
모델 레지스트리는 MLOps 스택의 어떤 위치에 있나요?
모델 레지스트리는 MLOps 에 들어가 프로덕션 환경에 배포하기 직전 머신 러닝 워크플로의 마지막 부분에 있다고 생각할 수 있습니다 .

모델 실험 단계 의 출력은 모델 레지스트리에 입력되고, 이는 모델을 프로덕션에 제공할 수 있습니다. 레지스트리의 모든 모델은 적절한 상태(프로덕션 또는 챌린저)로 태그가 지정되고 전체 데이터와 모델 계보가 포함됩니다.
모델 레지스트리는 또한 배포 파이프라인과 완벽하게 통합되어 개발 환경에서 프로덕션 환경으로 모델을 빠르고 정확하게 전환할 수 있습니다. 프로덕션 모델은 데이터 드리프트 및 감소를 모니터링할 수 있으며, 필요한 경우 추가 테스트 및 평가를 위해 모델 레지스트리로 롤백하거나 데이터 세트를 업데이트할 수 있습니다.
저하된 모델이 자동으로 롤백될 때 모델 레지스트리에서 변경 작업을 쉽게 수행할 수 있으므로 항상 최고 품질의 모델만 프로덕션에 사용됩니다.
가중치 및 편향 모델 레지스트리
Weights & Biases는 AI 개발 및 ML 관찰 플랫폼입니다. 최첨단 AI 및 LLM 조직의 ML 실무자, MLOps 팀 및 ML 리더는 W&B를 확정적인 기록 시스템으로 사용하여 개인 생산성을 높이고, 프로덕션 ML을 확장하고, 간소화된 CI/CD ML 워크플로를 구현합니다.
20,000개 이상의 ML 프레임워크 및 라이브러리 통합과 모든 주요 클라우드 및 인프라 공급업체와의 강력한 파트너 생태계를 제공하는 W&B 플랫폼은 모든 산업이나 사용 사례에 완벽하게 적합하며, 전체 ML 라이프사이클에 걸쳐 적용됩니다.

효과적인 모델 레지스트리는 팀의 실험 추적 시스템과 잘 통합되어야 합니다. Weights & Biases를 사용하면 동일한 플랫폼에서 두 가지를 모두 원활하게 수행할 수 있습니다! W&B는 이미 다양한 매개변수 구성으로 실험 실행을 추적하고 모델 개발을 광범위하게 지원하는 기록 시스템 역할을 합니다.
W&B 레지스트리는 성공적인 실험을 수행하고 팀이 개발한 훈련되고 프로덕션에 적합한 모델을 이 중앙 저장소에 저장하여 다음 단계로 나아가는 데 도움이 됩니다. 모든 데이터와 모델 계보, 기타 모델 활동 세부 정보가 이미 기록되어 있으므로 사용자는 언제든지 원하는 것을 정확히 찾을 수 있습니다.
W&B 모델 레지스트리를 시작하는 방법
1) 신규 등록 모델 생성
모델링 작업을 위한 모든 후보 모델을 보관하기 위해 등록된 모델을 만들어야 합니다. W&B 앱(Model Registry 탭 또는 Artifact Browser 탭 중 하나를 클릭)을 통해 대화형으로 등록된 모델을 만들거나 W&B Python SDK를 사용하여 프로그래밍 방식으로 등록된 모델을 만들 수 있습니다.

엔터티를 선택하고 세부 정보와 적절한 태그를 입력하면 첫 번째 등록 모델이 완성됩니다!
2) 모델 버전 학습 및 기록
이제 훈련 스크립트에서 모델을 기록합니다. 모델을 주기적으로 디스크에 직렬화할 수 있습니다(및/또는 모델링 라이브러리에서 제공하는 직렬화 프로세스를 사용하여 훈련이 끝날 때(예: PyTorch 또는 Keras )).
다음으로, 모델 파일을 아티팩트 유형의 모델에 추가합니다. 정리된 상태를 유지하려면 아티팩트에 연관된 실행 ID를 사용하여 이름 간격을 지정하는 것이 좋습니다. 또한 데이터 세트를 종속성으로 선언하여 재현성과 감사 가능성을 추적할 수 있습니다.

하나 이상의 모델 버전을 로깅한 후, Artifact 브라우저에서 새로운 모델 Artifact를 볼 수 있습니다. 이 예에서, 당신은 아티팩트의 로깅 버전 결과를 볼 수 있습니다.
3) 등록된 모델에 ML 모델 버전 연결
이제 방금 훈련하고 기록한 다양한 모델 버전을 처음에 만든 등록 모델에 연결합니다.
W&B 앱에서 또는 Python SDK를 통해 프로그래밍 방식으로 이 작업을 수행할 수 있습니다. 앱에서 이 작업을 수행하려면 연결하려는 모델 버전으로 이동하여 링크 아이콘을 클릭합니다. 그런 다음 이 버전을 연결하려는 대상 등록 모델을 선택할 수 있습니다.
추가 별칭을 추가하는 옵션도 있습니다.

