

Methoden zur automatisierten Hyperparameteroptimierung
Die drei wichtigsten Algorithmen bei der automatisierten Hyperparameteroptimierung sind
-
Rastersuche
Der Hauptunterschied zwischen den drei Algorithmen besteht darin, wie sie den Satz von Hyperparameterwerten auswählen, der als nächstes getestet werden soll. Sie unterscheiden sich aber auch darin, wie Sie den Suchraum definieren (feste Werte vs. Wertebereiche) und wie Sie die Anzahl der Durchläufe angeben (implizit vs. explizit).
In diesem Abschnitt werden diese Unterschiede sowie ihre Vor- und Nachteile untersucht.
Ich werde im Folgenden W&B Sweeps verwenden, um die Hyperparameter Epochen und Lernrate zu optimieren . Weitere Einzelheiten finden Sie in meinem zugehörigen Kaggle Notebook und W&B-Projekt .
Rastersuche
Die Rastersuche ist eine Technik zur Optimierung von Hyperparametern, die alle möglichen Hyperparameterkombinationen in einem angegebenen Raster (kartesisches Produkt) auswertet. Es handelt sich um einen Brute-Force-Ansatz, der nur für ML-Modelle mit wenigen Hyperparametern empfohlen wird.
Eingänge
-
Eine Reihe von Hyperparametern, die Sie optimieren möchten
-
Ein diskretisierter Suchraum für jeden Hyperparameter entweder als spezifische Werte
-
Eine Leistungsmetrik zur Optimierung
-
(Implizite Anzahl von Durchläufen: Da der Suchraum ein fester Wertesatz ist, müssen Sie die Anzahl der durchzuführenden Experimente nicht angeben.)
(Die Unterschiede zwischen der Zufallssuche und der Bayesschen Optimierung sind oben fett hervorgehoben.)
Eine beliebte Möglichkeit, die Grid-Suche in Python zu implementieren, ist die Verwendung von GridSearchCV aus der Scikit-Learn -Bibliothek. Alternativ können Sie, wie unten gezeigt, eine Grid-Suche zur Hyperparameter-Optimierung mit W&B einrichten:

Vorgehensweise
Schritt 1: Der Rastersuchalgorithmus wählt eine Reihe von Hyperparameterwerten zur Auswertung aus, indem er ein Raster (kartesisches Produkt) aller möglichen Hyperparameterkombinationen der angegebenen Hyperparameterwerte erstellt. Anschließend iteriert er einfach über das Raster. Dieser Ansatz ist eine erschöpfende Suche oder ein Brute-Force-Ansatz.
Unten sehen Sie das resultierende Raster für unser Beispiel.
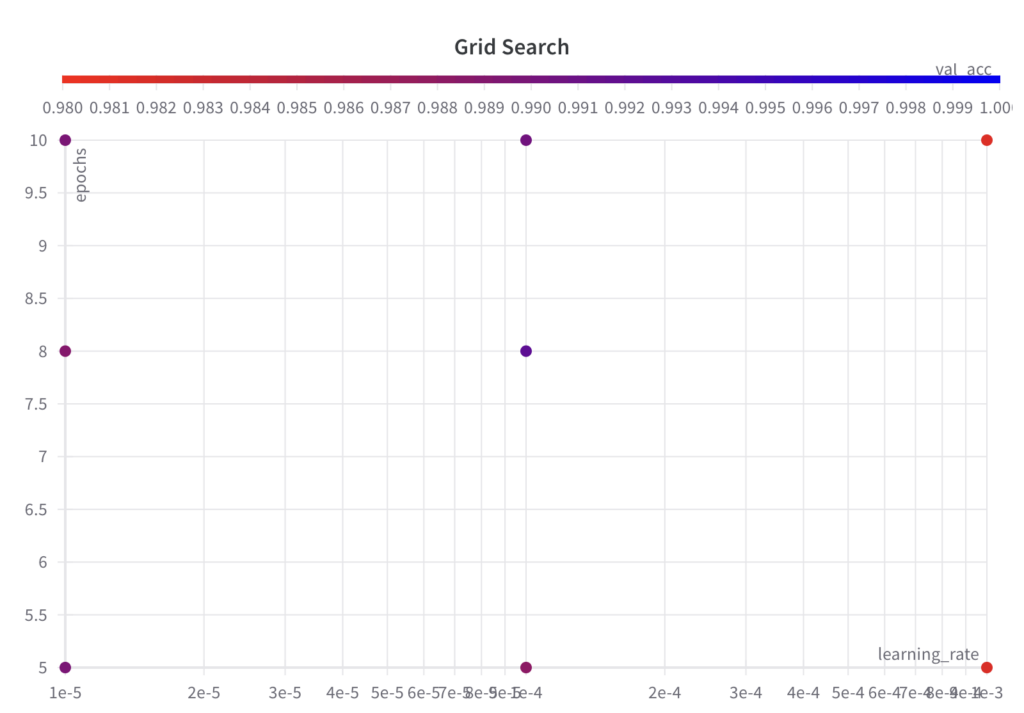
Schritt 2: Führen Sie ein ML-Experiment für den ausgewählten Satz von Hyperparametern und deren Werte durch und bewerten und protokollieren Sie die Leistungsmetrik.
Schritt 3: Wiederholen Sie den Vorgang für die angegebene Anzahl von Probeläufen oder bis Sie mit der Leistung des Modells zufrieden sind.
Ausgabe
Wie bei allen automatisierten Algorithmen zur Hyperparameteroptimierung gibt Grid Search das Experiment mit der besten Leistungsmetrik und den jeweiligen Hyperparameterwerten zurück.
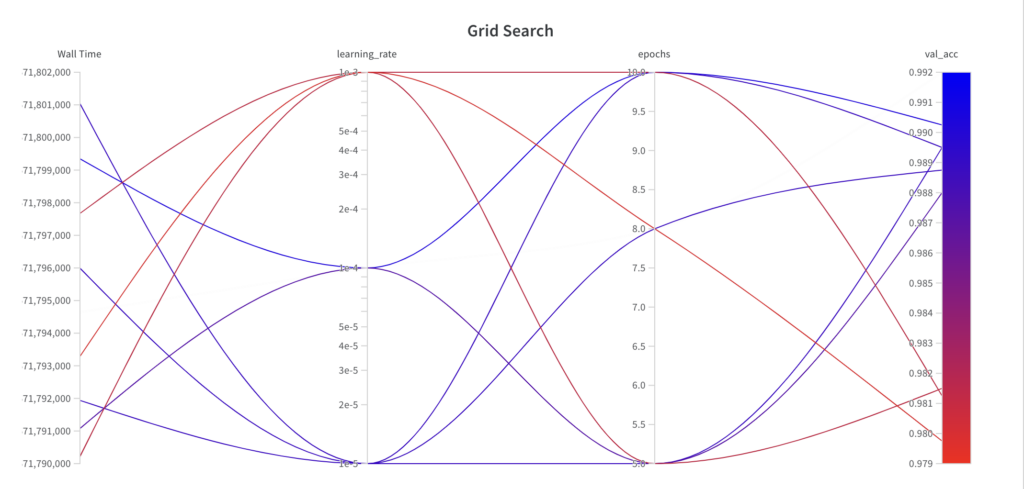
Unten sehen Sie, zu welchem Zeitpunkt der Hyperparameter-Optimierungsalgorithmus welche Parameter gewählt hat und welche Leistung sich daraus ergibt. Sie können folgende Beobachtungen machen:
-
Der Rastersuchalgorithmus iteriert wie angegeben über das Raster der Hyperparametersätze.
-
Da es sich bei der Grid-Suche um einen uninformierten Suchalgorithmus handelt, lässt sich bei der resultierenden Leistung im Laufe der Durchläufe kein Trend erkennen.
-
Der beste val_acc- Score beträgt 0,9902
Vorteile
-
Einfach zu implementieren
-
Kann parallelisiert werden: da die Hyperparametersätze unabhängig voneinander ausgewertet werden können
Nachteile
-
Nicht geeignet für Modelle mit vielen Hyperparametern: Dies liegt vor allem daran, dass der Rechenaufwand exponentiell mit der Anzahl der Hyperparameter wächst
-
Uninformierte Suche , da das Wissen aus früheren Experimenten nicht genutzt wird. Um gute Ergebnisse zu erzielen, sollten Sie den Rastersuchalgorithmus möglicherweise mehrmals mit einem fein abgestimmten Suchraum ausführen.
Sofern Sie nicht drei oder weniger Hyperparameter optimieren müssen, wird im Allgemeinen empfohlen, die Rastersuche zu vermeiden.
Zufallssuche
Die Zufallssuche ist eine Technik zur Optimierung von Hyperparametern, bei der Werte aus einem bestimmten Suchraum nach dem Zufallsprinzip ausgewählt werden. Sie ist effektiver als die Rastersuche für ML-Modelle mit vielen Hyperparametern, von denen nur wenige die Leistung des Modells beeinflussen [1].
Eingänge
-
Eine Reihe von Hyperparametern, die Sie optimieren möchten
-
Ein kontinuierlicher Suchraum für jeden Hyperparameter als Wertebereich
-
Eine Leistungsmetrik zur Optimierung
-
Explizite Durchlaufzahl: Da der Suchraum kontinuierlich ist, müssen Sie die Suche manuell stoppen oder eine maximale Durchlaufzahl definieren.
Die Unterschiede zur Rastersuche sind oben fett hervorgehoben.
Eine beliebte Methode zum Implementieren einer Zufallssuche in Python ist die Verwendung von RandomizedSearchCV aus der Scikit-Learn -Bibliothek. Alternativ können Sie, wie unten gezeigt, eine Zufallssuche zur Hyperparameteroptimierung mit W&B einrichten.

Vorgehensweise
Schritt 1: Der zufällige Suchalgorithmus wählt einen Satz von Hyperparametern zur Auswertung aus, indem er für jede Iteration für die angegebene Anzahl von Iterationen zufällig Hyperparameterwerte aus dem angegebenen Suchraum auswählt.
Unten können Sie sehen, dass die abgetasteten Sätze von Hyperparameterwerten keinem Raster folgen wie im Rastersuchalgorithmus:
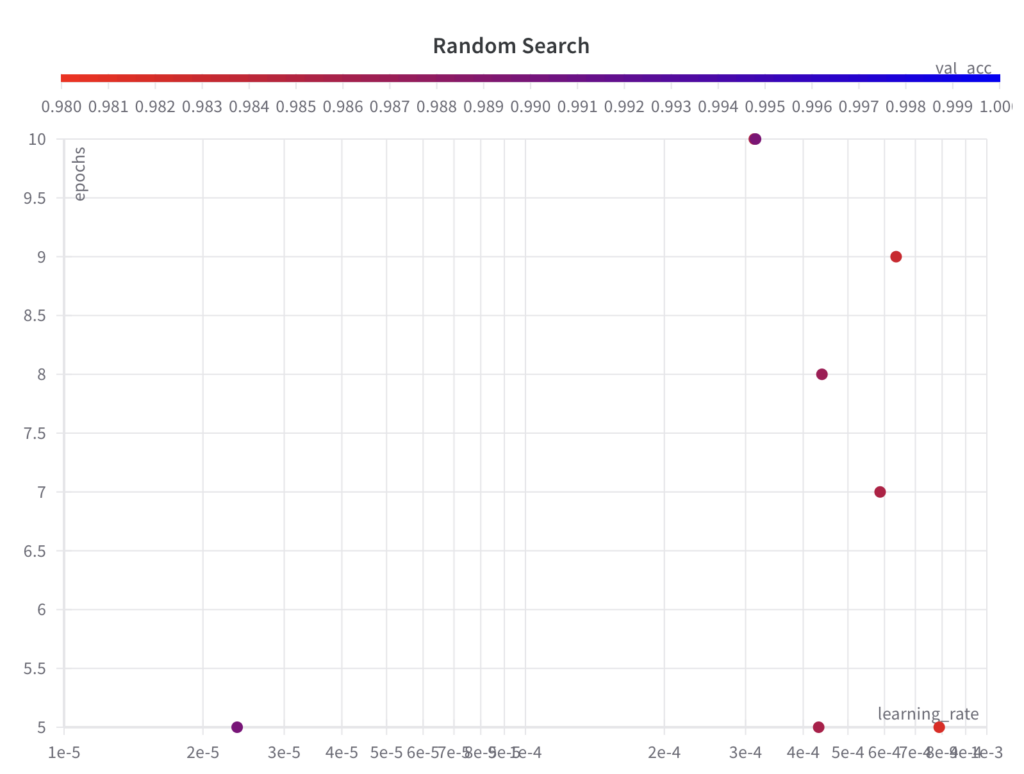
Schritt 2: Führen Sie ein ML-Experiment für den ausgewählten Satz von Hyperparametern und deren Werte durch und bewerten und protokollieren Sie die Leistungsmetrik.
Schritt 3: Wiederholen Sie den Vorgang für die angegebene Anzahl von Probeläufen.
Ausgabe
Wie bei allen automatisierten Hyperparameter-Optimierungsalgorithmen gibt Random Search das Experiment mit der besten Leistungsmetrik und den jeweiligen Hyperparameterwerten zurück.
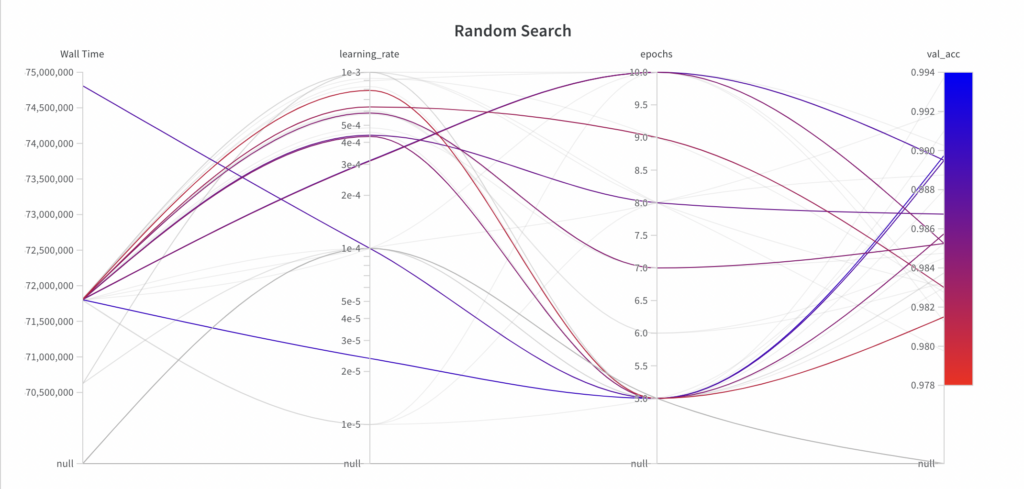
Unten sehen Sie, zu welchem Zeitpunkt der Hyperparameter-Optimierungsalgorithmus welche Parameter gewählt hat und welche Leistung sich daraus ergibt. Sie können folgende Beobachtungen machen:
-
Während die zufällige Suche für die Hyperparameter- Epochen Werte aus dem gesamten Suchraum abtastet , erkundet sie in den ersten paar Experimenten nicht den gesamten Suchraum für den Hyperparameter- Lernrate .
-
Da es sich bei der Zufallssuche um einen uninformierten Suchalgorithmus handelt, lässt sich bei der resultierenden Leistung im Laufe der Durchläufe kein Trend erkennen.
-
Der beste val_acc -Score beträgt 0,9868 und ist damit schlechter als der beste val_acc -Score, der mit der Grid-Suche erreicht wurde (0,9902). Der Hauptgrund dafür ist vermutlich die Tatsache, dass die Lernrate einen großen Einfluss auf die Leistung des Modells hat, was der Algorithmus in diesem Beispiel nicht richtig abtasten konnte.
Vorteile
-
Einfach zu implementieren
-
Kann parallelisiert werden : da die Hyperparametersätze unabhängig voneinander ausgewertet werden können
-
Geeignet für Modelle mit vielen Hyperparametern: Die Zufallssuche ist garantiert effektiver als die Gittersuche bei Modellen mit vielen Hyperparametern und nur einer kleinen Anzahl von Hyperparametern, die die Leistung des Modells beeinflussen [1]
Nachteile
-
Uninformierte Suche , da das Wissen aus früheren Experimenten nicht genutzt wird. Um gute Ergebnisse zu erzielen, sollten Sie den Zufallssuchalgorithmus möglicherweise mehrmals mit einem fein abgestimmten Suchraum ausführen.
Bayesianische Optimierung
Bayesianische Optimierung ist eine Technik zur Hyperparameter-Optimierung, die eine Ersatzfunktion verwendet, um den nächsten Satz von Hyperparametern zu bestimmen, die ausgewertet werden sollen. Im Gegensatz zur Rastersuche und zur Zufallssuche ist die Bayesianische Optimierung eine informierte Suchmethode.
Eingänge
-
Eine Reihe von Hyperparametern, die Sie optimieren möchten
-
Ein kontinuierlicher Suchraum für jeden Hyperparameter als Wertebereich
-
Eine Leistungsmetrik zur Optimierung
-
Explizite Durchlaufzahl: Da der Suchraum kontinuierlich ist, müssen Sie die Suche manuell stoppen oder eine maximale Durchlaufzahl definieren.
Die Unterschiede bei der Rastersuche sind oben fett hervorgehoben.
Eine beliebte Methode zur Implementierung der Bayes-Optimierung in Python ist die Verwendung von BayesianOptimization aus der Bibliothek bayes_opt . Alternativ können Sie, wie unten gezeigt, die Bayes-Optimierung für die Hyperparameter-Optimierung mit W&B einrichten.

Vorgehensweise
- Schritt 1: Erstellen Sie ein Wahrscheinlichkeitsmodell der Zielfunktion. Dieses Wahrscheinlichkeitsmodell wird als Ersatzfunktion bezeichnet. Die Ersatzfunktion stammt aus einem Gaußschen Prozess [2] und schätzt die Leistung Ihres ML-Modells für verschiedene Sätze von Hyperparametern.
- Schritt 2: Der nächste Satz Hyperparameter wird basierend darauf ausgewählt, was die Ersatzfunktion erwartet, um die beste Leistung für den angegebenen Suchraum zu erzielen.
Unten können Sie sehen, dass die abgetasteten Sätze von Hyperparameterwerten keinem Raster folgen wie im Rastersuchalgorithmus.
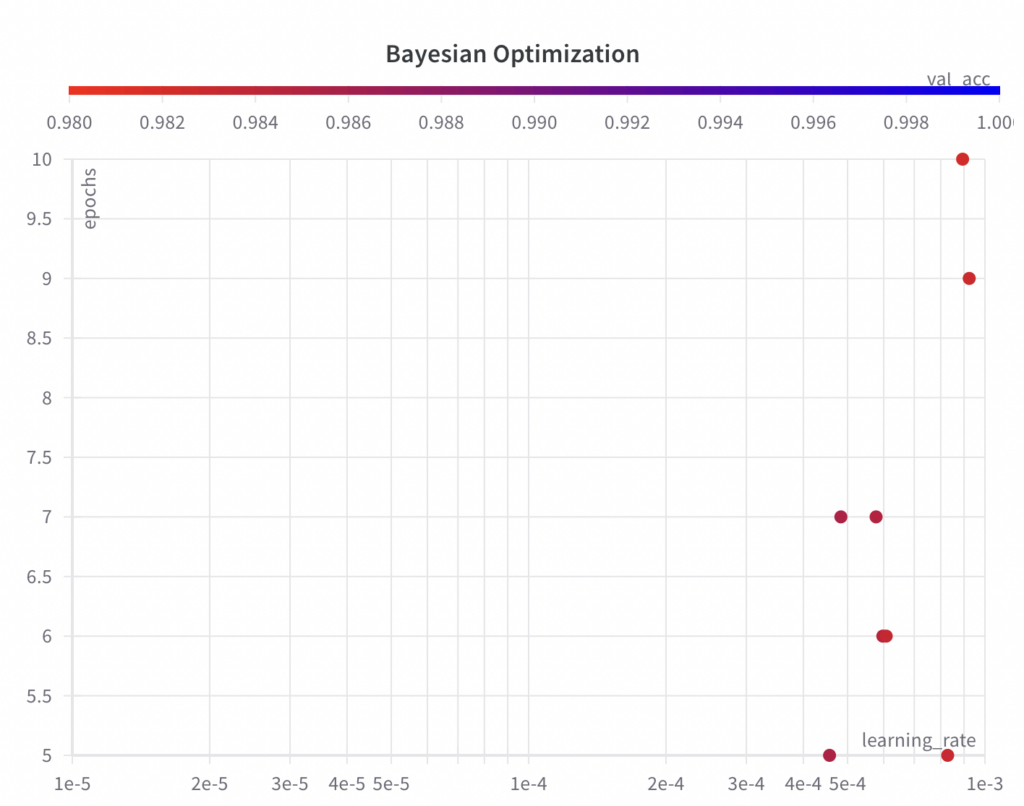
- Schritt 3: Führen Sie ein ML-Experiment für den ausgewählten Satz von Hyperparametern und deren Werte durch und bewerten und protokollieren Sie die Leistungsmetrik.
- Schritt 4: Nach dem Experiment wird die Ersatzfunktion mit den Ergebnissen des letzten Experiments aktualisiert.
- Schritt 5: Wiederholen Sie die Schritte 2 – 4 für die angegebene Anzahl von Probeläufen.
Ausgabe
Wie bei allen automatisierten Hyperparameter-Optimierungsalgorithmen gibt die Bayesianische Optimierung das Experiment mit der besten Leistungsmetrik und den jeweiligen Hyperparameterwerten zurück.
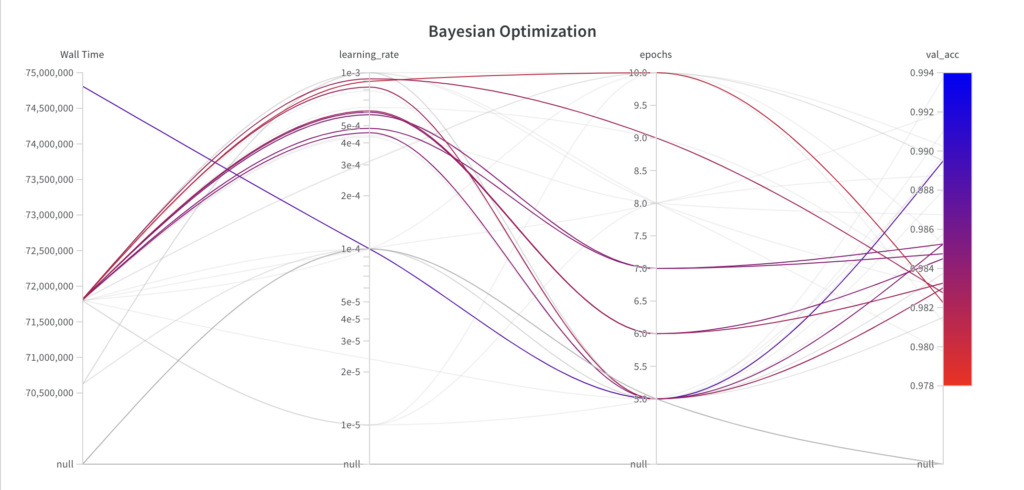
Unten sehen Sie, zu welchem Zeitpunkt der Hyperparameter-Optimierungsalgorithmus welche Parameter gewählt hat und welche Leistung sich daraus ergibt. Sie können folgende Beobachtungen machen:
-
Während der Bayes’sche Optimierungsalgorithmus für die Hyperparameter- Epochen Werte aus dem gesamten Suchraum abtastet , erkundet er in den ersten paar Experimenten nicht den gesamten Suchraum für den Hyperparameter „learning_rate“ .
-
Da es sich bei dem Bayes’schen Optimierungsalgorithmus um einen fundierten Suchalgorithmus handelt, verbessert sich die Leistung im Laufe der Durchläufe.
-
Der beste val_acc -Score beträgt 0,9852 und ist damit schlechter als der beste val_acc -Score, der mit der Rastersuche (0,9902) und der Zufallssuche (0,9868) erreicht wurde. Der Hauptgrund dafür ist vermutlich die Tatsache, dass die Lernrate einen großen Einfluss auf die Leistung des Modells hat, was der Algorithmus in diesem Beispiel nicht richtig abtasten konnte. Sie können jedoch sehen, dass der Algorithmus bereits begonnen hat, die Lernrate zu verringern, um bessere Ergebnisse zu erzielen. Bei mehr Durchläufen könnte der Bayes-Optimierungsalgorithmus möglicherweise zu Hyperparametern führen, die eine bessere Leistung ergeben.
Vorteile
-
Geeignet für Modelle mit vielen Hyperparametern
-
Informierte Suche: Nutzt das Wissen aus früheren Experimenten und kann so schneller zu guten Hyperparameterwerten konvergieren
Nachteile
-
Schwierig umzusetzen
-
Kann nicht parallelisiert werden , da der nächste Satz auszuwertender Hyperparameter von den Ergebnissen des vorherigen Experiments abhängt.