この記事では、Alex Paino が、OpenAI Robotics チームが重みとバイアス レポートを使用して大規模な機械学習プロジェクトを実行する方法について説明します。

アレックスの体重
OpenAI ロボティクス チームが W&B レポートをどのように活用しているか
OpenAI のロボティクス チームでは、W&B レポートをワークフローに積極的に取り入れており、過去 6 か月ほどで、チーム内で結果を共有する主な手段として W&B レポートを使用するようになりました。
実験からの実際のデータと結果のコンテキストやコメントを組み合わせる機能は、私たちにとって主なセールス ポイントでした。Reports が登場する前は、通常、特定の実験ラインのすべての「実行」を追跡するために Google ドキュメントを作成し、これらのドキュメントを実験データ (W&B または Tensorboard のいずれか) に適切にリンクするのにかなりの時間を費やす必要がありました。
レポートを使用すると、面倒な簿記作業から解放されるだけでなく、データの完全なビューをより簡単に共有できるようになります (閲覧者は表示する実行を選択したり、特定の実行にドリルダウンしたり、レポートを複製してさらにプロットを追加したりできるため)。
レポートを使用したワークフロー
新しい実験ライン(バッチ サイズのアブレーション、アーキテクチャの検索など)を開始するときは常に、レポートを使用して次のワークフローを使用する傾向があります。
ステップ 1 :コンテキスト、テスト中の仮説、実験計画を説明するテキストを上部に含む新しいレポートを作成し、それをチームと共有してレビューしてもらいます。これを行うと、実験プロセスがより厳格になり、チームメイトが早い段階で問題を見つけたりアイデアを提案したりしやすくなります。
ステップ 2:仮説をテストすることを目的とした 1 つ以上の実験を開始します。
ヒント:各実験を開始するために使用した Git SHA を記録するか、W&B のコードログ機能を使用してください。簡単にアクセスできるように、実験名に Git SHA プレフィックスを含める傾向があります。
ステップ 3:実験が正しく実行されていることが確認されたら (つまり、目に見えるバグがない)、各実験を独自の実行セットとして追加し、関心のあるすべてのメトリックのプロットをいくつか追加します。これを事前に実行しておくと、特に多数の実験を同時に実行している場合に、実行中の実験を簡単に監視できます。
ヒント:実行セットにわかりやすい名前を付け、特定のセクション内の各実行セットのすべての実行を同じ色にします。
ステップ 4:実験を監視します。最初の一連の実験の後に十分なデータが収集された場合は、結論を先頭に追加してチームと共有します。そうでない場合は、仮説と実験計画を更新して、ステップ 2 に戻ります。
このレポートの残りの部分では、Learning Dexterityリリースのブロック再配向タスクをエンドツーエンドで解決することを目的とした研究ラインに適用されたこのワークフローの 1 つの例を示します (もちろん、内部レポートと比較して、ここにはもう少し多くのコンテキストが含まれています)。この作業に馴染みがない場合は、以下の折りたたまれた「背景」セクションを読むことをお勧めします。
