
Grundlagen der Versionskontrolle
Bevor wir uns mit der Daten- und Modellversionierung in ML befassen, wollen wir einige allgemeine Schlüsselkonzepte der Versionskontrolle auffrischen. Wir behandeln die Definition der Versionskontrolle, einige zentrale Begriffe, warum die Versionskontrolle nützlich ist und die drei Arten der Versionskontrolle.
Was ist Versionskontrolle?
Unter Versionskontrolle versteht man die Verfolgung und Verwaltung von Änderungen, die im Laufe der Zeit an Dateien oder Projektordnern vorgenommen werden.
Einige Schlüsselkonzepte der Versionskontrolle sind:
-
Version : Eine Momentaufnahme einer Datei oder eines Projekts zu einem bestimmten Zeitpunkt.
-
Repository : Der Ort, an dem alle Versionen einer Datei oder eines Projekts gespeichert sind.
-
Commit : Der Vorgang zum Speichern einer neuen Version einer Datei oder eines Projekts im Repository.
-
Verlauf : Der Verlauf der an einer Datei oder einem Projekt vorgenommenen Änderungen, einschließlich Informationen darüber, wer was wann geändert hat (und optional, warum die Änderung erfolgte und welche Auswirkungen dies hatte).
Warum brauchen Sie eine Versionskontrolle?
Die Verwendung der Versionskontrolle geht über das Speichern verschiedener Versionen einer Datei oder eines Projekts hinaus. Ihre Hauptvorteile sind Rückverfolgbarkeit, Reproduzierbarkeit, Rollback, Debugging und Zusammenarbeit.
-
Nachvollziehbarkeit : Mit dem Verlaufsprotokoll können Sie sich schnell einen Überblick verschaffen, wer was wann geändert hat und im Idealfall die Auswirkungen einer Änderung erkennen.
-
Reproduzierbarkeit : Wenn man weiß, welche Version einer Datei oder eines Projekts zu einem bestimmten Zeitpunkt verwendet wurde, kann das dabei helfen, frühere Ergebnisse zu reproduzieren.
-
Rollback : Sie können schnell zwischen verschiedenen Versionen wechseln. Dies ist beim Rollback hilfreich, da Sie zu einer früheren stabilen Version zurückkehren können, wenn etwas schief geht.
-
Vergleichen und Debuggen : Sie können verschiedene Versionen vergleichen und sehen, was sich zwischen zwei Versionen, z. B. zwei Releases, geändert hat. Dies ist beim Debuggen hilfreich.
-
Zusammenarbeit : Je nach Art der Versionskontrolle (siehe Arten der Versionskontrolle ) kann sie die Zusammenarbeit in Teams ermöglichen. Mitwirkende können Kopien des Snapshots eines Projekts erstellen ( Branching ) und ihre Änderungen nach erfolgreichen Tests mit dem Gesamtprojekt teilen ( Merging ).
Arten der Versionskontrolle
Versionskontrolle gibt es in verschiedenen Formen mit ihren Vor- und Nachteilen. Obwohl Sie Ihre Dateien manuell versionieren können, ist die Verwendung eines Versionskontrollsystems gängige Praxis. Wir unterscheiden drei Arten von Versionskontrollsystemen: lokal, zentralisiert und verteilt.
Kommt Ihnen das folgende Bild bekannt vor? Wenn wir zum ersten Mal zwischen verschiedenen Versionen einer Datei unterscheiden müssen, speichern wir dieselbe Datei intuitiv unter unterschiedlichen Namen, um die verschiedenen Versionen voneinander zu unterscheiden.
