In diesem Artikel untersucht Alex Paino, wie das OpenAI Robotics-Team Weights & Biases Reports verwendet, um umfangreiche Machine-Learning-Projekte durchzuführen.

Alex Paino
Wie das OpenAI Robotics Team W&B-Berichte nutzt
Im Robotik-Team bei OpenAI haben wir W&B-Berichte stark in unseren Arbeitsablauf integriert und sind in den letzten etwa sechs Monaten dazu übergegangen, sie als unser primäres Mittel zum Teilen von Ergebnissen innerhalb des Teams zu verwenden.
Die Möglichkeit, echte Daten aus Experimenten mit Kontext und Kommentaren zu den Ergebnissen zu kombinieren, war für uns das wichtigste Verkaufsargument. Vor der Einführung von Berichten erstellten wir in der Regel ein Google-Dokument, um alle „Durchläufe“ einer bestimmten Experimentierreihe zu verfolgen, und mussten ziemlich viel Zeit darauf verwenden, diese Dokumente richtig mit den experimentellen Daten zu verknüpfen (entweder in Weights & Biases oder Tensorboard).
Mithilfe von Berichten müssen wir uns nicht mehr um die mühsame Buchführung kümmern, und wir können vollständige Ansichten der Daten einfacher freigeben (da der Betrachter auswählen kann, welche Läufe angezeigt werden sollen, in bestimmte Läufe einsteigen oder den Bericht sogar klonen kann, um weitere Diagramme hinzuzufügen).
Workflow mit Berichten
Wenn wir eine neue Experimentierreihe beginnen (z. B. Ablationen in Batchgröße, Architektursuche), neigen wir dazu, den folgenden Workflow mit Berichten zu verwenden:
Schritt 1 : Erstellen Sie einen neuen Bericht mit einem Text am Anfang, der den Kontext , die zu testenden Hypothesen und den Versuchsplan erläutert . Geben Sie ihn dann zur Überprüfung an das Team weiter. Auf diese Weise können Sie den Versuchsprozess strenger gestalten und Teammitgliedern dabei helfen, Probleme früher zu erkennen oder Ideen vorzuschlagen.
Schritt 2: Starten Sie ein oder mehrere Experimente zum Testen der Hypothesen.
Tipp : Protokollieren Sie den Git-SHA, der zum Starten jedes Experiments verwendet wurde, oder verwenden Sie die Codeprotokollierungsfunktion von Weights & Biases. Wir neigen dazu, das Git-SHA-Präfix in Experimentnamen aufzunehmen, um den Zugriff zu erleichtern.
Schritt 3: Sobald bestätigt ist, dass die Experimente korrekt laufen (d. h. keine sichtbaren Fehler vorliegen), fügen wir jedes als eigenes Run Set hinzu und fügen dann eine Reihe von Diagrammen für alle für uns wichtigen Metriken hinzu. Wenn Sie dies im Voraus tun, können Sie laufende Experimente leicht überwachen, insbesondere wenn viele gleichzeitig laufen.
Tipp : Geben Sie den Run Sets aussagekräftige Namen und geben Sie allen Läufen in jedem Run Set innerhalb eines bestimmten Abschnitts die gleiche Farbe.
Schritt 4: Überwachen Sie die Experimente. Wenn nach der ersten Reihe von Experimenten genügend Daten gesammelt wurden, fügen Sie oben eine Schlussfolgerung hinzu und teilen Sie diese mit dem Team. Andernfalls aktualisieren Sie die Hypothesen und den Versuchsplan und kehren zu Schritt 2 zurück.
Der Rest dieses Berichts präsentiert ein Beispiel für diesen Workflow, der auf die Forschungslinie angewendet wird, die darauf abzielt, die Blockneuorientierungsaufgabe aus unserer Learning Dexterity- Version durchgängig zu lösen (natürlich ist hier etwas mehr Kontext enthalten als in internen Berichten). Wenn Sie mit dieser Arbeit nicht vertraut sind, empfehle ich Ihnen, den unten ausgeblendeten Abschnitt „Hintergrund“ durchzulesen.
Hintergrund
In Learning Dexterity haben wir eine menschenähnliche Roboterhand darauf trainiert, physische Objekte mit beispielloser Geschicklichkeit zu manipulieren. Insbesondere war die Hand in der Lage, einen Holzblock mit hoher Erfolgsquote in die gewünschte Position und Ausrichtung zu bringen. Im vergangenen November haben wir in Solving Rubik’s Cube eine Weiterentwicklung dieses grundlegenden Ansatzes genutzt, um den Zauberwürfel mit derselben Roboterhand zu manipulieren.
