
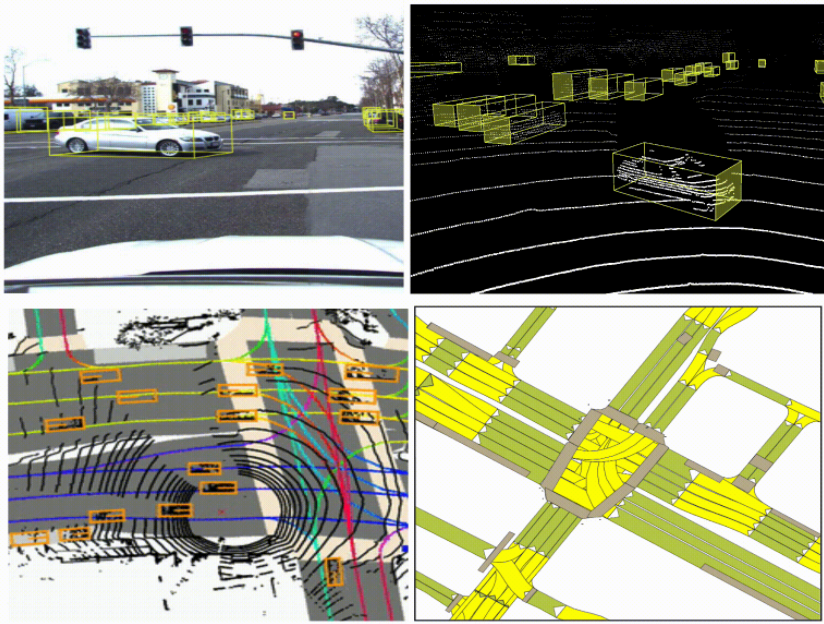
자율주행차의 인식은 카메라, 라이더 , 레이더와 같은 보완적인 센서 모드에 따라 달라집니다.
예를 들어, 라이더는 매우 정확한 깊이를 제공하지만 장거리에서는 희소할 수 있습니다. 카메라는 장거리에서도 밀도 있는 의미 신호를 제공할 수 있지만 객체의 깊이를 포착하지 못합니다.
이러한 센서 모달리티를 융합함으로써, 우리는 그들의 보완적인 강점을 활용하여 단일 센서 모달리티에만 의존하는 것보다 더 정확한 에이전트(예: 자동차, 보행자, 자전거 타는 사람)의 3D 감지를 달성할 수 있습니다. 자율 주행 연구를 가속화하기 위해 Lyft는 자율 주행 차량의 데이터를 공유하여 인식 및 예측 문제를 해결합니다 .
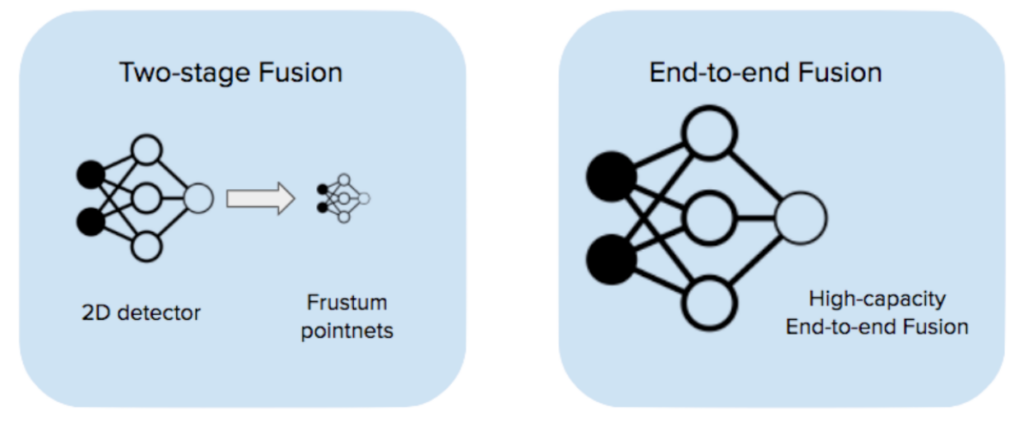
카메라와 라이더를 융합하는 데에는 많은 전략이 있습니다. 관심 있는 독자는 아래 리소스 [1-6]에서 다양한 융합 전략에 대한 포괄적인 검토를 찾을 수 있습니다. 여기서는 딥 신경망을 모두 활용하는 두 가지 전략만 고려합니다.