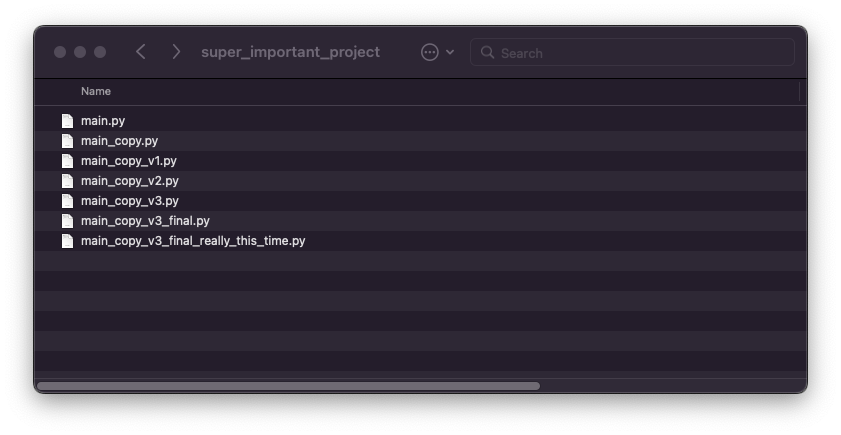
Die manuelle Versionskontrolle hat nur einen Vorteil (sie ist ziemlich einfach) und viele Nachteile (oh, so viele). Diese Art der Versionskontrolle erfordert zwar keinen Einrichtungsaufwand, aber es ist schwierig, den Änderungsverlauf nachzuvollziehen, sodass kaum Möglichkeiten zur Zusammenarbeit mit anderen bestehen. Wenn Ihre Festplatte beschädigt ist, gehen alle Änderungen verloren.
Aus diesem Grund ist es gängige Praxis, Versionskontrollsysteme zu verwenden, anstatt Dateien und Projekte manuell zu versionieren.
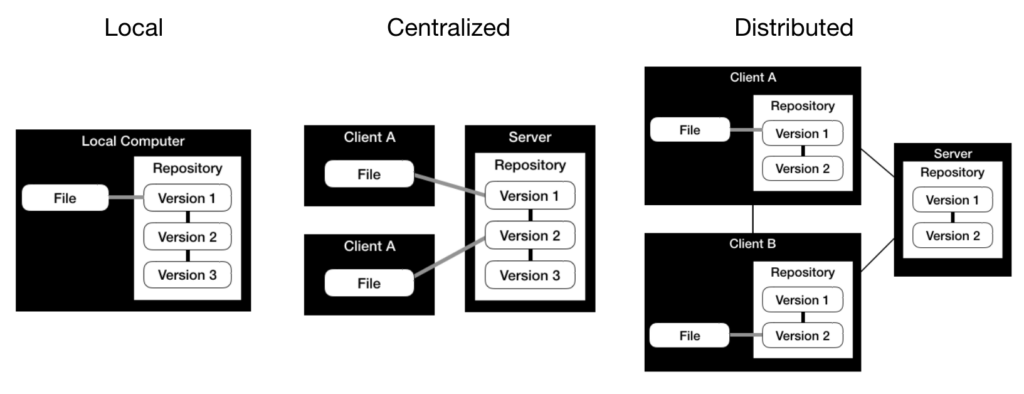
Wir unterscheiden zwischen 3 Arten von Versionskontrollsystemen, die im Folgenden visualisiert werden:
-
Lokale Versionskontrollsysteme: Sie haben ein Repository auf einem lokalen Computer. Die Vorteile liegen in der einfachen Einrichtung und Nutzung ohne Netzwerkverbindung. Das Fehlen eines zentralen Repositorys ermöglicht jedoch keine Zusammenarbeit und verfügt nur über eingeschränkte Backup-Funktionen (Single Point of Failure).
-
Zentralisierte Versionskontrollsysteme: Sie haben ein Repository auf einem zentralen Server. Versionen werden direkt in diesem zentralen Repository gespeichert. Das zentrale Repository ermöglicht die Zusammenarbeit. Es erfordert jedoch eine Netzwerkverbindung zum zentralen Repository, was auch hinsichtlich der Sicherungsfunktionen einen Single Point Failure darstellt. Ein Beispiel für ein zentralisiertes Versionskontrollsystem ist Subversion.