Für beide Versionen haben wir das Lernproblem in zwei Teile zerlegt:
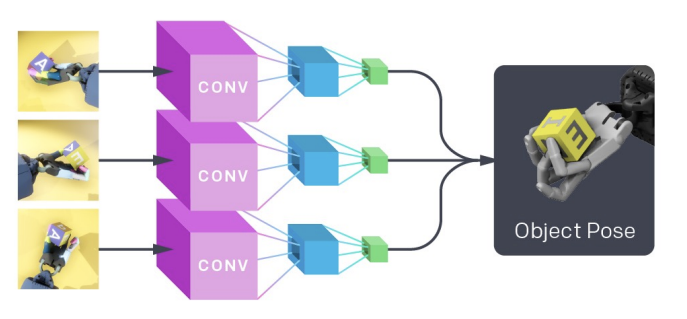
1. Erlernen eines Bildverarbeitungsmodells mittels überwachtem Lernen, das Bildbeobachtungen von rund um den Roboter angebrachten Kameras abbildet, um Schätzungen zur Position des Blocks zu liefern:
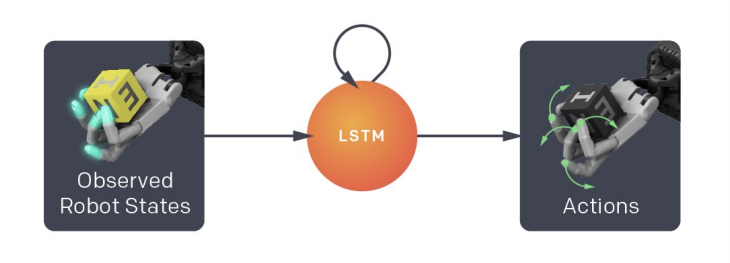
 2. Erlernen einer zielbedingten Strategie mittels bestärkendem Lernen, das die Schätzungen des Bildverarbeitungsmodells (sowie einen gewünschten Zielzustand) nutzt, um Befehle zur Steuerung der Roboterhand zu erzeugen:
2. Erlernen einer zielbedingten Strategie mittels bestärkendem Lernen, das die Schätzungen des Bildverarbeitungsmodells (sowie einen gewünschten Zielzustand) nutzt, um Befehle zur Steuerung der Roboterhand zu erzeugen:
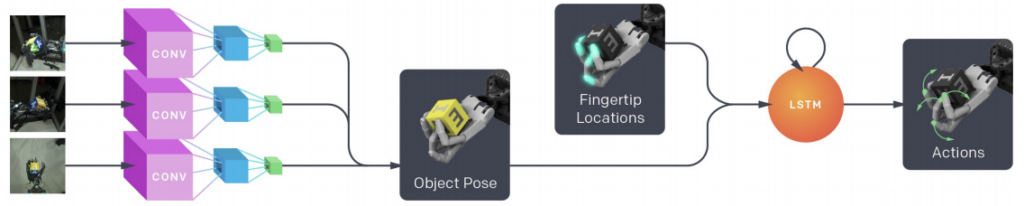
 Wenn es an der Zeit ist, in der realen Welt mit dem Roboter zu experimentieren, kombinieren wir das Sichtmodell und die Richtlinie:
Wenn es an der Zeit ist, in der realen Welt mit dem Roboter zu experimentieren, kombinieren wir das Sichtmodell und die Richtlinie:
Bestärkendes Lernen vs. Verhaltensklonen
Kontext
Nachdem wir die Ergebnisse des Zauberwürfels ausgeliefert hatten, wollten wir untersuchen, ob wir das Lernproblem auf einen einzigen Schritt reduzieren könnten, indem wir eine Strategie direkt aus Bildern lernen (auch als „ End-to-End “ bezeichnet), was zu einer Strategie führen würde, die folgendermaßen aussieht:
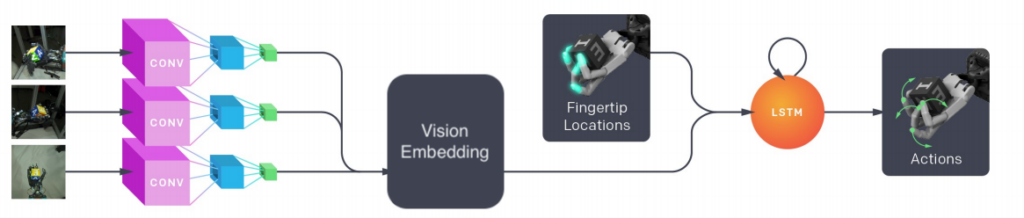
Das Lernen von Ende zu Ende hat Vorteile (z. B. keine Notwendigkeit, explizite Zustandsdarstellungen zu entwerfen, konzeptionelle Einfachheit), und zu wissen, wie gut es bei unseren jüngsten Versionen funktioniert hätte, könnte bei der Festlegung künftiger Forschungsrichtungen hilfreich sein. Wir haben uns der Einfachheit halber entschieden, diese Untersuchung auf das Setup von Learning Dexterity, d. h. Blockneuausrichtung, zu beschränken.
