
Fundamentals of Version Control
ML에서 데이터 및 모델 버전 관리를 살펴보기 전에 버전 제어의 일반적인 핵심 개념을 살펴보겠습니다. 버전 제어의 정의, 몇 가지 핵심 용어, 버전 제어가 유용한 이유, 세 가지 유형의 버전 제어에 대해 다루겠습니다.
버전 제어란 무엇인가요?
버전 제어는 시간 경과에 따라 파일이나 프로젝트 폴더에 적용된 변경 사항을 추적하고 관리하는 것을 설명합니다.
버전 제어의 핵심 개념은 다음과 같습니다.
-
버전 : 특정 시간의 파일이나 프로젝트의 스냅샷입니다.
-
저장소 : 파일이나 프로젝트의 모든 버전이 저장되는 위치입니다.
-
커밋 : 파일이나 프로젝트의 새 버전을 저장소에 저장하는 프로세스입니다.
-
기록 : 파일이나 프로젝트에 가해진 변경 사항의 기록으로, 누가 언제 무엇을 변경했는지에 대한 정보(선택적으로 왜 변경했는지, 그리고 그 영향이 무엇이었는지)가 포함됩니다.
버전 제어가 필요한 이유는 무엇인가요?
버전 제어의 사용은 파일이나 프로젝트의 여러 버전을 저장하는 것 이상입니다. 주요 장점은 추적성, 재현성, 롤백, 디버깅 및 협업입니다.
-
추적성 : 기록 로그를 통해 누가 언제 무엇을 변경했는지 빠르게 개요를 파악하고 이상적으로는 변경의 영향을 확인할 수 있습니다.
-
재현성 : 특정 시점에 어떤 버전의 파일이나 프로젝트가 사용되었는지 아는 것은 과거 결과를 재현하는 데 도움이 될 수 있습니다.
-
롤백 : 여러 버전 간에 빠르게 전환할 수 있습니다. 문제가 발생하면 이전의 안정적인 버전으로 되돌릴 수 있기 때문에 롤백에 유용합니다.
-
비교 및 디버깅 : 여러 버전을 비교하고 두 버전(예: 두 릴리스) 간에 무엇이 변경되었는지 확인할 수 있습니다. 이는 디버깅에 유용합니다.
-
협업 : 버전 제어의 유형에 따라( 버전 제어의 유형 참조 ) 팀에서 협업을 가능하게 할 수 있습니다. 기여자는 프로젝트 스냅샷의 사본을 만들고( 분기 ) 성공적인 테스트 후 전체 프로젝트와 변경 사항을 공유할 수 있습니다( 병합 ).
버전 제어의 종류
버전 제어는 장단점이 있는 다양한 형태로 제공됩니다. 파일을 수동으로 버전 관리할 수 있지만 버전 제어 시스템을 사용하는 것이 표준 관행입니다. 우리는 세 가지 유형의 버전 제어 시스템을 구분합니다. 로컬, 중앙 집중식 및 분산형입니다.
아래 그림이 익숙하게 보이시나요? 처음으로 파일의 여러 버전을 구별해야 할 때, 우리는 직관적으로 같은 파일을 다른 이름으로 저장하여 서로 다른 버전을 구별합니다.
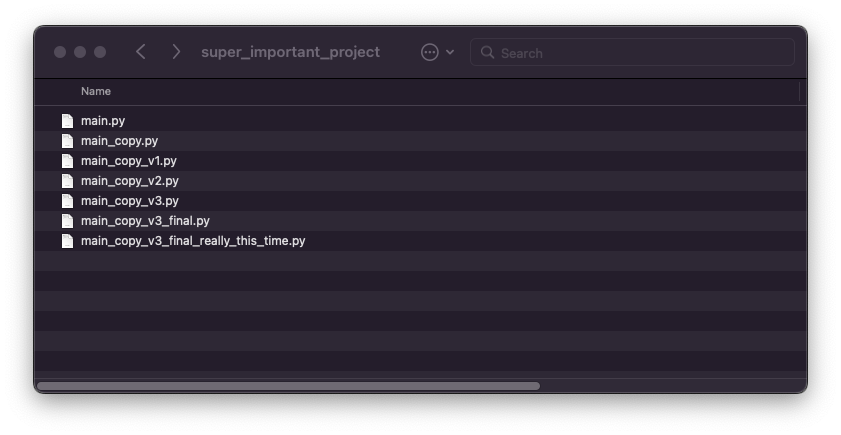
수동 버전 제어에는 단 하나의 장점(꽤나 쉽다)과 많은 단점(아주 많다)이 있습니다. 이 유형의 버전 제어는 설정 노력이 필요 없지만 변경 내역을 이해하기 어려워 다른 사람과 협업할 가능성이 거의 없습니다. 디스크가 손상되면 모든 변경 사항이 손실됩니다.
그래서 수동으로 파일과 프로젝트의 버전을 관리하는 대신, 버전 제어 시스템을 사용하는 것이 표준 관행입니다 .