4) 모델 버전을 사용하세요
이제 모델을 사용할 시간입니다. 아마도 모델의 성능을 평가하고, 데이터 세트에 대한 예측을 하거나, 심지어 라이브 프로덕션 컨텍스트에서 사용하고 싶을 것입니다. 다음 코드 조각을 사용하여 Python SDK로 모델을 사용하세요.
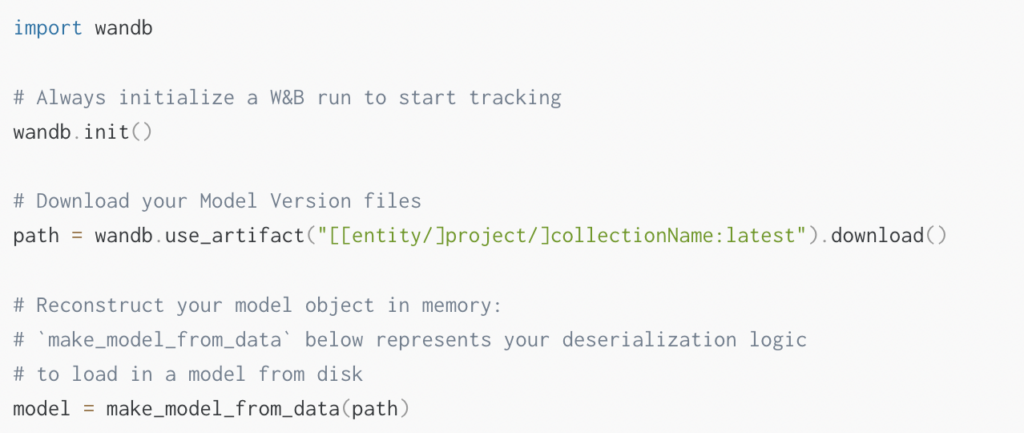
5) 모델 성능 평가
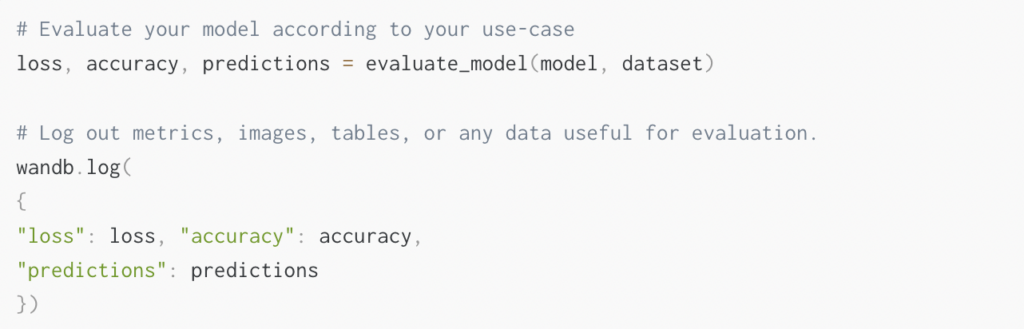
학습한 모든 모델의 성능을 평가하고 싶을 수 있는데, 학습이나 검증에 사용되지 않은 테스트 데이터 세트와 비교해서 평가하는 것이 좋습니다.
이전 단계를 완료한 후에는 평가 데이터에 대한 데이터 종속성을 선언하고 평가에 유용한 메트릭, 미디어, 테이블 및 기타 모든 항목을 기록할 수 있습니다.
6) 모델 버전을 프로덕션으로 승격
모델 평가에 만족하면 별칭을 사용하여 프로덕션에 사용할 버전을 지정하고 홍보할 수 있습니다. 등록된 각 모델은 두 개 이상의 별칭을 가질 수 있지만, 각각은 한 번에 하나의 버전에만 할당될 수 있습니다. 다시 말하지만, W&B 앱 내에서 대화형으로 별칭을 추가하거나 Python SDK를 통해 프로그래밍 방식으로 별칭을 추가할 수 있습니다.
7) 생산 모델 소비
마지막으로 추론을 위해 프로덕션 모델을 사용합니다. 라이브 프로덕션 컨텍스트에서 모델을 사용하는 방법은 위의 4단계를 참조하세요. 등록된 모델 내에서 다른 별칭 전략을 사용하여 버전을 참조할 수 있습니다. 예를 들어 “latest”, “v3” 또는 “production”을 사용합니다.
8) 보고 대시보드 구축
W&B Weave 패널을 사용하면 보고서 내에서 모델 레지스트리 또는 아티팩트 뷰를 표시할 수 있습니다 ! 메타데이터, 사용, 파일, 계보, 작업 기록 감사 또는 버전 기록 분석을 표시하는 보고서를 작성하세요. 무엇이든 파헤쳐 분석하고 싶은 대로 하세요.
모델 대시보드의 다음 예를 확인해 보세요.