Hypothesen/Forschungsfragen
-
Können wir eine End-to-End-Richtlinie trainieren, um die Aufgabe der Blockneuausrichtung zu lösen?
-
Können wir Behavioral Cloning (BC) mit einer zuvor trainierten zustandsbasierten Richtlinie verwenden, um dies effizienter zu tun?
-
Ist es möglich, mithilfe von Reinforcement Learning (RL) eine solche Richtlinie „von Grund auf“ zu trainieren?
-
Wenn 2 und 3 mit Ja beantwortet wurden, wie viel „teurer“ ist RL im Vergleich zu BC?
-
Welche Änderungen (z. B. die Verwendung eines vortrainierten Bildverarbeitungsmodells) sind für das erfolgreiche Trainieren dieser Richtlinien von entscheidender Bedeutung?
Planen
-
Versuchen Sie, Verhaltensklonen zu verwenden, um eine End-to-End-Richtlinie zu trainieren. Iterieren Sie verschiedene Aspekte, z. B. die Verwendung eines vorab trainierten Vision-Modells, die Batch-Größe, die Vision-Modell-Architektur usw.
-
Wenn das Verhaltensklonen erfolgreich ist, trainieren Sie eine Richtlinie über RL mit den besten Einstellungen aus (1).
Schlussfolgerungen
-
Wir haben festgestellt, dass wir Verhaltensklonen verwenden können, um eine End-to-End-Richtlinie (relativ) effizient zu trainieren, indem wir eine vorab trainierte zustandsbasierte Richtlinie als „Lehrer“ verwenden. Teil 1 unten beschreibt unsere Erkenntnisse hier im Detail, einschließlich Abzügen bei Modellgröße, Batchgröße und der Verwendung eines vorab trainierten „Untermodells“ für die visuelle Darstellung. Die bemerkenswerteste Erkenntnis hier ist, dass die Verwendung eines vorab trainierten Untermodells für die visuelle Darstellung das Training um das Vierfache beschleunigt.
-
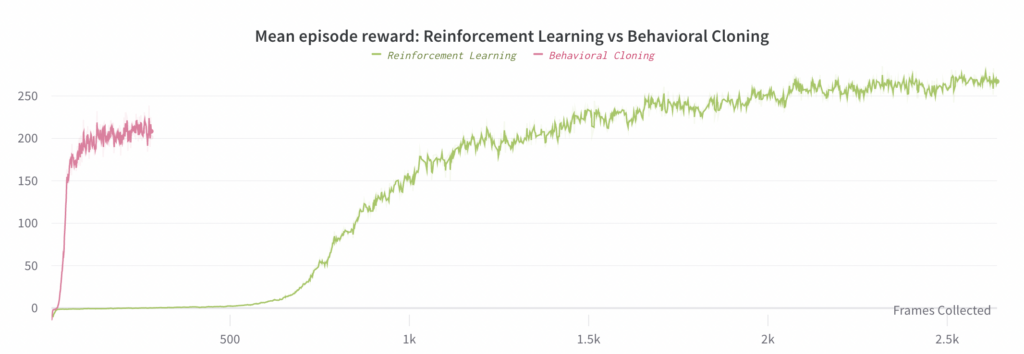
Wir können auch Reinforcement Learning verwenden, um eine End-to-End-Richtlinie zu erlernen, aber dies erfordert etwa 30-mal mehr Rechenleistung als Behavioral Cloning (wenn beide ein vorab trainiertes Vision-Submodell verwenden). Teil 2 beschreibt dieses Experiment im Detail und vergleicht es mit dem besten Behavioral Cloning-Experiment (das Hauptergebnis ist in der folgenden Grafik dargestellt).