背景
「器用さの学習」では、人間のようなロボットハンドを訓練し、これまでにない器用さで物理的な物体を操作できるようにしました。具体的には、ロボットハンドは木製のブロックを希望の位置と方向に高い成功率で再配置することができました。昨年 11 月の「ルービック キューブを解く」では、この基本的なアプローチの進化形を利用して、同じロボットハンドでルービック キューブを操作しました。
これら両方のリリースでは、学習の問題を 2 つの部分に分解しました。
1.ロボットの周囲に取り付けられたカメラからの画像観測をマッピングしてブロックの姿勢を推定する、教師あり学習による視覚モデルの学習。
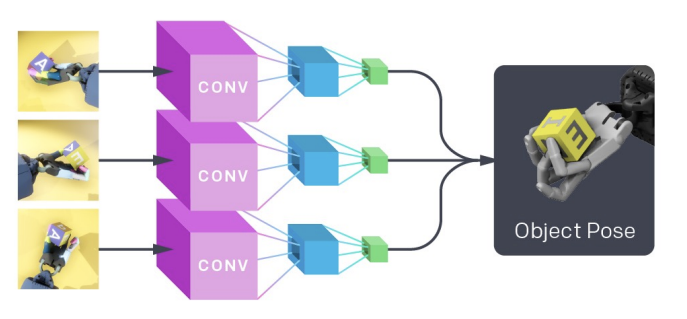
2. 強化学習を介して目標条件付きポリシーを学習します。これは、視覚モデルからの推定値 (および望ましい目標状態) を使用して、ロボットハンドを制御するために使用されるコマンドを生成します。
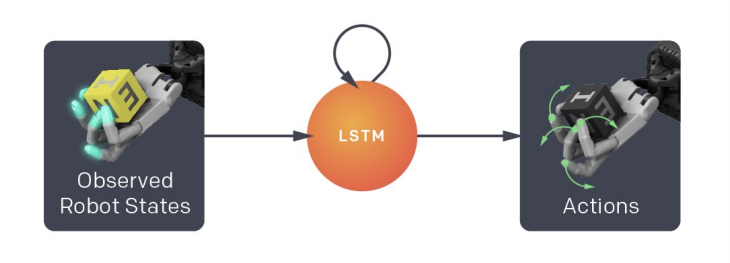
3. これらのモデルは両方とも完全にシミュレーションで学習されます。これらのモデルを現実世界に移行できるようにするために、それぞれのトレーニング分布にドメインランダム化を採用しています。ポリシーの場合、これにはさまざまなシミュレーター物理(さまざまな重力定数、摩擦係数など)を使用したトレーニングが含まれます。ビジョンモデルの場合、OpenAI Remote Rendering Backend(ORRB)を使用して、外観のさまざまな側面をランダム化した高品質のシーン画像をレンダリングします。以下にサンプル画像を示します。

現実世界でロボットを実験するときは、ビジョン モデルとポリシーを組み合わせます。
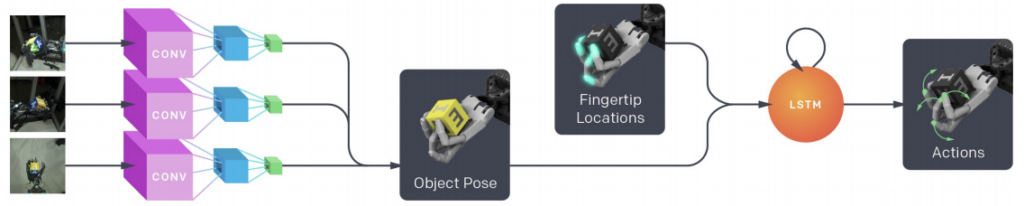
強化学習と行動クローニング
コンテクスト
ルービック キューブの結果を出荷した後、画像から直接ポリシーを学習することによって (つまり「エンドツーエンド」) 、学習の問題を 1 つのステップに減らすことができるかどうかを調査し、次のようなポリシーを作成しました。
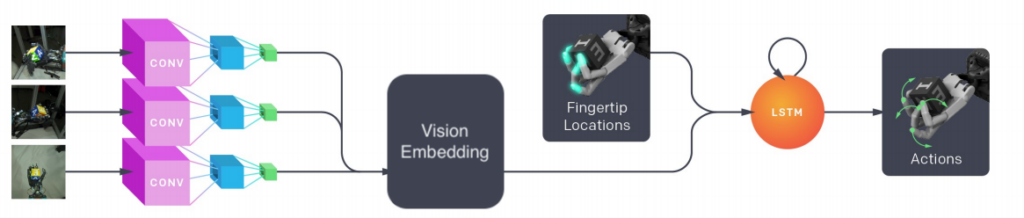
エンドツーエンドの学習には利点があり (例: 明示的な状態表現を設計する必要がない、概念が単純)、最近のリリースでそれがどの程度うまく機能するかを知ることは、将来の研究の方向性を決定するのに役立ちます。私たちは、簡潔にするために、この調査を Learning Dexterity のセットアップ、つまりブロックの再方向付けに限定することにしました。
仮説/研究上の疑問
-
ブロック再配置タスクを解決するためにエンドツーエンドのポリシーをトレーニングできますか?
-
これをより効率的に行うために、以前にトレーニングされた状態ベースのポリシーと動作クローニング(BC)を使用できますか?
-
強化学習(RL) を使用して、このようなポリシーを「ゼロから」トレーニングすることは可能ですか?