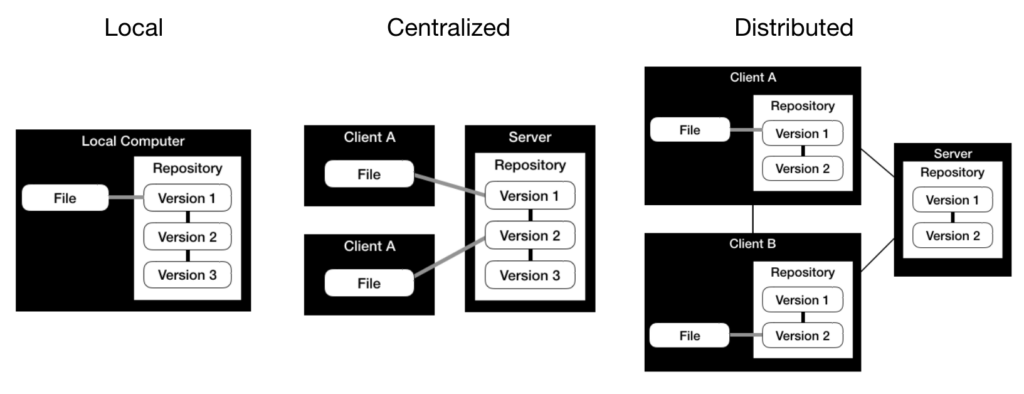
버전 제어 시스템은 3가지 유형으로 구분되며, 아래에 시각화되어 있습니다.
-
로컬 버전 제어 시스템: 로컬 컴퓨터 하나에 하나의 저장소가 있습니다. 장점은 네트워크 연결이 필요 없이 간단하게 설정하고 사용할 수 있다는 것입니다. 하지만 중앙 저장소가 없어서 협업이 불가능하고 백업 기능이 제한적입니다(단일 장애 지점).
-
중앙 집중형 버전 제어 시스템: 중앙 서버에 하나의 저장소가 있습니다. 버전은 이 중앙 저장소에 직접 저장됩니다. 중앙 저장소는 협업을 가능하게 합니다. 하지만 중앙 저장소에 대한 네트워크 연결이 필요하며, 이는 백업 기능과 관련하여 단일 지점 실패이기도 합니다. 중앙 집중형 버전 제어 시스템의 예로는 Subversion이 있습니다.
-
분산 버전 제어 시스템: 중앙 서버에 하나의 저장소가 있습니다. 클라이언트는 중앙 저장소의 로컬 사본을 만듭니다. 버전은 먼저 로컬 저장소에 저장되고 나중에 중앙 저장소와 동기화됩니다. 중앙 저장소는 협업을 가능하게 하고 로컬 사본은 오프라인 작업을 가능하게 하며 향상된 백업 기능을 제공합니다. 그러나 전체 저장소의 로컬 사본에는 더 많은 디스크 공간도 필요합니다. 분산 버전 제어 시스템의 예로는 Git 또는 Mercurial이 있습니다.
머신 러닝의 버전 제어
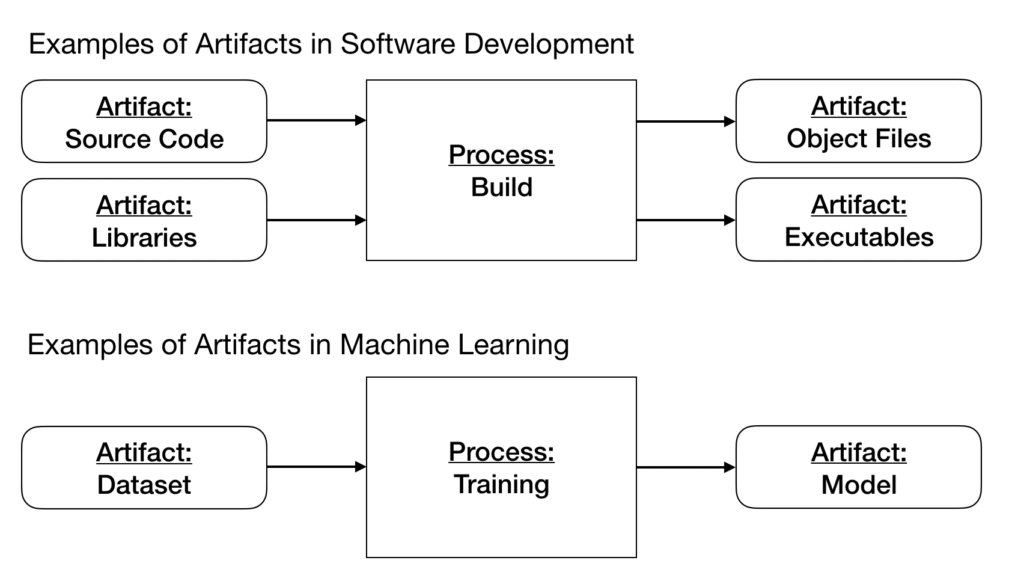
버전 제어는 소프트웨어 개발뿐만 아니라 ML 모델의 개발 프로세스에서도 유용합니다. ML에서 소스 코드 버전 관리가 데이터 세트 및 모델과 같은 아티팩트 버전 관리만큼 중요합니다.