Teil 1: Verhaltensklonen
Im Robotik-Team von OpenAI verwenden wir häufig Verhaltensklonen , um Richtlinien mithilfe einer bereits trainierten Richtlinie schnell zu trainieren. Wir fanden dies in einigen Szenarien nützlich, beispielsweise beim schnellen Starten des Trainings einer Richtlinie mit einer anderen Modellarchitektur oder einem anderen Beobachtungsraum; Einzelheiten finden Sie in Abschnitt 6.4 des Rubik’s Cube-Dokuments . Daher war es für uns naheliegend, diese Untersuchung damit zu beginnen, zu prüfen, ob wir eine zustandsbasierte Richtlinie in eine End-to-End-Richtlinie klonen könnten.
Glücklicherweise haben wir festgestellt, dass Verhaltensklonen sehr gut zum Trainieren von End-to-End-Richtlinien geeignet ist. Da Verhaltensklonen tatsächlich eine Form von überwachtem Lernen ist, können wir im Vergleich zum bestärkenden Lernen viel kleinere Batchgrößen verwenden und benötigen weitaus weniger Optimierungsschritte, um die End-to-End-Richtlinien bis zur Konvergenz zu trainieren. Dies ist insbesondere beim Trainieren von End-to-End-Richtlinien von Vorteil, da die maximale Batchgröße pro GPU viel kleiner ist als bei zustandsbasierten Richtlinien (aufgrund der viel größeren Beobachtungen und der großen Größe der Aktivierungen des Vision-Modells).
Für diese Experimente nutzten wir zusätzlich die ursprüngliche Lernaufgabe der überwachten Zustandsvorhersage, um das Vision-Untermodell vorzutrainieren (d. h. wir trainierten das Vision-Modell bis zur Konvergenz bei dieser Aufgabe und verwendeten dann die resultierenden Parameter bis zur vorletzten Schicht, um das Vision-Untermodell in den End-to-End-Richtlinien zu initialisieren).
In den folgenden Unterabschnitten präsentieren wir die Ergebnisse einiger interessanter Ablationsexperimente, die wir mit Behavioral Cloning durchgeführt haben. Hier sind die Schlussfolgerungen:
-
Lernen separater Einbettungszuordnungen: Wir haben festgestellt, dass das Lernen separater Einbettungszuordnungen (d. h. vollständig verbundene Schichten, die Eingaben in einen Einbettungsraum abbilden, der wiederum die Eingabe für das Policy-LSTM ist) für die Policy- und Wertfunktionsnetzwerke das Training erheblich beschleunigte.
-
Modellarchitektur: Wir haben zwei verschiedene Architekturen für das Vision-Untermodell ausprobiert, ResNet50 und den größeren Vision-Encoder von IMPALA , und fanden, dass ResNet50 sowohl hinsichtlich der für die Konvergenz erforderlichen Rechenleistung als auch hinsichtlich der endgültigen Leistung die bessere Leistung bietet.
-
Batch-Größe: Wir haben effektive Batch-Größen von 512, 1024 und 2048 ausprobiert (erreicht durch Skalierung der Anzahl der GPU-Optimierer) und festgestellt, dass 1024 die beste Rechenleistung liefert und gleichzeitig die maximale Endleistung erreicht.
-
Vorabtraining des Bildverarbeitungsmodells: Wir haben festgestellt, dass die Verwendung eines vorab trainierten Modells das Training im Vergleich zur Verwendung eines zufällig initialisierten Bildverarbeitungsuntermodells um etwa das Vierfache beschleunigt.