-
2 と 3 が「はい」の場合、RL は BC と比べてどれくらい「高価」ですか?
-
これらのポリシーを正常にトレーニングするには、どのような変更 (事前トレーニング済みのビジョン モデルの使用など) が重要ですか?
プラン
-
動作クローニングを使用して、エンドツーエンドのポリシーをトレーニングしてみます。事前トレーニング済みのビジョン モデルの使用、バッチ サイズ、ビジョン モデル アーキテクチャなど、さまざまな側面を繰り返します。
-
行動クローニングが成功した場合は、(1)の最適な設定を使用してRL経由でポリシーをトレーニングします。
結論
-
事前トレーニング済みの状態ベースのポリシーを「教師」として使用することで、Behavioral Cloning を使用してエンドツーエンドのポリシーを (比較的) 効率的にトレーニングできることがわかりました。以下のパート 1 では、モデル サイズ、バッチ サイズ、事前トレーニング済みのビジョン「サブモデル」の使用に関する考察など、ここでの調査結果を詳しく説明します。ここで最も注目すべき調査結果は、事前トレーニング済みのビジョン サブモデルを使用すると、トレーニングが 4 倍高速化されることです。
-
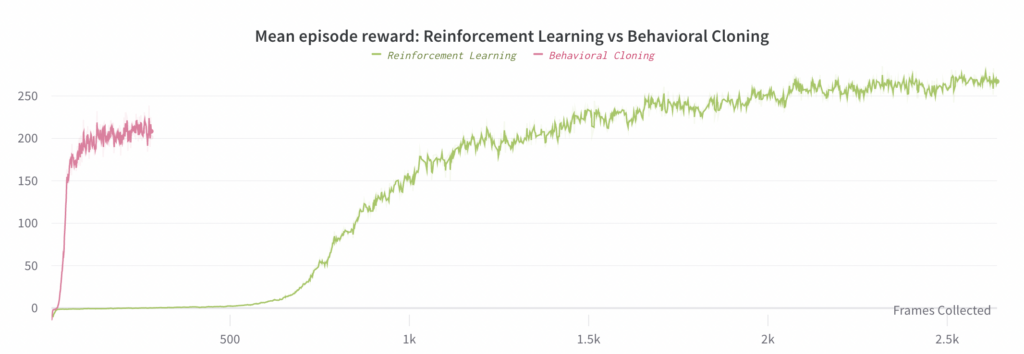
強化学習を使用してエンドツーエンドのポリシーを学習することもできますが、そのためには行動クローニングよりも約 30 倍多くの計算が必要です(両方とも事前トレーニング済みの視覚サブモデルを使用する場合)。パート 2 では、この実験の詳細と、最良の行動クローニング実験との比較について説明します (主な結果は下のグラフにあります)。
パート 1: 行動クローニング
OpenAI のロボティクス チームでは、すでにトレーニング済みのポリシーを使用してポリシーをすばやくトレーニングするために、Behavioral Cloningを頻繁に使用しています。これは、異なるモデル アーキテクチャや観測空間でポリシーのトレーニングをすぐに開始するなど、いくつかのシナリオで役立つことがわかりました。詳細については、ルービック キューブの論文のセクション 6.4 を参照してください。したがって、状態ベースのポリシーをエンドツーエンドのポリシーに複製できるかどうかを確認することからこの調査を開始するのは自然な流れでした。