한 가지 전략은 frustum pointnets와 같은 2단계 융합을 통한 것입니다[1] : 첫 번째 단계는 카메라 이미지를 가져와 2차원 감지를 출력하는 이미지 감지 모델입니다. 두 번째 단계는 2차원 감지 제안을 가져와 3차원에서 frustum을 만들고 각 frustum 내에서 lidar 기반 감지를 실행합니다. 우리는 초기 스택에서 이 전략을 채택했고 좋은 결과를 얻었습니다( 자세한 내용은 블로그 게시물을 확인하세요 ).
그러나 2단계 퓨전 성능은 비전 모델이나 라이더 모델에 의해 제한됩니다. 두 모델 모두 단일 모달리티 데이터를 사용하여 학습되었으며 두 센서 모달리티를 직접 보완하는 방법을 학습할 기회가 없습니다.
카메라와 라이더를 융합하는 또 다른 방법은 엔드투엔드 융합(EEF)입니다. 모든 원시 카메라 이미지(우리의 경우 6개)와 라이더 포인트 클라우드를 입력으로 사용하여 엔드투엔드 학습하는 단일 고용량 모델을 사용합니다. 이 모델은 각 모달리티에서 별도의 피처 추출기를 실행하고 융합된 피처 맵에서 감지를 수행합니다. 이 보고서에서는 엔드투엔드 카메라-라이더 융합에 대한 우리의 견해를 논의하고 Jadoo, 내부 ML 프레임워크 및 W&B로 수행한 실험 결과를 제시합니다.
엔드투엔드 퓨전은 2단계 퓨전보다 성능이 더 좋습니다.
종단간 훈련된 EEF는 2단계 융합에 비해 몇 가지 주요 이점이 있습니다.
-
이미지와 라이더 피처의 융합은 모델 내부에서 발생하며 학습 중에 종단 간 학습됩니다. 즉, 휴리스틱과 하이퍼파라미터가 줄어들고 네트워크는 입력에서 출력까지 더 복잡한 매핑을 학습할 수 있는 용량이 있습니다.
-
EEF 모델은 훈련 중 데이터 드롭아웃을 통해 두 모달리티 모두에서 누락된 데이터에 대해 결함 허용성을 갖도록 훈련될 수 있습니다. 이에 비해 2단계 모델은 동일한 수준의 결함 허용성을 달성하기가 더 어렵습니다.
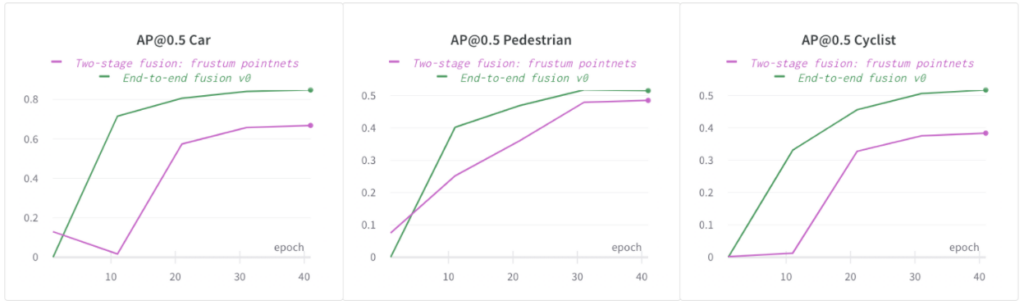
다음 그림에서 엔드투엔드 퓨전 모델이 사내 데이터 세트에서 자동차, 보행자, 자전거 타는 사람에 대한 2단계 퓨전 모델보다 훨씬 높은 AP@0.5를 제공하는 것을 볼 수 있습니다. 다른 클래스(자동차 및 자전거 타는 사람)에서도 동일한 추세를 관찰했습니다 . 단순화를 위해 보고서의 나머지 섹션에서 보행자에 대한 AP만 비교합니다.