ML 모델의 개발 과정에서 소스 코드 이외의 아티팩트를 만듭니다. 아티팩트는 프로세스의 입력 또는 출력인 모든 파일입니다. 소프트웨어 개발에서 입력인 아티팩트의 예로는 프로세스의 입력인 소스 코드와 라이브러리가 있습니다. 반면, 개체 파일과 실행 파일은 프로세스의 출력인 예시 아티팩트입니다. 이 예에서 프로세스는 빌드 프로세스입니다.
ML에서 가장 중요한 아티팩트는 데이터세트와 모델입니다. 예를 들어, 데이터세트는 학습 프로세스의 입력인 아티팩트이고, 모델은 그 출력인 아티팩트입니다.
다음 섹션에서는 데이터 세트 및 ML 모델에 대한 버전 제어를 다룹니다. 여기서 핵심 개념은 공통 버전 제어와 데이터 및 모델 버전 제어에서 유사합니다. 소스 코드 대신 데이터 및 모델에 대한 추적 가능성, 재현성, 롤백, 디버깅 및 협업 개념을 반복하는 대신, 데이터 및 모델이 변경되어 버전 관리가 필요한 시기에 초점을 맞출 것입니다.
데이터 버전 제어
버전 제어는 일반적으로 소스 코드와 연관되지만, 모델 버전 제어 또는 모델 버전 관리는 특히 ML에서 데이터의 버전 제어를 나타냅니다. 데이터 세트의 변경 사항을 저장, 추적 및 관리하는 관행을 설명합니다.
모델 개발 프로세스 중에 다음 이벤트에 대해 데이터 세트의 새 버전을 저장할 수 있습니다.
-
데이터 전처리 (데이터 내용 변경)에는 데이터 정리, 이상치 처리, 누락된 값 채우기 등이 있습니다.
-
집계 기능, 레이블 인코딩, 크기 조정 등과 같은 기능 엔지니어링 (데이터가 “더 넓어짐”)
-
데이터 세트 분할 (데이터 분할)은 일반적으로 데이터를 훈련, 검증, 테스트 데이터로 나누는 것을 의미합니다.
-
새로운 데이터 포인트가 생기면 데이터 세트를 업데이트합니다 (데이터가 “더 길어집니다”).
모델 버전 제어
데이터 버전 관리가 ML에서 데이터의 버전 관리를 나타내는 방식과 유사하게, 모델 버전 관리 또는 모델 버전 관리는 구체적으로 ML 모델의 버전 관리를 나타냅니다. ML 모델에서 변경 사항을 저장, 추적 및 관리하는 관행을 설명합니다 .
모델 버전 제어를 위해서는 “모델 버전”이라는 용어와 구별하기 위해 두 가지 용어를 더 정의해야 합니다[2].
-
모델 버전: 훈련된 모델의 단일 스냅샷(예: 교차 검증 폴드 후의 모델 가중치)
-
모델 아티팩트: 기록된 모델 버전의 시퀀스(예: 교육 실행의 각 폴드 이후 모델 가중치 수집)
-
등록된 모델: 연결된 모델 버전 선택(예: 프로덕션 작업에 대한 후보 모델)
등록된 모델은 모델 레지스트리 에 저장됩니다 . 모델 레지스트리는 등록된 모델의 저장소라고 생각할 수 있습니다. JFrog의 Artifactory와 같은 아티팩트 저장소를 사용하여 ML 모델을 저장할 수 있지만, 모델 레지스트리는 버전 관리, 계보 및 수명 주기 관리를 포함하여 ML 모델을 저장하고 관리하기 위한 것입니다.
데이터 버전 제어는 주로 모델 개발과 관련이 있는 반면, 모델 버전 제어를 포함한 모델 관리란 학습부터 스테이징, 프로덕션까지 전체 모델 수명 주기에 적용됩니다.
-
모델 개발: 모델을 개발하는 동안 모델 선택부터 다양한 하이퍼파라미터를 사용한 모델 학습까지 다양한 버전의 모델을 추적하고 싶을 수 있습니다.
-
모델 배포: 스테이징 프로세스 동안 다양한 모델 버전의 성능을 평가하고 배포에 어떤 모델을 사용해야 하는지 전달하고 싶을 수 있습니다. 다양한 버전을 로깅하는 것 외에도 특정 버전에 별칭(예: best 또는 release )을 태그로 지정할 수 있습니다.
-
모델 모니터링: 모델이 프로덕션에 사용되는 경우 모델의 성능을 모니터링하고 싶을 수 있습니다.
ML 모델에 대한 데이터 및 모델 버전 제어를 구현하는 데 관심이 있다면 DVC, Neptune, Weights & Biases와 같이 데이터 및 모델 버전 관리를 통합한 다양한 MLOps 플랫폼과 도구가 있습니다.
Python에서 데이터 및 모델 버전 관리를 위해 W&B Artifacts를 사용하는 방법에 대한 실용적인 가이드를 보려면 아래 비디오 연습과 함께 제공되는 대화형 Colab 노트북을 시청할 수 있습니다.