幸いなことに、行動クローニングはエンドツーエンドのポリシーのトレーニングに非常に効果的であることがわかりました。行動クローニングは実質的には教師あり学習の一種であるため、強化学習に比べて、はるかに小さなバッチ サイズを使用でき、エンドツーエンドのポリシーを収束までトレーニングするために必要な最適化手順がはるかに少なくなります。これは、エンドツーエンドのポリシーをトレーニングする場合に特に有益です。GPU あたりの最大バッチ サイズは状態ベースのポリシーよりもはるかに小さいためです (はるかに大きい観測とビジョン モデルのアクティベーションのサイズが大きいため)。
これらの実験では、元の教師あり状態予測学習タスクをさらに活用して、ビジョン サブモデルを事前トレーニングしました (つまり、そのタスクに収束するようにビジョン モデルをトレーニングし、結果のパラメーターを最後から 2 番目のレイヤーまで使用して、エンドツーエンドのポリシーでビジョン サブモデルを初期化しました)。
次のサブセクションでは、Behavioral Cloning を使用して実行したいくつかの興味深いアブレーション実験の結果を示します。結論は次のとおりです。
-
個別の埋め込みマッピングの学習:ポリシーおよび価値関数ネットワークに対して個別の埋め込みマッピング (つまり、入力を埋め込み空間にマッピングする完全接続レイヤー。これはポリシー LSTM への入力になります) を学習すると、トレーニングが大幅に高速化されることがわかりました。
-
モデル アーキテクチャ:ビジョン サブモデルに ResNet50 とIMPALAの大型ビジョン エンコーダーという 2 つの異なるアーキテクチャを試したところ、収束に必要な計算と最終的なパフォーマンスの両方において ResNet50 の方が優れていることがわかりました。
-
バッチ サイズ:合計有効バッチ サイズを 512、1024、2048 (GPU オプティマイザーの数をスケーリングすることで実現) で試した結果、1024 が最高の計算効率を実現しながら、最終的なパフォーマンスを最大化できることがわかりました。
-
ビジョン モデルの事前トレーニング:事前トレーニング済みモデルを使用すると、ランダムに初期化されたビジョン サブモデルを使用する場合と比較して、トレーニングが約 4 倍高速化されることがわかりました。
行動クローニングアブレーション1: 個別の埋め込みマッピングの学習
ルービックキューブの論文のセクション 6.2 で説明されているように、ポリシーおよび価値関数ネットワークへのすべての入力を 512 次元空間に埋め込み、それらを合計し、ポリシーおよび価値関数ネットワークに渡す前に非線形性を適用します。
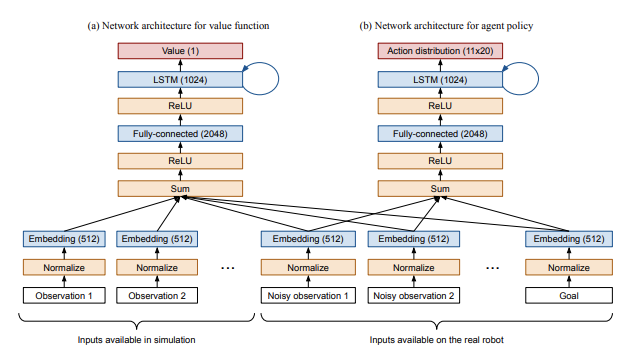