Ablation des Verhaltensklonens 1: Erlernen separater Einbettungszuordnungen
Wie in Abschnitt 6.2 des Rubik’s Cube-Artikels beschrieben , betten wir alle Eingaben in die Richtlinien- und Wertfunktionsnetzwerke in einen 512-d-Raum ein, summieren sie und wenden eine Nichtlinearität an, bevor wir sie an die Richtlinien- und Wertfunktionsnetzwerke weitergeben:
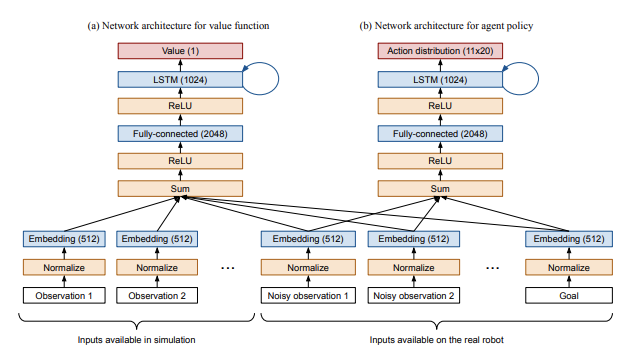
Bei unserer End-to-End-Richtlinie haben wir mit demselben Setup begonnen, nur mit anderen Beobachtungen, die dem Richtliniennetzwerk zur Verfügung stehen. Konkret haben wir Zustandsbeobachtungen entfernt und eine Beobachtung aus der Ausgabe des Vision-Submodells hinzugefügt. Beachten Sie, dass die Ausgabe des Vision-Submodells auf dieselbe Weise behandelt wird wie jede andere Eingabe, d. h. wir wenden eine vollständig verbundene Schicht darauf an, um sie in denselben 512-d-Raum einzubetten wie alle anderen Eingaben. Wir nennen diese vollständig verbundenen Schichten „Einbettungsmappings“.
In der Rubik’s Cube-Version haben wir diese Einbettungszuordnungen zwischen den Richtlinien- und Wertfunktionsnetzwerken geteilt. Wir haben jedoch festgestellt, dass beim Training von End-to-End-Richtlinien das Erlernen separater Einbettungszuordnungen etwa zwei- bis dreimal schneller ist . Wir glauben, dass dies auf eine Interferenz zwischen der Optimierung der Wertfunktion und der Richtliniennetzwerke zurückzuführen ist: Da die Wertfunktion immer noch Zugriff auf vollständige Statusinformationen hat, benötigt sie die (relativ verrauschte) Ausgabe des Vision-Submodells nicht und drückt daher die Vision-Einbettung gegen Null. Das Richtliniennetzwerk benötigt diese Vision-Einbettung natürlich, um den Zustand der Umgebung zu verstehen; daher der Konflikt.
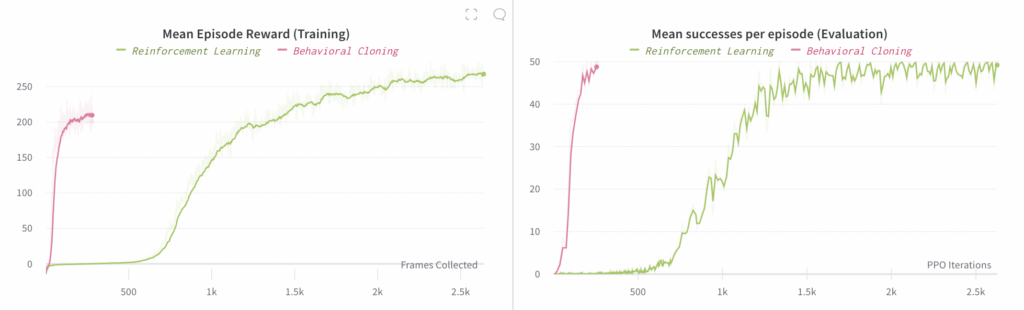
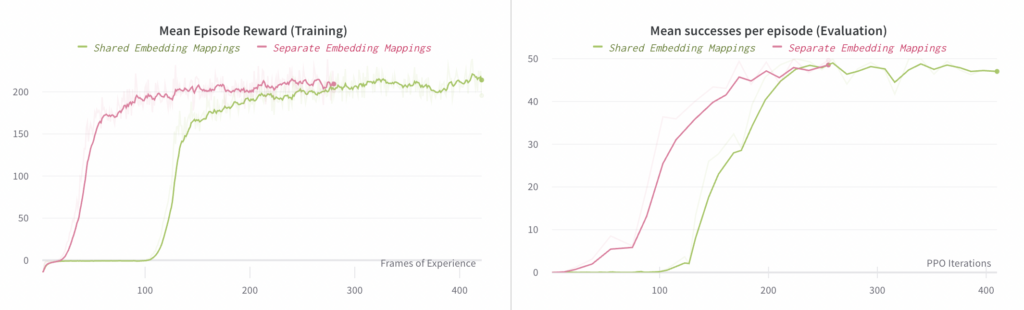
Im Folgenden vergleichen wir den Fortschritt von Experimenten mit separaten und gemeinsamen Einbettungszuordnungen. Das Diagramm auf der linken Seite vergleicht die mittlere Belohnung, die bei Rollouts der End-to-End-Richtlinie beobachtet wurde (wobei diese Rollouts zum Training verwendet werden). Das Diagramm auf der rechten Seite vergleicht die mittlere Anzahl von Erfolgen pro Episode, wobei ein „Erfolg“ die Neuausrichtung des Blocks auf ein gewünschtes Ziel beinhaltet; jede Episode ist auf maximal 50 Erfolge begrenzt.
