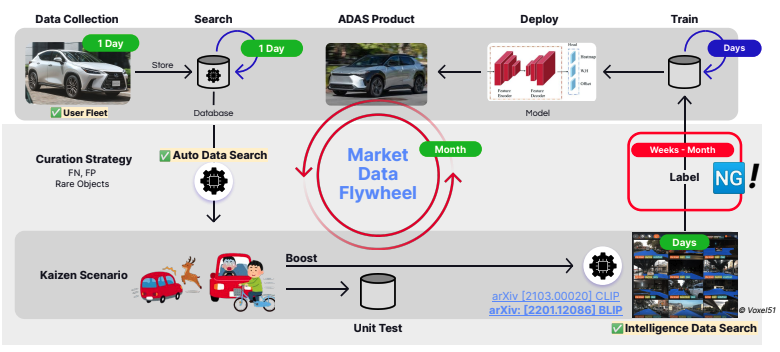
Ihre größte Verbesserung bestand darin, dass sie zur Datenerfassung auf Testfahrzeuge verzichteten und stattdessen ihre große Flotte von Kundenfahrzeugen mit Datenerfassungssensoren nutzten, was zu einer wesentlich größeren Datenmenge in viel kürzerer Zeit führte. Diese Sensoren nutzten auch automatisierte Auslöser, um Kaizen-Szenarien zu finden, beispielsweise wenn sie einen enormen Anstieg der plötzlichen G-Kraft wahrnahmen. Dies könnte möglicherweise eine unsichere Situation und eine wertvolle Szene sein, an der Modelle trainiert werden können.
Auch die automatische Beschriftung und Datensatzabfragen während des Datenkuratierungs-Workflows führten zu einer enormen Zeitersparnis von 20 auf nur 2 Monate. Das Team automatisierte die Datenannotation mithilfe von maschinellem Lernen und wies Daten automatisch Beschriftungen zu, anstatt dass Menschen Szenen zum Trainieren manuell kuratieren und annotieren mussten. Das Team konnte nun den Datensatz abfragen, um nach Szenen zu suchen, die Kaizen-Szenarien sein könnten, wie etwa „Hirsch überquert eine Straße“ oder „Kind auf einem Fahrrad“, um alle Beispiele dieses bestimmten Szenarios abzurufen.
Alle diese Bemühungen wurden während des gesamten Workflows durch ein erstklassiges ML-Framework unterstützt, das Weights & Biases als zentrales Aufzeichnungssystem, PyTorch als Kernframework, Hydra zur Verwaltung von Konfigurationen sowie eine lokale (DGX) und Cloud-Infrastruktur (AWS EC2 und SageMaker) umfasste.
Der Einfluss von Gewichtungen und Verzerrungen
Insbesondere Weights & Biases ist für Woven by Toyota zu einem unverzichtbaren Tool für die Entwicklung, Kommunikation und Zusammenarbeit an ML-Projekten über Organisationen und Produktanwendungen hinweg geworden.
„Durch die Experimentverfolgung konnten wir unsere Geschwindigkeit verzehnfachen und die Ergebnisse viel schneller und nachvollziehbarer untereinander austauschen“, sagte Cushing. „Sweeps hat uns geholfen, zuvor langwierige Prozesse zu automatisieren, und Reports hat dazu beigetragen, den Standard für gutes ML bei Toyota zu erhöhen.“
Das Team hat außerdem einige einzigartige Möglichkeiten für die Verwendung von Gewichtungen und Verzerrungen entwickelt und ist auf das gekommen, was Cushing als „wirklich lustigen Kaizen-Profi-Tipp“ beschrieb: die Verwendung von Tabellen als De-facto-Bestenliste für Modelle.
Das Team gibt Modelle an mehrere Teams und Funktionen weiter und fasst Modellläufe zusammen, die mit derselben Datensatzversion trainiert wurden. Anschließend werden sie in Tabellen nach Bewertungsmetriken sortiert, um zu sehen, wer was macht, welche Modellversionen führend sind und wer im Team die Nase vorn hat.
„Dadurch bleibt das Team auf dem Laufenden, was die Projektentwicklung angeht“, sagte Cushing. „Die Bestenliste gibt uns abteilungsübergreifend Einblick in die Daten, Techniken und Teams, die großartige Ergebnisse liefern.“
Und das Team ruht sich nicht auf seinen Lorbeeren aus, weder bei der Verwendung von Weights & Biases noch beim gesamten Autonomy 2.0-Workflow, auf den es hinarbeitet. Cushing plant eine weitere Integration in die Weights & Biases-Plattform, insbesondere mit Launch (für eine nahtlose Konnektivität zur Berechnung, um Trainings- und Inferenzjobs in noch größerem Umfang auszuführen) und dem Model Registry (um die gesamte Modellverwaltung und -bereitstellung zu zentralisieren und zu organisieren).
In der Zwischenzeit wird Autonomy 2.0 durch große Verhaltensdatensätze, bessere Offline-Simulationen zur Validierung und günstigere Hardwarekosten zur Förderung größerer Skalierbarkeit weiter verbessert. Die nahe Zukunft des autonomen Fahrens ist spannend und wird von Leuten wie Cushing und seinem Team bei Woven by Toyota angeführt.