
「実験の追跡により、速度が 10 倍になり、扱いやすさと追跡可能性を備えて、はるかに速く結果を相互に共有できるようになりました。」
エヴァン・クッシング
機械学習エンジニア
モビリティ市場は絶えず進化しており、キックスクーター、次世代車両、電動自転車、モビリティ・アズ・ア・サービス(MaaS)システムなど、新しい道路利用者や車両が定期的に導入され、ドライバーと車はそれに応じて適応する必要があります。
ML エンジニアの Evan Cushing 氏によると、その絶え間ない進化こそが、トヨタ自動車のモビリティ テクノロジー子会社で、トヨタ グループ内のソフトウェア変革の推進に注力している Woven で彼と彼のチームが取り組んでいるプロジェクトを非常に魅力的なものにしているのだという。
「私たちは、他の分野や企業では見られないような規模で、本当に興味深く、挑戦的な問題に取り組んでいます」と Cushing 氏は言います。「自動運転が Weights & Biases のようなツールを必要とする興味深い ML 問題である理由は、それが高次元の問題だからです。これらの課題の 1 つは、継続的な学習の ML システムが必要であることです。」
チームの使命は、安全でインテリジェント、人間中心の自動運転とモビリティ ソリューションを提供することです。検出漏れは乗客とその周囲のコミュニティにとって大きな安全上のリスクを意味し、会社と Evan の ML チームに最先端のモデルとソリューションを提供するという大きなプレッシャーがかかります。
「Autonomy 1.0」ワークフローの課題
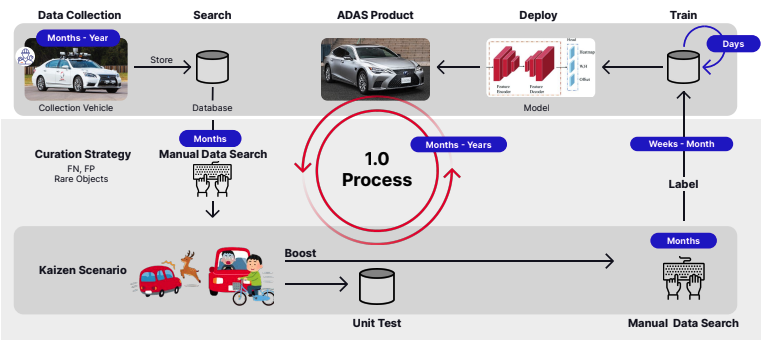 Cushing 氏と彼のチームは、データ収集からトレーニング、展開に至るまで、自動運転のための「1.0」プロセスと従来の ML ワークフローにいくつかの問題点があることを認識しました。これには次のものが含まれます。
Cushing 氏と彼のチームは、データ収集からトレーニング、展開に至るまで、自動運転のための「1.0」プロセスと従来の ML ワークフローにいくつかの問題点があることを認識しました。これには次のものが含まれます。
- データ収集方法は、実際の運転シナリオの豊富で多様なデータ分布を完全には捉えずに、固定ルートを走行するテスト車両を使用するもので、拡張できませんでした。
- ベンチマークに使用されるテスト セットの一部となるように、テスト車両からのデータを手動でキュレートする必要がありました。チーム メンバーはビデオをレビューして、道路上の動物など、ML モデルや AI システムにとって難しい可能性のあるトレーニングや改善シナリオに適したシーンを見つけてキュレートしていました。これもスケーラブルではありませんでした。
- サードパーティのデータ注釈サービスと連携した、遅くて時間のかかるデータラベル付けプロセス。最大 1 か月かかる場合があります。
カイゼンの原則を用いた10倍の改善
カイゼンとは、「継続的な改善」、より正確には「より良い方向への変化」を意味する日本語です。その根底にあるのは、プロセスの無駄や非効率性を排除しながら、時間をかけて小さな漸進的な改善を継続的に行うことで大きな進歩を達成するという哲学を強調することです。Cushing は、この思考プロセスが課題に取り組むための鍵であると捉え、ワークフロー全体にカイゼンを実装する領域を探しました。
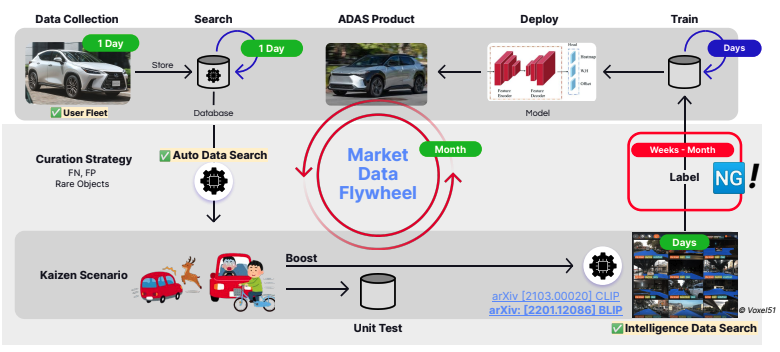