Beachten Sie, dass die X-Achse des linken Diagramms die Anzahl der gesammelten Frames (also die Menge der verbrauchten Daten) darstellt, während die X-Achse des rechten Diagramms die Anzahl der PPO- Iterationen (also die Anzahl der Optimierungsschritte) darstellt.
Tipp: Wenn Sie im Vorfeld etwas Zeit in das Verfassen guter Titel, das Hinzufügen geeigneter Glättungen und die Verwendung einheitlicher Farbgebung investieren, können Sie Ihren Teamkollegen beim Lesen des Berichts viel Zeit sparen.
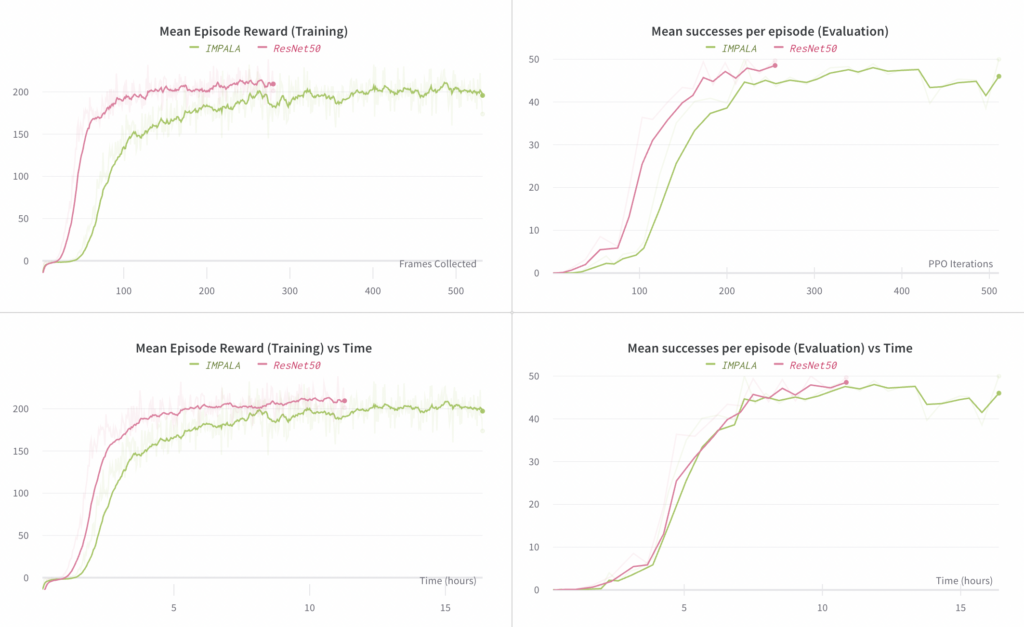
Verhaltensklonen-Ablation 2: Modellarchitektur
Hier heben wir die Wahl der Architektur des Vision-Submodells auf. Wir vergleichen ResNet50 (wie es in der Rubik’s Cube-Version verwendet wird) mit dem viel kleineren IMAPALA-Vision-Encoder (das rechte Bild in Abbildung 3 aus dem IMPALA-Papier ). Wir haben festgestellt, dass das ResNet50-Modell im Vergleich zum IMPALA-Encoder eine etwas höhere Endleistung (in Bezug auf die durchschnittliche Anzahl von Erfolgen) erzielt und gleichzeitig weniger Schritte zum Konvergieren benötigt. Die Zeit pro Schritt ist beim ResNet50-Experiment etwas höher, aber es konvergiert im Vergleich zum IMPALA-Experiment immer noch schneller in Bezug auf die verstrichene Zeit.