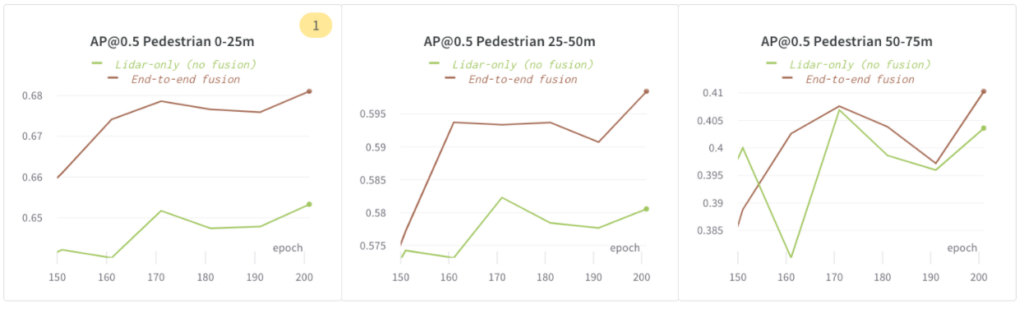
End-to-End Fusion은 Lidar 전용 모델보다 더 나은 성능을 발휘합니다.
우리는 이미지 피처를 융합하면 모델링 정확도가 높아지는지 알아보기 위해 이 실험을 했습니다. 우리는 다음 구성을 사용했습니다.
-
Lidar 전용(퓨전 없음): Lidar 전용 모델
-
엔드투엔드 퓨전: 이미지 및 라이더를 통한 엔드투엔드 학습 퓨전
다음 그림에서는 보행자가 75m 범위에 있을 때 AP@0.5에서 `End-to-end fusion`이 `Lidar 단독(fusion 없음)`보다 더 나은 성능을 보임을 보여주었습니다.
모델 용량 및 과적합 균형 조정
더 높은 모델 용량 = 향상된 정확도
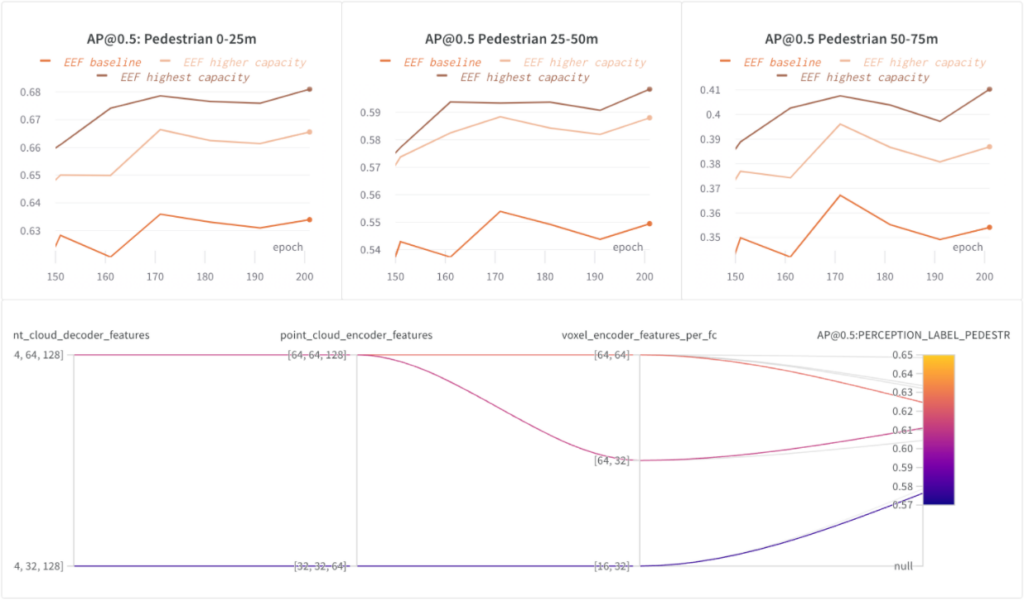
우리는 EEF 모델 내에서 특징 추출기의 용량을 늘리고 용량이 증가하는 세 가지 구성( EEF 기준, EEF 더 높은 용량 , E EF 가장 높은 용량) 을 훈련했습니다 .
다음 그래프에서 우리는 더 높은 모델 용량이 도움이 된다는 것을 보여주었습니다. 가장 높은 모델 용량(포인트 클라우드 인코더/디코더 기능 수)은 75m 범위 내 보행자의 AP@0.5를 약 5% 높였습니다.
데이터 증강을 통한 과적합 해결
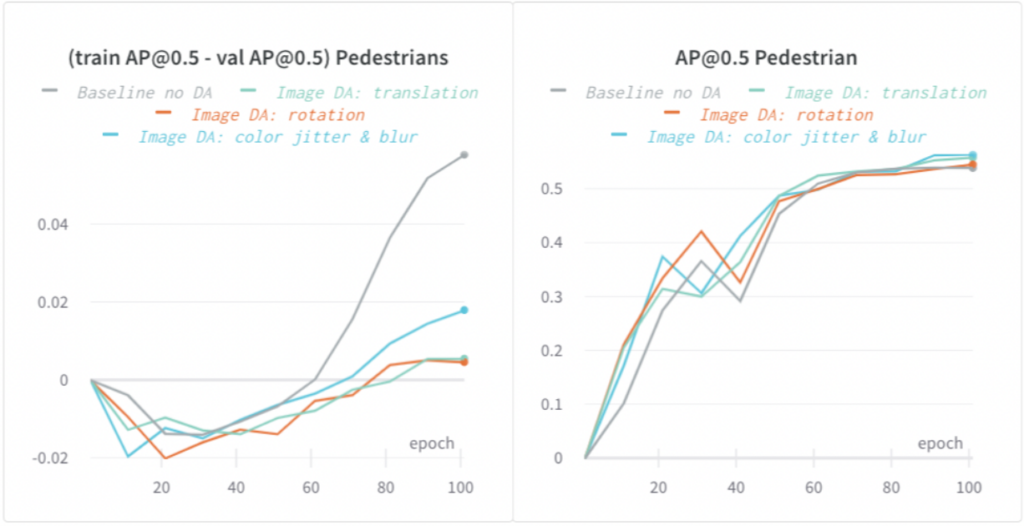
EEF 모델은 고용량 모델이며 과적합에 더 취약합니다. 과적합의 한 가지 징후는 학습 메트릭이 개선되는 반면 검증 메트릭은 개선되지 않는 것입니다(또는 학습 메트릭과 검증 메트릭 간의 격차가 커짐).
우리는 이미지와 라이더 데이터 증강(DA)을 모두 적용했고 과적합을 상당히 줄였습니다. 다음 그래프에서 우리는 다양한 유형의 이미지 기반 DA가 보행자에 대한 훈련과 검증 AP @0.5 간의 격차를 최대 5%까지 줄이고 모델 일반화를 개선했음을 보여주었습니다.
더 빠른 교육: 반복 속도가 중요합니다
이미지 드롭아웃 및 반해상도 이미지 사용으로 더 빠른 학습
대용량 EEF 모델을 훈련하는 데는 다음과 같은 이유로 느릴 수 있습니다.
-
대용량의 기여를 고려하면 컴퓨팅이 대규모입니다.
-
모델의 GPU 메모리 풋프린트가 큽니다. 즉, 훈련 중에 큰 배치 크기를 사용하면 모델이 GPU 메모리가 부족해질 가능성이 더 큽니다. 더 작은 배치 크기를 사용하도록 강제하면 훈련 속도가 느려집니다.
-
대용량 입력(6배의 전체 해상도 카메라 이미지 + 라이더 스핀, 자세한 내용은 Lyft 레벨 5 오픈 데이터세트 에서 확인할 수 있음 )을 고려하면 데이터 로딩에 시간이 걸립니다.