最大の改善点は、データ収集にテスト車両を使用するのではなく、データ収集センサーを搭載した大規模な顧客車両群を活用することで、大幅に大量のデータをより短時間で収集できるようになったことです。これらのセンサーは、たとえば突然の重力加速度の大幅な増加を感知した場合など、カイゼン シナリオを見つけるために自動トリガーも使用しました。これは潜在的に危険な状況である可能性があり、モデルをトレーニングするための貴重なシーンです。
データ キュレーション ワークフロー中の自動ラベル付けとデータセット クエリによって、時間の節約も大幅に改善され、20 か月からわずか 2 か月に短縮されました。チームは機械学習を使用してデータ アノテーションを自動化し、人間が手動でシーンをキュレーションしてトレーニングにアノテーションする代わりに、データにラベルを自動的に割り当てました。チームはデータセットをクエリして、「道路を横断する鹿」や「自転車に乗る子供」など、カイゼン シナリオの可能性があるシーンを検索し、この特定のシナリオのすべてのサンプルを取得できるようになりました。
ワークフロー全体を通じてこれらすべての取り組みをサポートしたのは、Weights & Biases をレコードの中央システムとして使用し、PyTorch をコア フレームワークとして使用し、Hydra を構成の管理に使用し、オンプレミス (DGX) とクラウド (AWS EC2 および SageMaker) の両方のインフラストラクチャを備えたクラス最高の ML フレームワークでした。
重みとバイアスの影響
特に Weights & Biases は、Woven by Toyota にとって、組織や製品アプリケーション全体にわたる ML プロジェクトの開発、コミュニケーション、コラボレーションに不可欠なツールとなっています。
「実験の追跡により、速度が 10 倍になり、追跡可能性と追跡可能性を備えながら、結果をより迅速に共有できるようになりました」と Cushing 氏は述べています。「Sweeps は、以前は面倒だったプロセスを自動化するのに役立ち、Reports はトヨタでの優れた ML の基準を高めるのに役立ちました。」
チームは、重みとバイアスを使用する独自の方法も考案しました。Cushing 氏が「非常に楽しい Kaizen のプロのヒント」と表現した、テーブルを事実上のモデル リーダーボードとして使用する方法を考案しました。
チームはチームや機能間でモデルを共有し、同じデータセット バージョンでトレーニングされたモデル実行を集計します。次に、テーブルを使用して評価指標でモデルを並べ替え、誰が何を実行しているか、どのモデル バージョンがリードしているか、チーム内で誰がトップに立っているかを確認します。
「これにより、プロジェクト開発においてチームの足並みが揃います」と Cushing 氏は言います。「リーダーボードにより、優れた成果を上げているデータ、テクニック、チームを部門横断的に把握できます。」
チームは、Weights & Biases の使用と、取り組んでいる Autonomy 2.0 ワークフロー全体の両方において、現状に満足していません。Cushing は、特に Launch (コンピューティングへのシームレスな接続により、さらに大規模なトレーニングと推論ジョブを実行) と Model Registry (すべてのモデル管理と展開を一元化して整理) を W&B プラットフォームにさらに統合することを計画しています。
一方、Autonomy 2.0 は、大規模な動作データセット、検証のためのより優れたオフライン シミュレーション、より手頃なハードウェア コストなどにより、さらに改善を続け、規模拡大を推進します。自動運転の近未来は刺激的なものであり、その先頭に立つのは Woven by Toyota の Cushing 氏と彼のチームです。