Die Diagramme auf der linken Seite vergleichen die durchschnittliche Belohnung, die bei Rollouts der End-to-End-Richtlinie beobachtet wurde (wobei diese Rollouts zum Training verwendet werden). Die Diagramme auf der rechten Seite vergleichen die durchschnittliche Anzahl von Erfolgen pro Episode, wobei ein „Erfolg“ die Neuausrichtung des Blocks auf ein gewünschtes Ziel beinhaltet; jede Episode ist auf maximal 50 Erfolge begrenzt.
Tipp: Durch das Duplizieren von Abschnitten wird ein Teil der mühsamen Arbeit beim Einrichten von Diagrammen eingespart.
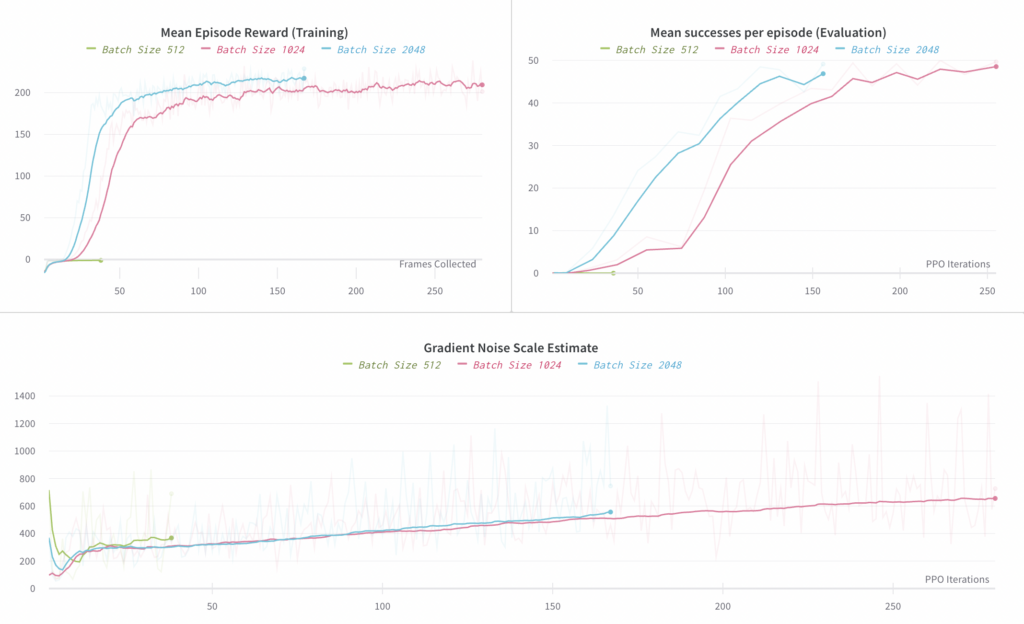
Verhaltensklonen-Ablation 3: Batch-Größe
Hier reduzieren wir die gesamte verwendete Batchgröße und vergleichen 512, 1024 und 2048. Eine Batchgröße von 512 schien nicht zu funktionieren (wir sahen nach 38 Schritten immer noch eine negative mittlere Belohnung, während wir nach der Verarbeitung einer gleichen Anzahl von Proben eine positive mittlere Belohnung aus dem 1024-Experiment sahen). Batchgrößen von 1024 und 2048 funktionierten beide, aber die Batchgröße von 2048 beschleunigt das Training nur um ~30 %, daher halten wir 1024 in Bezug auf die Proben- und Rechenleistung für optimal. Dies lässt sich am einfachsten im ersten Diagramm unten mit mittlerer Belohnung vs. gesammelter Frames beobachten.
Das Diagramm auf der linken Seite vergleicht die durchschnittliche Belohnung, die bei Rollouts der End-to-End-Richtlinie beobachtet wurde (wobei diese Rollouts zum Training verwendet werden). Das Diagramm auf der rechten Seite vergleicht die durchschnittliche Anzahl von Erfolgen pro Episode, wobei ein „Erfolg“ die Neuausrichtung des Blocks auf ein gewünschtes Ziel beinhaltet; jede Episode ist auf maximal 50 Erfolge begrenzt.