-
Verteilte Versionskontrollsysteme: Sie haben ein Repository auf einem zentralen Server. Clients erstellen lokale Kopien des zentralen Repositorys. Versionen werden zunächst im lokalen Repository gespeichert und später mit dem zentralen Repository synchronisiert. Das zentrale Repository ermöglicht die Zusammenarbeit, und die lokalen Kopien ermöglichen die Offline-Arbeit und verfügen über verbesserte Sicherungsfunktionen. Eine lokale Kopie des vollständigen Repositorys erfordert jedoch auch mehr Speicherplatz. Beispiele für verteilte Versionskontrollsysteme sind Git oder Mercurial.
Versionskontrolle im maschinellen Lernen
Versionskontrolle ist nicht nur bei der Softwareentwicklung nützlich, sondern auch im Entwicklungsprozess von ML-Modellen. In ML ist die Versionierung des Quellcodes genauso wichtig wie die Versionierung von Artefakten wie Datensätzen und Modellen.
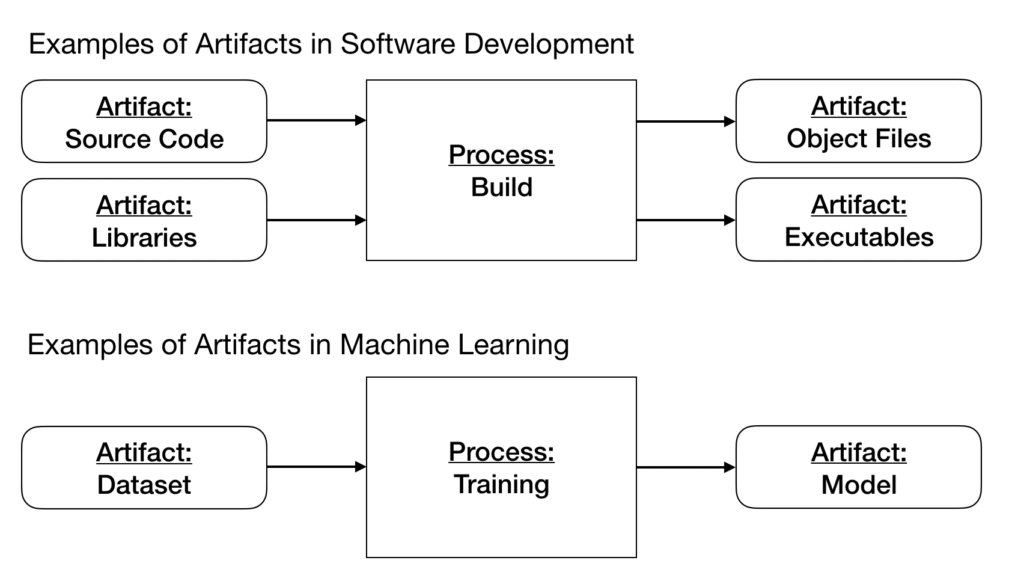
Während des Entwicklungsprozesses eines ML-Modells erstellen wir andere Artefakte als Quellcode. Ein Artefakt ist jede Datei, die eine Eingabe oder Ausgabe eines Prozesses ist. Beispiele für Artefakte in der Softwareentwicklung, die Eingaben sind, sind Quellcode und Bibliotheken als Eingaben eines Prozesses. Im Gegensatz dazu sind Objektdateien und ausführbare Dateien Beispielartefakte, die Ausgaben eines Prozesses sind. In diesem Beispiel ist der Prozess ein Build-Prozess.
Im ML sind Datensätze und Modelle die wichtigsten Artefakte. Ein Datensatz wäre beispielsweise ein Artefakt, das eine Eingabe eines Trainingsprozesses ist, während ein Modell ein Artefakt wäre, das eine Ausgabe davon ist.
Die folgenden Abschnitte behandeln die Versionskontrolle für Datensätze und ML-Modelle. Das Kernkonzept ist hier bei der allgemeinen Versionskontrolle und der Versionskontrolle für Daten und Modelle ähnlich. Anstatt die Konzepte der Rückverfolgbarkeit, Reproduzierbarkeit, des Rollbacks, des Debuggens und der Zusammenarbeit für Daten und Modelle anstelle des Quellcodes zu wiederholen, konzentrieren wir uns darauf, wann sich Daten und Modelle ändern und versioniert werden müssen.