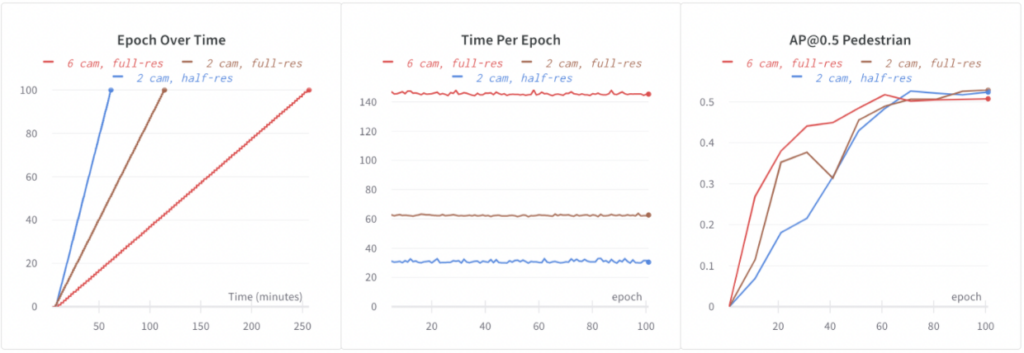
Baseline EEF는 모든 6개의 전체 해상도 이미지에서 학습합니다. 64개 GPU에서 100개의 에포크를 학습하는 데 4.3시간이 걸렸습니다. EEF에서 더 빠르게 반복하려면 학습 속도를 높여야 합니다. 다음 구성을 실험했습니다.
-
6캠, 풀 해상도: 기준 EEF.
-
2 cam, full-res: 훈련 중에 무작위 이미지 드롭아웃을 사용했습니다. 훈련 중에 6개 이미지 중 4개를 무작위로 드롭아웃했습니다. 이를 통해 컴퓨팅 및 데이터 로딩 시간이 단축되었고 훈련 속도가 2.3배 빨라졌습니다. 또한 드롭아웃은 정규화에 도움이 되었고, 아마도 이로 인해 더 나은 정확도를 관찰했습니다(아래에 표시됨: 보행자의 경우 +1.5% AP@0.5).
-
2 캠, 반해상도: 우리는 반해상도 이미지를 사용하여 이미지 해상도를 더욱 줄였습니다. 이는 정확도 회귀 없이 전체 해상도 이미지를 사용하는 것보다 2배 더 빠른 학습으로 이어졌습니다.
이미지 드롭아웃과 절반 해상도 이미지의 도움으로 EEF 훈련 속도가 4.3배 빨라졌고, 모델 정확도도 개선되었습니다.
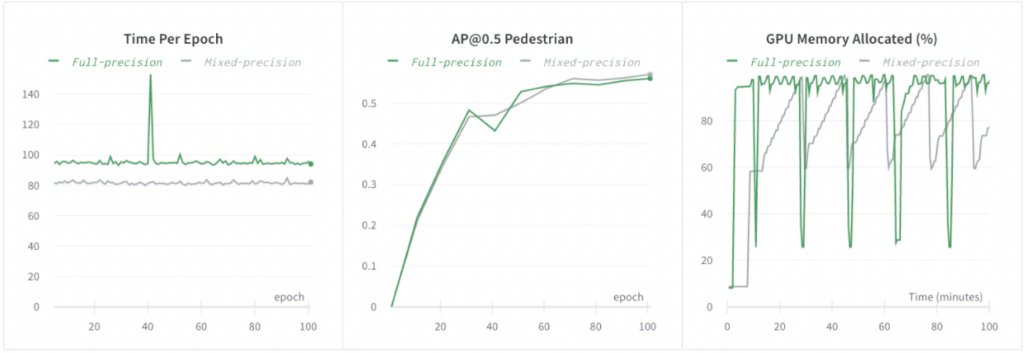
혼합 정밀도 훈련
영향
-
우리는 대용량 엔드투엔드 퓨전이 3D 감지를 위한 2단계 퓨전이나 라이더 전용 모델보다 더 나은 성능을 발휘한다는 것을 보여주었습니다.
-
우리는 대용량 모델을 훈련하고, 과도한 적합을 줄이는 동시에 모델 용량을 늘리고, 빠른 반복 속도를 유지하는 워크플로를 시연했습니다.
Lyft 레벨 5에 대해 자세히 알아보세요
감사의 말
이 보고서는 저자와 아나스타샤 두브로비나, 드미트로 코르두반, 에릭 빈센트, 린다 왕이 수행한 작업을 기반으로 작성되었습니다.