Unten stellen wir eine Schätzung der Gradient Noise Scale dar, wie in „Ein empirisches Modell für das Training großer Batches“ beschrieben . Wir sehen, dass sie bei Konvergenz ungefähr 700 beträgt, was eine kritische Batchgröße in diesem Bereich bedeutet. Beachten Sie jedoch, dass das Verhalten der Gradient Noise Scale für Behavioral Cloning nicht so gut untersucht wurde. Daher haben wir sie hier hauptsächlich verwendet, um ein grobes Verständnis dafür zu bekommen, welche Batchgröße wir anstreben sollten. Dafür war sie nützlich, da sie die optimale Größenordnung für die Batchgröße korrekt vorhersagt.
Tipp: Einige Messwerte, wie beispielsweise dieser, weisen mehr Rauschen auf als andere. Daher empfiehlt es sich, eine diagrammspezifische Glättung anzuwenden.
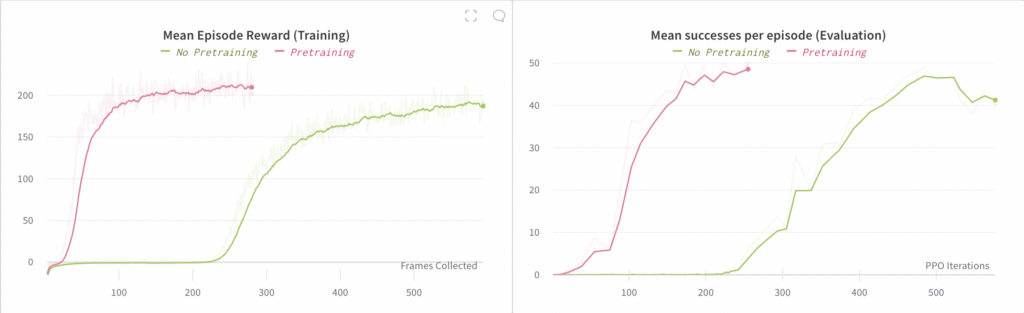
Verhaltensklonen-Ablation 4: Vortraining
Hier verzichten wir auf die Verwendung eines vorab trainierten Vision-Submodells. Wir haben festgestellt, dass wir auch ohne Vorabtraining eine End-to-End-Richtlinie trainieren können, die Konvergenz jedoch viermal langsamer ist.
Das Diagramm auf der linken Seite vergleicht die durchschnittliche Belohnung, die bei Rollouts der End-to-End-Richtlinie beobachtet wurde (wobei diese Rollouts zum Training verwendet werden). Das Diagramm auf der rechten Seite vergleicht die durchschnittliche Anzahl von Erfolgen pro Episode, wobei ein „Erfolg“ die Neuausrichtung des Blocks auf ein gewünschtes Ziel beinhaltet; jede Episode ist auf maximal 50 Erfolge begrenzt.
Teil 2: Bestärkendes Lernen vs. Verhaltensklonen
Nachdem wir die oben genannten Ablationen abgeschlossen hatten, nahmen wir das beste Gesamt-Setup pro Ablation und trainierten damit eine End-to-End-Richtlinie über Reinforcement Learning. Beachten Sie, dass auch hier ein vorab trainiertes Modell verwendet wurde, wie in den Experimenten zum Verhaltensklonen.
Wir haben festgestellt, dass das Trainieren einer End-to-End-Richtlinie über RL funktioniert. Es ist nur sehr viel langsamer als Behavioral Cloning, was zu erwarten war. Aufgrund des viel höheren Rechenleistungsbedarfs haben wir hier nur ein einziges Experiment durchgeführt: Das RL-Experiment erforderte 4 Tage lang 128 V100-GPUs im Vergleich zu 8 Stunden lang 48 V100-GPUs, die Behavioral Cloning benötigt. Insgesamt ergibt dies etwa 30-mal mehr Rechenleistung für RL im Vergleich zu Behavioral Cloning und etwa 2,67-mal so viel Rechenleistung pro Schritt. Der Hauptwert dieser Schlussfolgerung besteht darin, dass sie uns sagt, dass es immer noch möglich ist, RL zum Erlernen von End-to-End-Richtlinien zu verwenden, dass es aber im Allgemeinen sehr rechenintensiv sein wird, wenn wir nicht in der Lage sind, weitere Optimierungen zu finden.
Beachten Sie, dass die Formen der beiden folgenden Diagramme unterschiedlich sind, da die vom RL-Experiment verwendete Batchgröße viel größer ist (da das linke Diagramm eine X-Achse der gesammelten Frames verwendet).