エンドツーエンドのポリシーでは、ポリシー ネットワークで使用できる観測が異なるだけで、同じ設定を使用して開始しました。具体的には、状態観測を削除し、ビジョン サブモデルの出力からの観測を追加しました。ビジョン サブモデルの出力は、他の入力と同じように扱われることに注意してください。つまり、他のすべての入力と同じ 512 次元空間に埋め込むために、完全に接続されたレイヤーを適用します。これらの完全に接続されたレイヤーを「埋め込みマッピング」と呼びます。
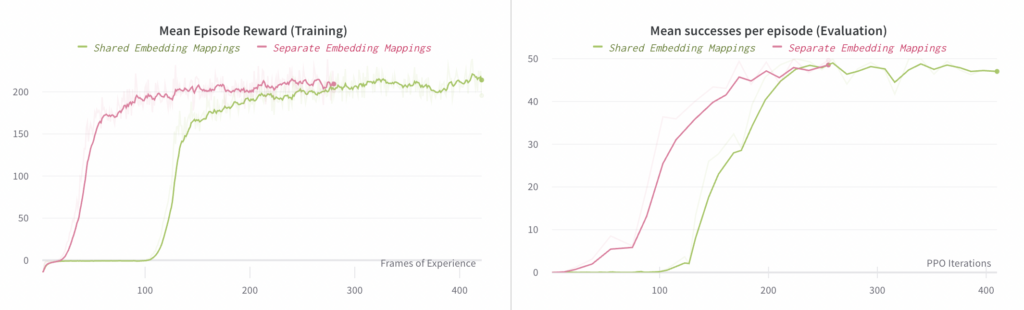
ルービックキューブのリリースでは、これらの埋め込みマッピングをポリシーネットワークと価値関数ネットワーク間で共有していました。しかし、エンドツーエンドのポリシーをトレーニングする場合、個別の埋め込みマッピングを学習する方が約 2 ~ 3 倍高速であることがわかりました。これは、価値関数とポリシーネットワークの最適化間の干渉によるものだと考えています。価値関数は完全な状態情報にアクセスできるため、ビジョンサブモデルからの (比較的ノイズの多い) 出力は必要なく、ビジョン埋め込みをゼロに近づけます。ポリシーネットワークは、もちろん、環境の状態を理解するためにこのビジョン埋め込みを必要とします。これが競合の原因です。
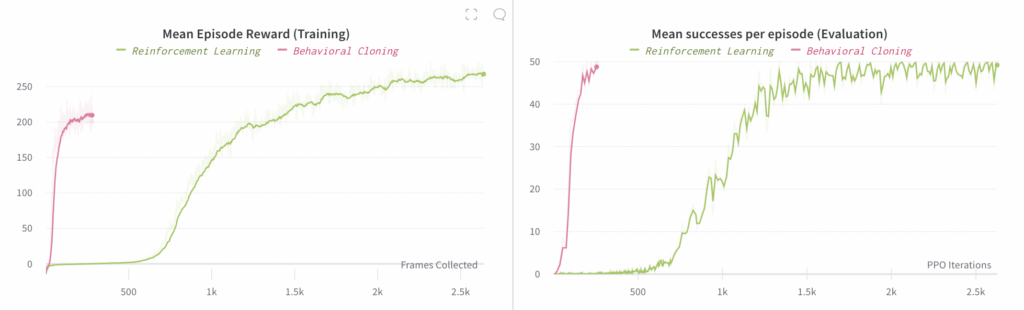
以下では、個別の埋め込みマッピングと共有の埋め込みマッピングを使用した実験の進行状況を比較します。左側のグラフは、エンドツーエンド ポリシーのロールアウトで観測された平均報酬を比較しています (これらのロールアウトはトレーニングに使用されます)。右側のグラフは、エピソードごとの成功の平均数を比較しています。ここで、「成功」とは、ブロックを目的の目標に再方向付けすることです。各エピソードの成功数は最大 50 に制限されています。
左側のプロットの x 軸は # 収集されたフレーム数 (つまり、消費されたデータの量) であるのに対し、右側のプロットの x 軸は # PPO反復回数 (つまり、最適化のステップ数) であることに注意してください。
ヒント:事前に少し時間をかけて適切なタイトルを書き、適切なスムージングを追加し、一貫した色付けを行うことで、チームメイトがレポートを読む時間を大幅に節約できます。
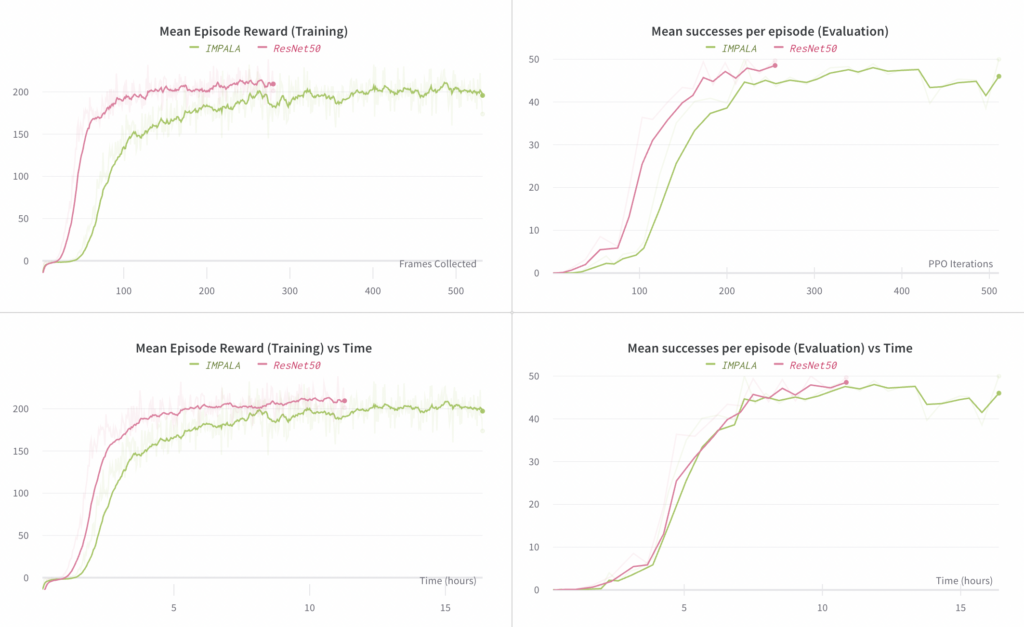
行動クローニングアブレーション2: モデルアーキテクチャ
ここで、ビジョン サブモデル アーキテクチャの選択を取り上げます。ResNet50 (ルービック キューブ リリースで使用) と、はるかに小さい IMAPALA ビジョン エンコーダ (IMPALA論文の図 3 の右側の画像) を比較します。ResNet50 モデルは、IMPALA エンコーダに比べて最終的なパフォーマンスがわずかに高く (成功の平均数で)、収束に必要なステップ数が少ないことがわかりました。 各ステップの時間は ResNet50 実験の方がわずかに長くなりますが、経過時間で見ると IMPALA 実験よりも収束が早くなります。
左側のグラフは、エンドツーエンド ポリシーのロールアウトで観測された平均報酬を比較しています (これらのロールアウトはトレーニングに使用されます)。右側のグラフは、エピソードごとの成功の平均数を比較しています。ここでの「成功」には、ブロックを目的の目標に再方向付けすることが含まれます。各エピソードの成功数は最大 50 に制限されています。
ヒント:セクションを複製すると、プロットを設定する面倒な作業が軽減されます。
行動クローニングアブレーション3: バッチサイズ
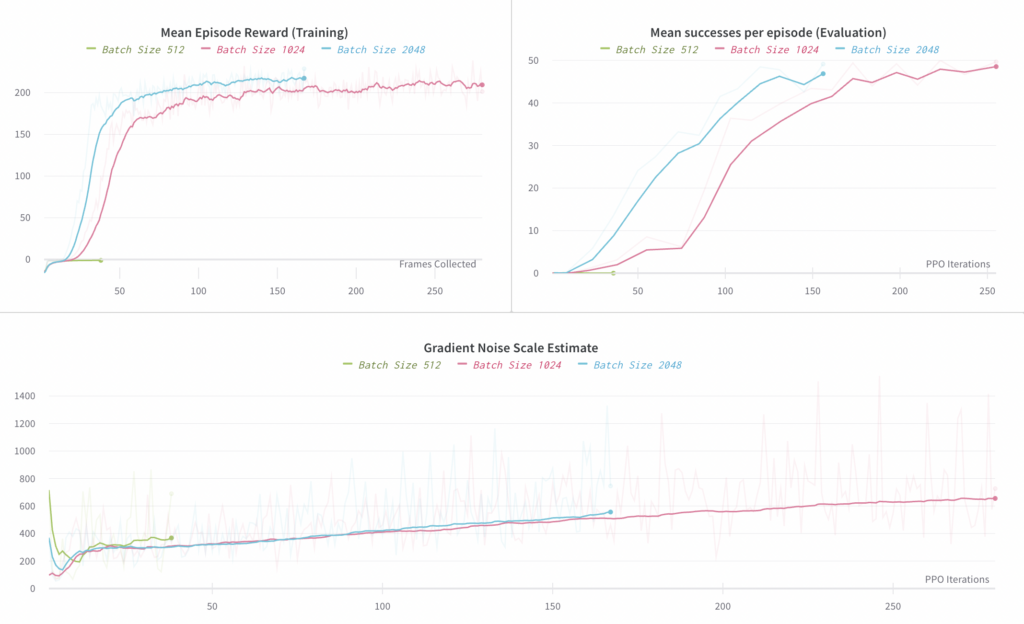
ここでは、使用したバッチ サイズの合計を 512、1024、2048 で比較します。バッチ サイズ 512 は機能しなかったようです (38 ステップ後に負の平均報酬が見られましたが、1024 の実験では、同じ数のサンプルを処理した後、正の平均報酬が見られました)。バッチ サイズ 1024 と 2048 はどちらも機能しましたが、バッチ サイズ 2048 ではトレーニングが約 30% しか高速化されないため、サンプルと計算の効率の点では 1024 が最適であると考えられます。これは、以下の平均報酬と収集されたフレームの最初のグラフで最も簡単に確認できます。
左側のグラフは、エンドツーエンド ポリシーのロールアウトで観測された平均報酬を比較したものです (これらのロールアウトはトレーニングに使用されます)。右側のグラフは、エピソードごとの成功の平均数を比較したものです。ここでの「成功」には、ブロックを目的の目標に再方向付けすることが含まれます。各エピソードの成功数は最大 50 に制限されています。
以下に、 「大規模バッチトレーニングの実証モデル」で説明されているように、勾配ノイズスケールの推定値をプロットします。収束時には約 700 であり、その付近で臨界バッチサイズであることを示しています。ただし、勾配ノイズスケールの動作は動作クローニングでは十分に研究されていないため、ここでは主に、どのバッチサイズを目標にすべきかを大まかに理解するために使用しました。バッチサイズの最適な桁数を正しく予測するため、この目的に役立ちました。
ヒント:このメトリックのように、一部のメトリックは他のメトリックよりもノイズが多いため、プロット固有のスムージングを適用するのが最適です。
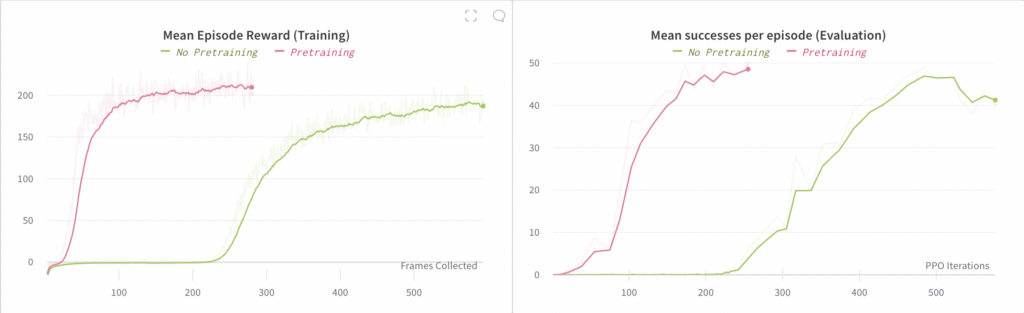
行動クローニングアブレーション4:事前トレーニング
ここでは、事前トレーニング済みのビジョン サブモデルの使用を廃止します。事前トレーニングを使用せずにエンドツーエンドのポリシーをトレーニングすることはできますが、収束に4 倍時間がかかることがわかりました。
左側のグラフは、エンドツーエンド ポリシーのロールアウトで観測された平均報酬を比較したものです (これらのロールアウトはトレーニングに使用されます)。右側のグラフは、エピソードごとの成功の平均数を比較したものです。ここでの「成功」には、ブロックを目的の目標に再方向付けすることが含まれます。各エピソードの成功数は最大 50 に制限されています。
パート 2: 強化学習と行動クローニング
上記のアブレーションを完了したら、アブレーションごとに最適な全体的なセットアップを採用し、強化学習を介してエンドツーエンドのポリシーをトレーニングするために使用しました。この場合も、行動クローニング実験と同様に事前トレーニング済みのモデルが使用されたことに注意してください。
RL によるエンドツーエンドのポリシーのトレーニングは機能することがわかりました。ただし、Behavioral Cloning よりもかなり遅くなりますが、これは予想どおりです。ここでは、コンピューティング要件がはるかに高いため、1 つの実験のみを実行しました。RL 実験では 128 個の V100 GPU を 4 日間必要としましたが、Behavioral Cloning では 48 個の V100 GPU を 8 時間必要としました。合計すると、RL のコンピューティングは Behavioral Cloning の約 30 倍、ステップあたりのコンピューティングは約 2.67 倍になります。この結論の主な価値は、RL を使用してエンドツーエンドのポリシーを学習することは依然として可能であるが、さらなる最適化が見つからない限り、一般に非常に多くのコンピューティングが必要になることを示していることです。
RL 実験で使用されるバッチ サイズがはるかに大きいため、以下の 2 つのグラフの形状が異なっていることに注意してください (左側のグラフでは収集されたフレームの x 軸が使用されているため)。