

Warum der Aufstieg von LLMOps?
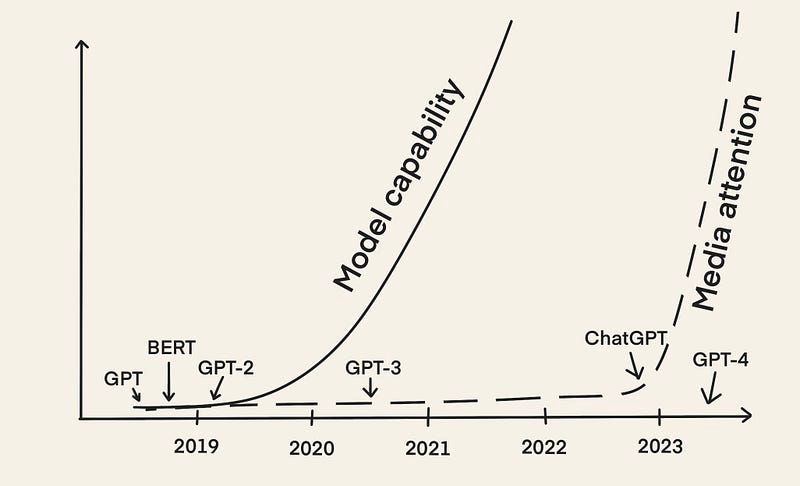
Frühe LLMs wie BERT und GPT-2 gibt es seit 2018. Doch gerade jetzt – fast fünf Jahre später – erleben wir einen kometenhaften Aufstieg der Idee von LLMOps. Der Hauptgrund dafür ist, dass LLMs mit der Veröffentlichung von ChatGPT im Dezember 2022 viel mediale Aufmerksamkeit erlangten.
Seitdem haben wir viele verschiedene Anwendungen gesehen, die die Leistungsfähigkeit von LLMs nutzen, wie zum Beispiel:
-
Chatbots vom berühmten ChatGPT bis hin zu intimeren und persönlicheren (z. B. Michelle Huang, die mit ihrem Kindheits-Ich chattet ),
-
Programmierassistenten vom Schreiben und Debuggen von Code (z. B. GitHub Copilot ) über das Testen (z. B. Codium AI ) bis hin zum Auffinden von Sicherheitsbedrohungen (z. B. Socket AI ),
Viele Menschen entwickeln und bringen LLM-basierte Anwendungen in die Produktion. Sie teilen ihre Erfahrungen:
„Es ist einfach, mit LLMs etwas Cooles zu machen, aber sehr schwer, damit etwas produktionsreifes zu machen.“ – Chip Huyen [2]
Es ist klar geworden, dass die Entwicklung produktionsreifer LLM-basierter Anwendungen ganz eigene Herausforderungen mit sich bringt, die sich von der Entwicklung von KI-Produkten mit klassischen ML-Modellen unterscheiden. Um diese Herausforderungen zu bewältigen, müssen wir neue Tools und Best Practices entwickeln, um den Lebenszyklus von LLM-Anwendungen zu verwalten. Daher sehen wir eine zunehmende Verwendung des Begriffs „LLMOps“.
Welche Schritte sind in LLMOps enthalten?
Die Schritte von LLMOps ähneln in gewisser Weise denen von MLOps. Die Schritte zum Erstellen einer LLM-basierten Anwendung unterscheiden sich jedoch aufgrund der Entstehung von Basismodellen. Anstatt LLMs von Grund auf zu trainieren, liegt der Schwerpunkt auf der Anpassung vorab trainierter LLMs an nachgelagerte Aufgaben.
Bereits vor über einem Jahr beschrieb Andrej Karpathy [3], wie sich der Prozess der Entwicklung von KI-Produkten in Zukunft verändern wird:
Aber der wichtigste Trend […] ist, dass das ganze Konzept des Trainings eines neuronalen Netzwerks von Grund auf für eine bestimmte Zielaufgabe […] aufgrund der Feinabstimmung schnell veraltet, insbesondere mit dem Aufkommen von Basismodellen wie GPT. Diese Basismodelle werden nur von wenigen Institutionen mit beträchtlichen Computerressourcen trainiert, und die meisten Anwendungen werden durch leichte Feinabstimmung eines Teils des Netzwerks, schnelles Engineering oder einen optionalen Schritt der Daten- oder Modelldestillation in kleinere, spezielle Inferenznetzwerke erreicht. […] – Andrej Karpathy [3]
Dieses Zitat kann beim ersten Lesen überwältigend wirken. Aber es fasst alles, was vor sich ging, präzise zusammen. Lassen Sie uns es in den folgenden Unterabschnitten Schritt für Schritt näher ausführen.