Datenversionskontrolle
Während die Versionskontrolle normalerweise mit Quellcode in Verbindung gebracht wird, bezeichnet die Modellversionskontrolle oder Modellversionierung speziell die Versionskontrolle von Daten in ML. Es beschreibt die Praxis des Speicherns, Verfolgens und Verwaltens der Änderungen in einem Datensatz.
Bei folgenden Ereignissen kann während der Modellentwicklung eine neue Version eines Datensatzes gespeichert werden:
-
Datenvorverarbeitung (Änderungen des Dateninhalts) wie etwa Datenbereinigung, Behandlung von Ausreißern, Auffüllen fehlender Werte etc.
-
Feature Engineering (Daten werden „breiter“) wie etwa Aggregationsfunktionen, Labelkodierung, Skalierung etc.
-
Bei der Aufteilung von Datensätzen (Daten werden partitioniert) werden Ihre Daten normalerweise in Trainings-, Validierungs- und Testdaten unterteilt.
-
Datensatzaktualisierung (Daten werden „länger“), wenn neue Datenpunkte verfügbar sind.
Modellversionskontrolle
Ähnlich wie die Datenversionierung die Versionskontrolle für Daten in ML angibt, gibt die Modellversionskontrolle oder Modellversionierung speziell die Versionskontrolle von ML-Modellen an. Es beschreibt die Praxis des Speicherns, Verfolgens und Verwaltens der Änderungen in einem ML-Modell.
Für die Modellversionskontrolle müssen wir zwei weitere Begriffe definieren, um sie vom Begriff „Modellversion“ abzugrenzen [2].
-
Modellversion: einzelne Schnappschüsse eines trainierten Modells (z. B. Modellgewichte nach einer Kreuzvalidierungsfalte)
-
Modellartefakt: eine Folge protokollierter Modellversionen (z. B. die Sammlung der Modellgewichte nach jeder Faltung eines Trainingslaufs)
-
Registriertes Modell: eine Auswahl verknüpfter Modellversionen (z. B. die Kandidatenmodelle für eine Aufgabe in der Produktion)
Registrierte Modelle werden in einem Modellregister gespeichert . Sie können sich ein Modellregister als Repository für Ihre registrierten Modelle vorstellen. Sie könnten zwar ein Artefakt-Repository wie Artifactory von JFrog verwenden, um Ihre ML-Modelle zu speichern, ein Modellregister ist jedoch speziell für die Speicherung und Verwaltung von ML-Modellen vorgesehen, einschließlich Versionierung, Herkunft und Lebenszyklusverwaltung.
Während die Datenversionskontrolle hauptsächlich für die Modellentwicklung relevant ist, gilt das Modellmanagement, einschließlich der Modellversionskontrolle, für den gesamten Modelllebenszyklus vom Training über die Bereitstellung bis zur Produktion.
-
Modellentwicklung: Während der Modellentwicklung möchten Sie möglicherweise verschiedene Versionen Ihrer Modelle verfolgen, angefangen von der Modellauswahl bis hin zum Modelltraining mit verschiedenen Hyperparametern.
-
Modellbereitstellung: Während des Staging-Prozesses möchten Sie möglicherweise die Leistung verschiedener Modellversionen bewerten und mitteilen, welche Modelle für die Bereitstellung verwendet werden sollen. Neben der Protokollierung verschiedener Versionen möchten Sie möglicherweise bestimmte Versionen mit Aliasnamen (z. B. „ best“ oder „release “) kennzeichnen.
-
Modellüberwachung: Wenn Ihr Modell in Produktion ist, möchten Sie möglicherweise seine Leistung überwachen.
Wenn Sie an der Implementierung einer Daten- und Modellversionskontrolle für Ihre ML-Modelle interessiert sind, gibt es verschiedene MLOps-Plattformen und -Tools, die Daten- und Modellversionierung integrieren, wie z. B. DVC, Neptune oder Weights & Biases.
Eine praktische Anleitung zur Verwendung von W&B Artifacts zur Daten- und Modellversionierung in Python finden Sie im folgenden Video mit dem zugehörigen interaktiven Colab-Notizbuch: