

자동화된 하이퍼파라미터 최적화를 위한 방법
자동화된 하이퍼파라미터 최적화에 사용되는 세 가지 주요 알고리즘은 다음과 같습니다.
-
그리드 검색
세 알고리즘의 주요 차이점은 다음에 테스트할 하이퍼파라미터 값 집합을 선택하는 방법입니다. 하지만 검색 공간을 정의하는 방법(고정 값 대 값 범위)과 실행 횟수를 지정하는 방법(암시적 대 명시적)도 다릅니다.
이 섹션에서는 이러한 차이점과 각각의 장단점을 살펴보겠습니다.
다음에서 하이퍼파라미터 에포크 와 학습률을 최적화하기 위해 W&B 스윕을 사용할 것입니다 . 자세한 내용은 관련 Kaggle Notebook 과 W&B 프로젝트를 확인할 수 있습니다 .
그리드 검색
그리드 검색은 지정된 그리드(카테시안 곱)에서 모든 가능한 하이퍼파라미터 조합을 평가하는 하이퍼파라미터 튜닝 기술입니다. 하이퍼파라미터가 적은 ML 모델에만 권장되는 무차별 대입 접근 방식입니다.
입력
-
최적화하려는 하이퍼파라미터 세트
-
각 하이퍼파라미터에 대한 특정 값 또는 이산화된 검색 공간
-
최적화를 위한 성능 측정 항목
-
(암묵적 실행 횟수: 검색 공간이 고정된 값 집합이므로 실행할 실험 횟수를 지정할 필요가 없습니다)
(무작위 검색과 베이지안 최적화의 차이점은 위에 굵은 글씨로 표시되어 있습니다.)
Python에서 그리드 검색을 구현하는 인기 있는 방법은 scikit learn 라이브러리 의 GridSearchCV를 사용하는 것입니다 . 또는 아래에 표시된 대로 W&B로 하이퍼파라미터 튜닝을 위한 그리드 검색을 설정할 수 있습니다.

단계
1단계: 그리드 검색 알고리즘은 지정된 하이퍼파라미터 값의 모든 가능한 하이퍼파라미터 조합의 그리드(데카르트 곱)를 생성하여 평가할 하이퍼파라미터 값 집합을 선택합니다. 그런 다음 그리드를 반복합니다. 이 접근 방식은 철저한 검색 또는 무차별 대입 접근 방식입니다.
아래에서 우리의 예시에 따른 그리드를 볼 수 있습니다.
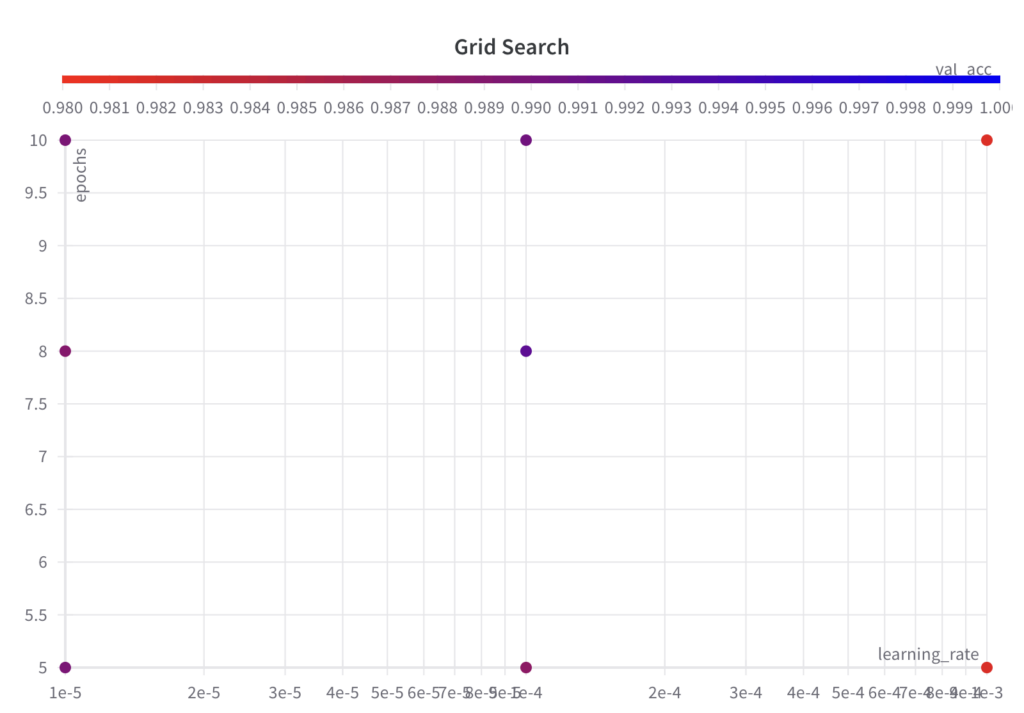
2단계: 선택한 하이퍼파라미터 집합과 해당 값에 대해 ML 실험을 실행하고 성능 지표를 평가하고 기록합니다.
3단계: 지정된 시도 횟수만큼 반복하거나 모델 성능에 만족할 때까지 반복합니다.
산출
모든 자동화된 하이퍼파라미터 최적화 알고리즘과 마찬가지로, 그리드 검색은 가장 좋은 성능 지표와 해당 하이퍼파라미터 값을 포함하는 실험을 반환합니다.
아래에서 하이퍼파라미터 최적화 알고리즘이 어떤 매개변수를 선택했는지와 그 결과 성능을 확인할 수 있습니다. 다음과 같은 관찰을 할 수 있습니다.
-
그리드 검색 알고리즘은 지정된 대로 하이퍼파라미터 집합의 그리드를 반복합니다.
-
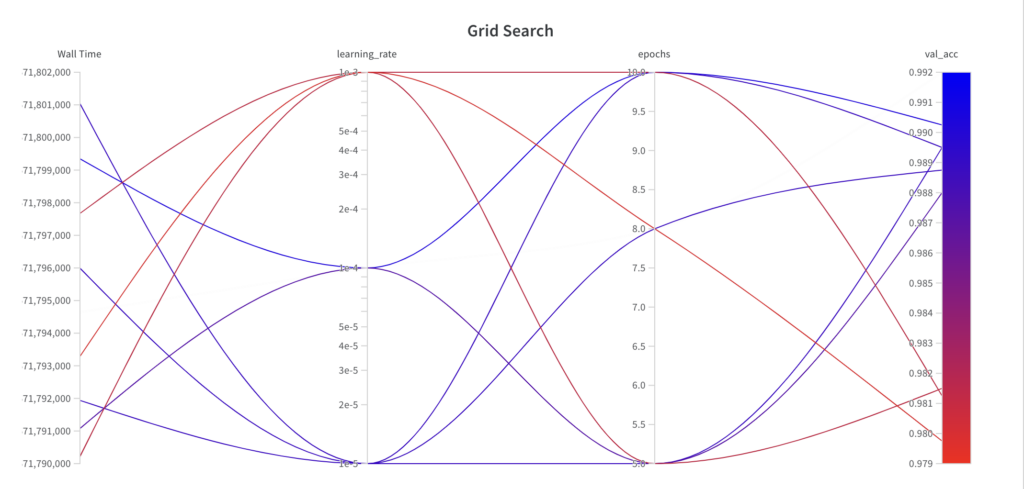
그리드 탐색은 정보를 기반으로 하지 않는 탐색 알고리즘이기 때문에, 결과적인 성능은 실행에 따른 추세를 보여주지 않습니다.
-
가장 좋은 val_acc 점수는 0.9902입니다.
장점
-
구현이 간단합니다
-
병렬화 가능: 하이퍼파라미터 세트를 독립적으로 평가할 수 있기 때문입니다.
단점
-
하이퍼 매개변수가 많은 모델에는 적합하지 않습니다. 이는 주로 하이퍼 매개변수 수에 따라 계산 비용이 기하급수적으로 증가하기 때문입니다.
-
이전 실험의 지식이 활용되지 않아 정보를 얻지 못한 검색 . 좋은 결과를 얻으려면 미세 조정된 검색 공간으로 그리드 검색 알고리즘을 여러 번 실행해야 할 수도 있습니다.
조정할 하이퍼파라미터가 3개 이하인 경우가 아니면 일반적으로 그리드 탐색은 피하는 것이 좋습니다.
무작위 검색
임의 탐색은 지정된 검색 공간에서 값을 무작위로 샘플링하는 하이퍼파라미터 튜닝 기술입니다. 이 기술은 하이퍼파라미터가 많고 그 중 소수만이 모델 성능에 영향을 미치는 ML 모델의 경우 그리드 탐색보다 효과적입니다[1].
입력
-
최적화하려는 하이퍼파라미터 세트
-
각 하이퍼파라미터를 값 범위로 하는 연속 검색 공간
-
최적화를 위한 성능 측정 항목
-
명시적 실행 횟수: 검색 공간이 연속적이므로 검색을 수동으로 중지하거나 최대 실행 횟수를 정의해야 합니다.
그리드 검색과의 차이점은 위에 굵은 글씨로 강조되어 있습니다.
파이썬에서 랜덤 검색을 구현하는 인기 있는 방법은 scikit learn 라이브러리 의 RandomizedSearchCV를 사용하는 것입니다 . 또는 아래에 표시된 대로 W&B로 하이퍼파라미터 튜닝을 위한 랜덤 검색을 설정할 수 있습니다.

단계
1단계: 무작위 검색 알고리즘은 지정된 반복 횟수만큼 각 반복에 대해 지정된 검색 공간에서 무작위로 하이퍼 매개변수 값을 샘플링하여 평가할 하이퍼 매개변수 집합을 선택합니다.
아래에서 샘플링된 하이퍼파라미터 값 세트가 그리드 검색 알고리즘과 같이 그리드를 따르지 않는다는 것을 확인할 수 있습니다.
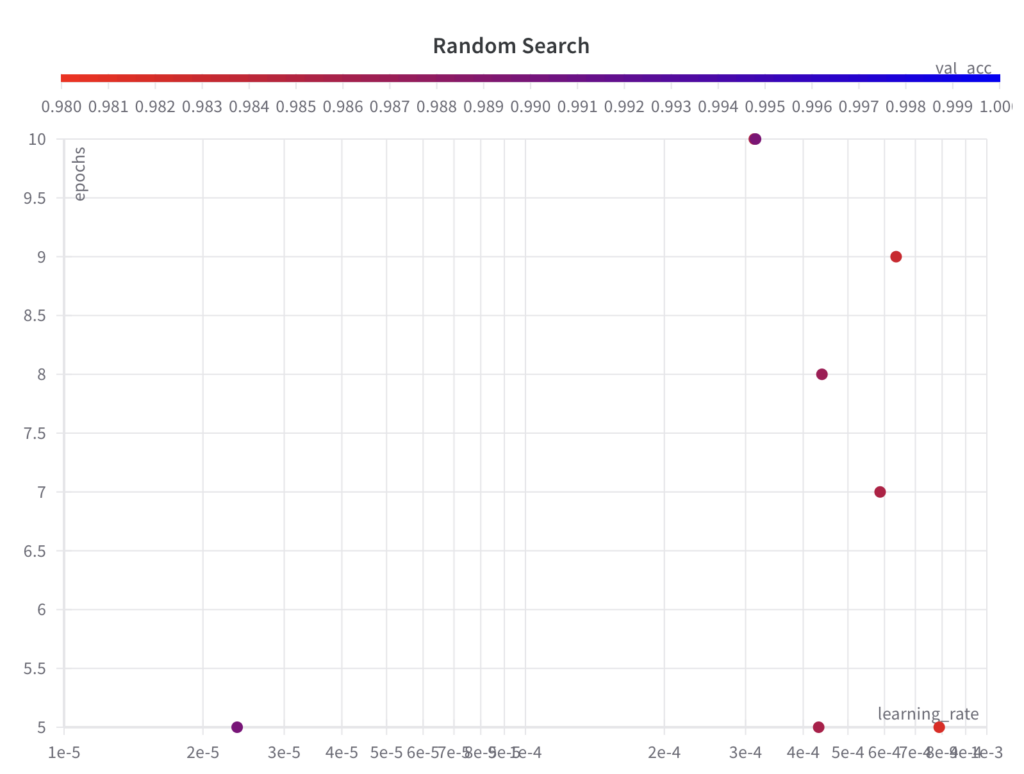
2단계: 선택한 하이퍼파라미터 집합과 해당 값에 대해 ML 실험을 실행하고 성능 지표를 평가하고 기록합니다.
3단계: 지정된 횟수만큼 반복합니다.
산출
모든 자동화된 하이퍼파라미터 최적화 알고리즘과 마찬가지로, 랜덤 검색은 가장 좋은 성능 지표와 해당 하이퍼파라미터 값을 갖는 실험을 반환합니다.
아래에서 하이퍼파라미터 최적화 알고리즘이 어떤 매개변수를 선택했는지와 그 결과 성능을 확인할 수 있습니다. 다음과 같은 관찰을 할 수 있습니다.
-
무작위 검색은 하이퍼파라미터 에포크 에 대한 전체 검색 공간에서 값을 샘플링하는 반면 , 처음 몇 번의 실험에서는 하이퍼파라미터 학습률 에 대한 전체 검색 공간을 탐색하지 않습니다 .
-
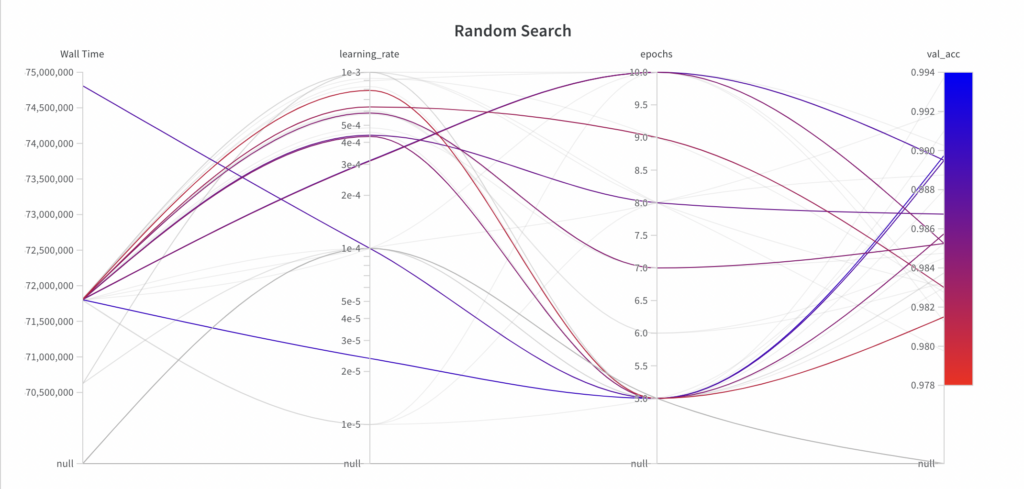
무작위 검색은 정보를 기반으로 하지 않는 검색 알고리즘이기 때문에, 결과적인 성능은 실행에 따른 추세를 보여주지 않습니다.
-
가장 좋은 val_acc 점수는 0.9868로, 그리드 탐색으로 달성한 가장 좋은 val_acc 점수(0.9902) 보다 나쁩니다 . 그 주된 이유는 learning_rate가 모델의 성능에 큰 영향을 미치고, 이 예에서 알고리즘이 제대로 샘플링하지 못했기 때문이라고 추정됩니다.
장점
-
구현이 간단합니다
-
병렬화 가능 : 하이퍼파라미터 세트를 독립적으로 평가할 수 있기 때문입니다.
-
많은 하이퍼 매개변수를 갖는 모델에 적합: 하이퍼 매개변수가 많고 모델 성능에 영향을 미치는 하이퍼 매개변수 수가 적은 모델의 경우 무작위 검색이 그리드 검색보다 효과적임이 보장됩니다. [1]
단점
-
이전 실험의 지식이 활용되지 않아 정보를 얻지 못한 검색 . 좋은 결과를 얻으려면 미세 조정된 검색 공간으로 임의 검색 알고리즘을 여러 번 실행해야 할 수도 있습니다.
베이지안 최적화
베이지안 최적화는 대리 함수를 사용하여 평가할 다음 하이퍼파라미터 세트를 결정하는 하이퍼파라미터 튜닝 기술입니다. 그리드 탐색 및 랜덤 탐색과 달리 베이지안 최적화는 정보에 입각한 탐색 방법입니다.
입력
-
최적화하려는 하이퍼파라미터 세트
-
각 하이퍼파라미터를 값 범위로 하는 연속 검색 공간
-
최적화를 위한 성능 측정 항목
-
명시적 실행 횟수: 검색 공간이 연속적이므로 검색을 수동으로 중지하거나 최대 실행 횟수를 정의해야 합니다.
그리드 검색의 차이점은 위에 굵은 글씨로 강조되어 있습니다.
파이썬에서 베이지안 최적화를 구현하는 인기 있는 방법은 bayes_opt 라이브러리 의 BayesianOptimization을 사용하는 것입니다 . 또는 아래에 표시된 대로 W&B로 하이퍼파라미터 튜닝을 위한 베이지안 최적화를 설정할 수 있습니다.

단계
- 1단계: 목적 함수의 확률 모델을 구축합니다. 이 확률 모델을 대리 함수라고 합니다. 대리 함수는 가우시안 프로세스[2]에서 나오며 다양한 하이퍼 매개변수 세트에 대한 ML 모델의 성능을 추정합니다.
- 2단계: 다음 하이퍼파라미터 집합은 지정된 검색 공간에서 서로게이트 함수가 최상의 성능을 달성할 것으로 예상하는 것에 따라 선택됩니다.
아래에서 볼 수 있듯이 샘플링된 하이퍼파라미터 값 세트는 그리드 탐색 알고리즘과 같이 그리드를 따르지 않습니다.
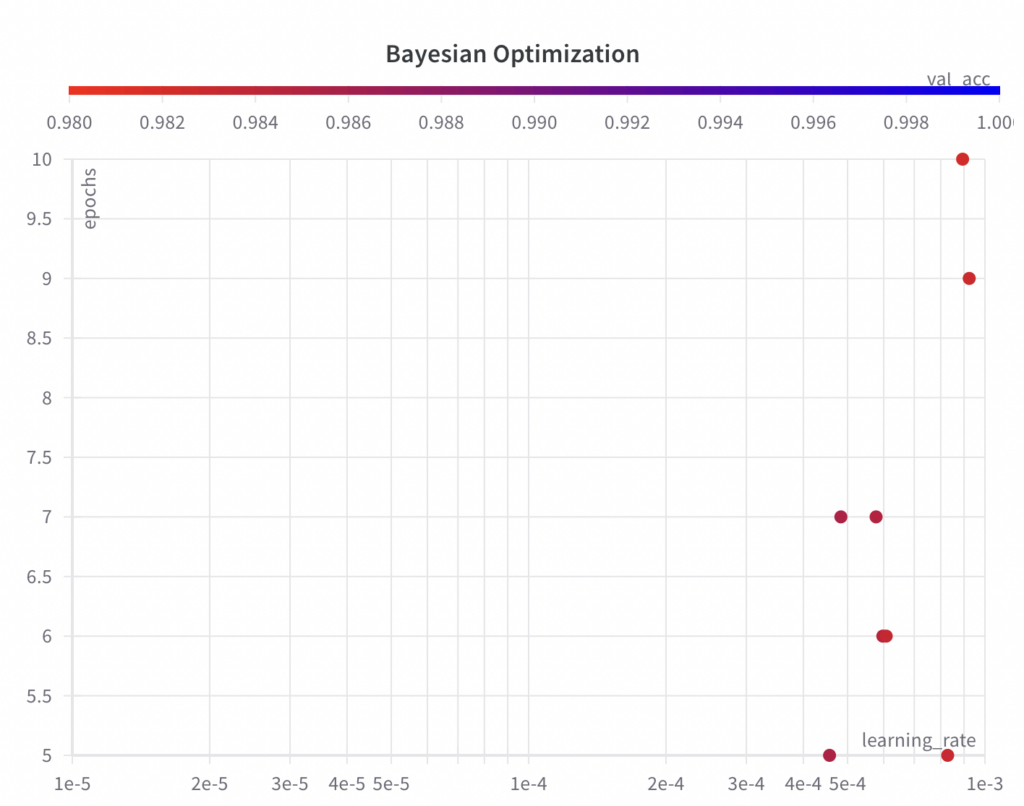
- 3단계: 선택한 하이퍼파라미터 집합과 해당 값에 대해 ML 실험을 실행하고 성능 지표를 평가하고 기록합니다.
- 4단계: 실험 후, 대리 함수는 마지막 실험 결과로 업데이트됩니다.
- 5단계: 지정된 횟수만큼 2~4단계를 반복합니다.
산출
모든 자동화된 하이퍼파라미터 최적화 알고리즘과 마찬가지로 베이지안 최적화는 가장 좋은 성능 지표와 해당 하이퍼파라미터 값을 갖는 실험을 반환합니다.
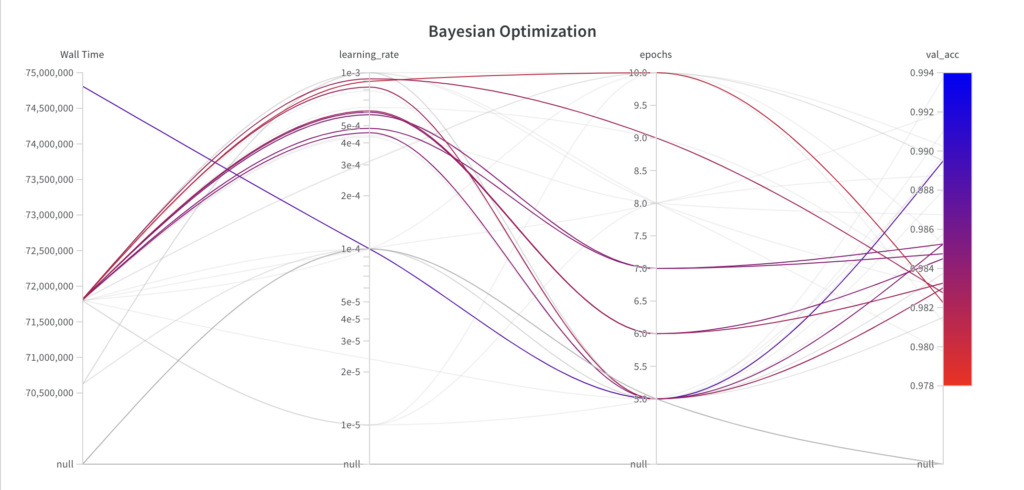
아래에서 하이퍼파라미터 최적화 알고리즘이 어떤 매개변수를 선택했는지와 그 결과 성능을 확인할 수 있습니다. 다음과 같은 관찰을 할 수 있습니다.
-
베이지안 최적화 알고리즘은 하이퍼파라미터 에포크 에 대한 전체 검색 공간에서 값을 샘플링하지만, 처음 몇 번의 실험에서는 하이퍼파라미터 학습률 에 대한 전체 검색 공간을 탐색하지 않습니다 .
-
베이지안 최적화 알고리즘은 정보를 기반으로 하는 검색 알고리즘이므로 실행을 거듭할수록 성능이 향상됩니다.
-
최상의 val_acc 점수는 0.9852로, 그리드 탐색(0.9902)과 랜덤 탐색(0.9868)으로 달성한 최상의 val_acc 점수보다 나쁩니다. 그 주된 이유는 학습 속도가 모델의 성능에 큰 영향을 미치고, 이 예에서 알고리즘이 제대로 샘플링하지 못했기 때문이라고 추정됩니다. 하지만 알고리즘이 더 나은 결과를 얻기 위해 학습 속도를 이미 낮추기 시작한 것을 알 수 있습니다 . 더 많은 실행이 주어지면 베이지안 최적화 알고리즘은 잠재적으로 더 나은 성능을 가져오는 하이퍼파라미터로 이어질 수 있습니다.
장점
-
많은 하이퍼파라미터가 있는 모델에 적합
-
정보 기반 검색: 이전 실험에서 얻은 지식을 활용하여 더 빠르게 좋은 하이퍼 매개변수 값으로 수렴할 수 있습니다.
단점
-
구현하기 어려움
-
다음에 평가할 하이퍼파라미터 세트가 이전 실험 결과에 따라 달라지기 때문에 병렬화할 수 없습니다.