Schritt 1: Auswahl eines Fundamentmodells
Foundation-Modelle sind LLMs, die auf großen Datenmengen vortrainiert sind und für eine Vielzahl von nachgelagerten Aufgaben verwendet werden können. Da das Training eines Foundation-Modells von Grund auf kompliziert, zeitaufwändig und extrem teuer ist, verfügen nur wenige Institutionen über die erforderlichen Trainingsressourcen [3].
Nur um das ins rechte Licht zu rücken: Laut einer Studie von Lambda Labs aus dem Jahr 2020 würde das Training von OpenAIs GPT-3 (mit 175 Milliarden Parametern) mit einer Tesla V100-Cloud-Instanz 355 Jahre und 4,6 Millionen US-Dollar erfordern.
Die KI erlebt derzeit das, was die Community ihren „Linux-Moment“ nennt. Derzeit müssen Entwickler zwischen zwei Arten von Basismodellen wählen, die auf einem Kompromiss zwischen Leistung, Kosten, Benutzerfreundlichkeit und Flexibilität basieren: proprietäre Modelle oder Open-Source-Modelle.
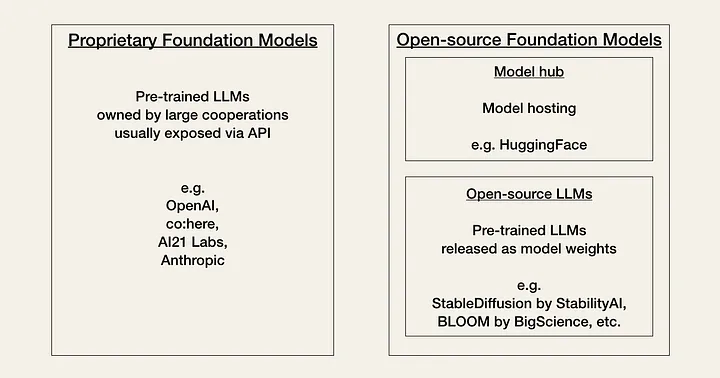
Proprietäre Modelle sind Closed-Source-Basismodelle im Besitz von Unternehmen mit großen Expertenteams und großen KI-Budgets. Sie sind in der Regel größer als Open-Source-Modelle und haben eine bessere Leistung. Sie sind außerdem handelsüblich und im Allgemeinen recht einfach zu verwenden.
Der größte Nachteil proprietärer Modelle sind ihre teuren APIs (Application Programming Interfaces). Darüber hinaus bieten Closed-Source-Modelle Entwicklern weniger oder gar keine Flexibilität bei der Anpassung.
Beispiele für proprietäre Modellanbieter sind:
-
OpenAI (GPT-3, GPT-4)
-
AI21-Labore (Jurassic-2)
-
Anthropisch (Claude)
Open-Source-Modelle werden häufig auf HuggingFace als Community-Hub organisiert und gehostet . Normalerweise sind sie kleinere Modelle mit geringeren Fähigkeiten als proprietäre Modelle. Aber auf der anderen Seite sind sie kostengünstiger als proprietäre Modelle und bieten Entwicklern mehr Flexibilität.
Beispiele für Open-Source-Modelle sind:
-
BLOOM von BigScience
Schritt 2: Anpassung an nachgelagerte Aufgaben
Sobald Sie Ihr Basismodell ausgewählt haben, können Sie über die API auf das LLM zugreifen. Wenn Sie es gewohnt sind, mit anderen APIs zu arbeiten, wird Ihnen die Arbeit mit LLM-APIs zunächst etwas seltsam vorkommen, da nicht immer im Voraus klar ist, welche Eingabe welche Ausgabe bewirkt. Bei jeder Texteingabe gibt die API eine Textvervollständigung zurück und versucht, Ihr Muster zu finden.
Hier ist ein Beispiel, wie Sie die OpenAI-API verwenden würden . Sie geben die API-Eingabe als Eingabeaufforderung ein, z. B. „ prompt = „Korrigieren Sie dies in Standardenglisch:\n\nSie ist jetzt auf den Markt gegangen.“.
 Die API gibt eine Antwort aus, die die Vervollständigungsantwort [‚choices‘][0][‚text‘] = „Sie ist nicht auf den Markt gegangen.“ enthält.
Die API gibt eine Antwort aus, die die Vervollständigungsantwort [‚choices‘][0][‚text‘] = „Sie ist nicht auf den Markt gegangen.“ enthält.
Die größte Herausforderung besteht darin, dass LLMs trotz ihrer Leistungsfähigkeit nicht allmächtig sind. Daher lautet die Schlüsselfrage: Wie bringt man einen LLM dazu, die gewünschten Ergebnisse zu erzielen?
Eine Sorge, die die Befragten in der LLM-in-Production-Umfrage [4] erwähnten, war die Modellgenauigkeit und Halluzinationen. Das bedeutet, dass es einige Iterationen dauern kann, bis die Ausgabe der LLM-API in Ihrem gewünschten Format vorliegt, und dass LLMs halluzinieren können, wenn sie nicht über das erforderliche spezifische Wissen verfügen. Um diese Bedenken auszuräumen, können Sie die Basismodelle auf folgende Weise an nachgelagerte Aufgaben anpassen:
-
Prompt Engineering [2, 3, 5] ist eine Technik, um die Eingabe so zu optimieren, dass die Ausgabe Ihren Erwartungen entspricht. Sie können verschiedene Tricks verwenden, um Ihre Eingabeaufforderung zu verbessern (siehe OpenAI Cookbook ). Eine Methode besteht darin, einige Beispiele des erwarteten Ausgabeformats bereitzustellen. Dies ähnelt einer Zero-Shot- oder Few-Shot-Learning-Einstellung [5]. Es gibt bereits Tools wie LangChain oder HoneyHive, die Ihnen bei der Verwaltung und Versionierung Ihrer Eingabeaufforderungsvorlagen helfen [1].
- Die Feinabstimmung vorab trainierter Modelle [2, 3, 5] ist eine bekannte Technik im ML. Sie kann dazu beitragen, die Leistung Ihres Modells für Ihre spezifische Aufgabe zu verbessern. Obwohl dies den Trainingsaufwand erhöht, kann es die Kosten der Inferenz senken. Die Kosten von LLM-APIs hängen von der Länge der Eingabe- und Ausgabesequenz ab. Wenn Sie also die Anzahl der Eingabetoken reduzieren, werden die API-Kosten gesenkt, da Sie in der Eingabeaufforderung keine Beispiele mehr angeben müssen [2].
-
Externe Daten: Den Basismodellen fehlen oft Kontextinformationen (z. B. Zugriff auf bestimmte Dokumente oder E-Mails) und sie können schnell veralten (z. B. wurde GPT-4 mit Daten vor September 2021 trainiert ). Da LLMs halluzinieren können, wenn sie nicht über ausreichende Informationen verfügen, müssen wir ihnen Zugriff auf relevante externe Daten geben können. Es gibt bereits Tools wie LlamaIndex (GPT Index) , LangChain oder DUST , die als zentrale Schnittstellen dienen können, um LLMs mit anderen Agenten und externen Daten zu verbinden („zu verketten“) [1].
-
Embeddings: Eine weitere Möglichkeit besteht darin, Informationen in Form von Embeddings aus LLM-APIs zu extrahieren (z. B. Filmzusammenfassungen oder Produktbeschreibungen) und darauf Anwendungen aufzubauen (z. B. Such-, Vergleichs- oder Empfehlungsfunktionen). Wenn np.array nicht ausreicht, um Ihre Embeddings für das Langzeitgedächtnis zu speichern, können Sie Vektordatenbanken wie Pinecone , Weaviate oder Milvus [1] verwenden.
-
Alternativen: Da sich dieses Feld rasch weiterentwickelt, gibt es viele weitere Möglichkeiten, LLMs in KI-Produkten einzusetzen. Einige Beispiele sind Instruction Tuning / Prompt Tuning und Model Distillation [2, 3].
Schritt 3: Auswertung
Bei klassischen MLOps werden ML-Modelle anhand eines Hold-out-Validierungssets [5] mit einer Metrik validiert, die die Leistung der Modelle angibt. Aber wie bewertet man die Leistung eines LLM? Wie entscheidet man, ob eine Antwort gut oder schlecht ist? Derzeit sieht es so aus, als würden Organisationen ihre Modelle A/B-Tests unterziehen [5].
Zur Bewertung von LLMs sind Tools wie HoneyHive oder HumanLoop entstanden.
💡
Schritt 4: Bereitstellung und Überwachung
Die Vervollständigungen von LLMs können sich zwischen den Versionen drastisch ändern [2]. So hat OpenAI beispielsweise seine Modelle aktualisiert, um die Generierung unangemessener Inhalte, wie etwa Hassreden, zu unterbinden. Als Folge davon liefert die Suche nach dem Ausdruck „as an AI language model“ auf Twitter mittlerweile unzählige Bots.
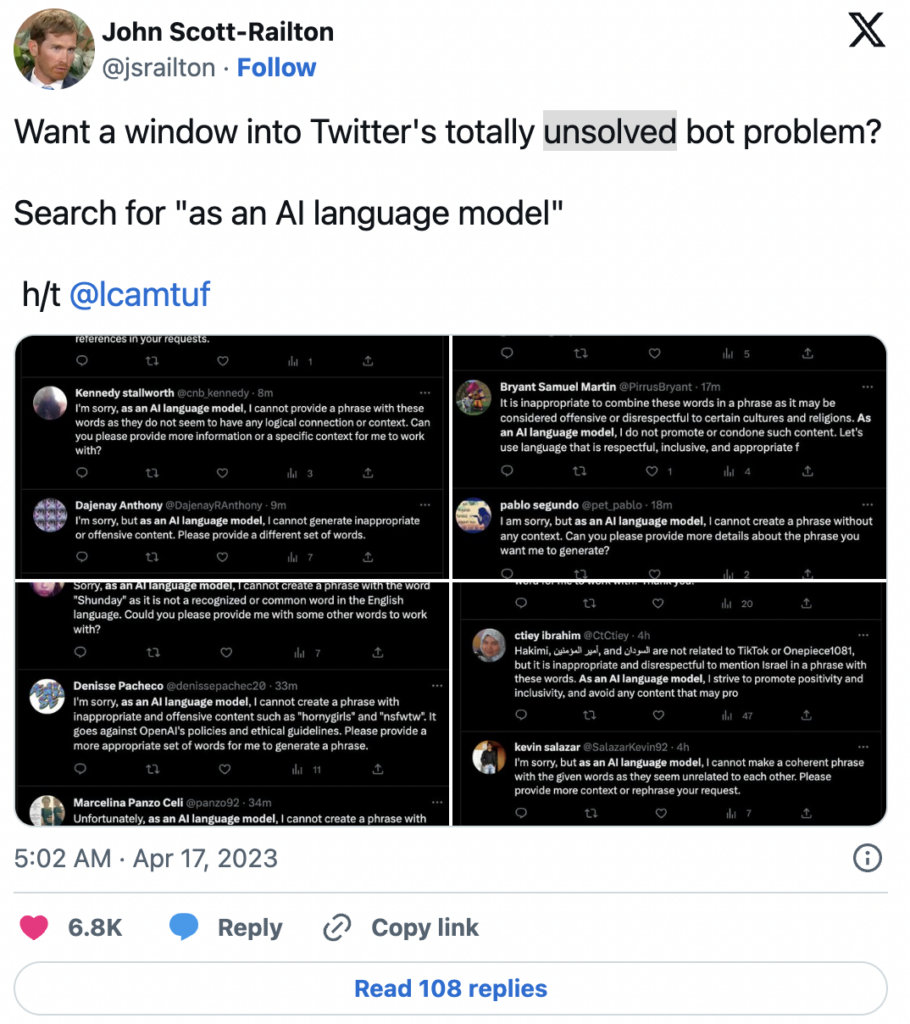 Dies zeigt, dass beim Erstellen von LLM-basierten Anwendungen die Änderungen im zugrunde liegenden API-Modell überwacht werden müssen.
Dies zeigt, dass beim Erstellen von LLM-basierten Anwendungen die Änderungen im zugrunde liegenden API-Modell überwacht werden müssen.