時系列予測と時系列分析の定義
このセクションでは、時系列、時系列分析、時系列予測という 3 つの重要な用語を定義します。
時系列とは何ですか?
時系列とは、時間に依存するデータ ポイントのシーケンスです。つまり、各データ ポイントにはタイムスタンプが割り当てられます。理想的には、これらのデータ ポイントは一定の間隔 (たとえば、毎日) で時系列 (たとえば、月曜日、火曜日、水曜日など) で測定されます。
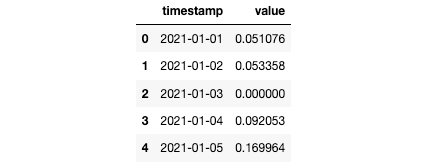
時系列は通常、売上データなどの数値ですが、イベント データなどのカテゴリ値になることもあります。時系列データは通常、タイムスタンプ用の列と時系列値用の列が少なくとも 1 つある表形式 (CSV ファイルなど) で提供されます。
時系列分析とは何ですか?
時系列分析は、変数と外れ値の関係を分析するため、データサイエンスワークフローにおける探索的データ分析(EDA)に似ています[3、9]。さらに、長期的な傾向や短期的な繰り返しパターンを見つけたいと考えています[3、9]。
標準的なEDA技術と同様に、平均や標準偏差などの統計特性のプロットと計算も時系列解析に不可欠です[9]。ただし、時間という追加された次元を探索するには追加の方法を使用する必要があります(時系列解析の基礎を参照)。
時系列分析は、独立した概念である一方、時系列とそのパターンについて得られる洞察がどのモデルを使用するかを決定するのに役立つため、時系列予測ワークフロー中のEDAステップになることもあります[9]。
時系列予測とは何ですか?
時系列予測では、一連の観測が将来どのように続くかを予測します。この目的のために、まず時系列分析と同様に履歴データを分析します。次に、履歴データにモデルを当てはめて予測を行います。
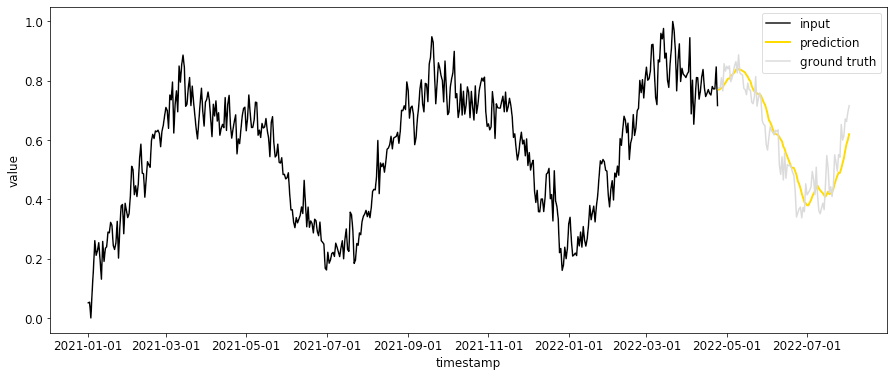
時系列予測にはさまざまな問題設定があり、次のような点で異なります。
-
予測する観測時系列の数(単変量 vs. 多変量)
-
予測期間(短期 vs. 長期)
時系列分析の基礎
このセクションでは、時系列分析の重要な概念のいくつか(時系列の構成要素と定常性)を紹介します。
時系列の構成要素
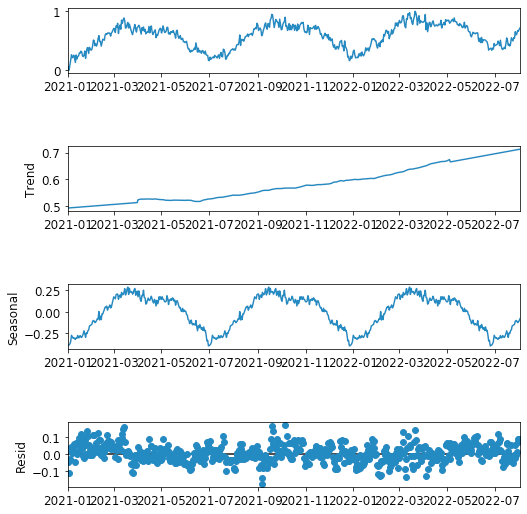
予測方法を選択する際には、まず時系列データのパターンを特定し、そのパターンを適切に捉えられるモデルを選択する必要があります[3]。観測された時系列は、次の5つの要素に分解できます。
-
レベル:平均値。
-
トレンド:長期的な増加または減少の傾向。
-
季節性: 毎週、毎月、毎年など、固定期間における短期的な繰り返しパターン。
-
サイクル: 短期間の繰り返しパターン (固定期間ではない)。
-
ノイズ: 不規則またはランダムな短期的な変動。
時系列データでは、季節的なパターンと周期的なパターンを区別することが難しい場合があります。繰り返し発生するパターンの頻度が暦に対して一定である場合、そのパターンは季節的なものです。そうでない場合は、周期的なものです [3]。
statsmodels [10]ライブラリのseasonal_decompose()関数を使用することができます。これは単純な分解方法で、時系列をトレンド、季節性、ノイズ(残差)の3つの要素のみに分解します[10]。

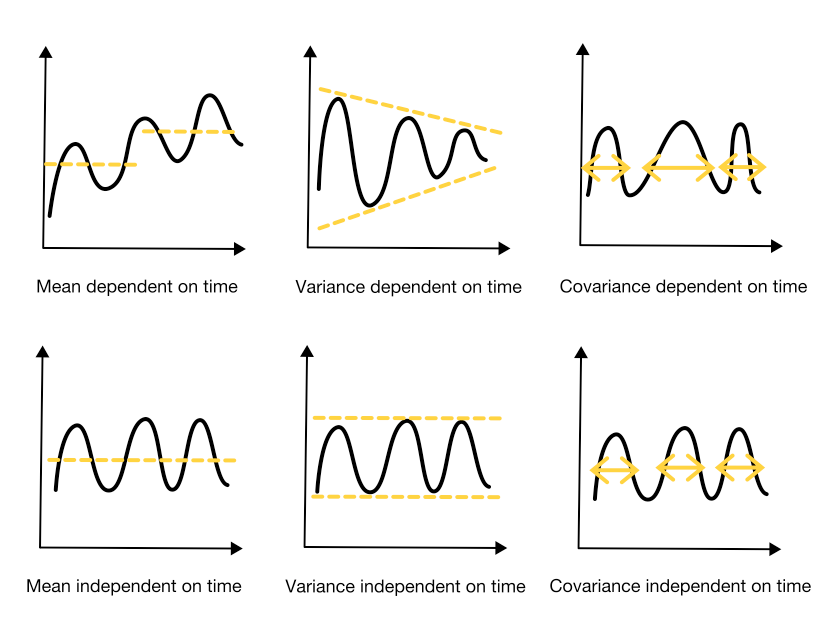
定常性とは何ですか? 時系列分析にとってなぜ重要ですか?
定常性とは、時系列がどのように変化しているかが将来も同じままであるという概念を表します [3]。数学的には、時系列の統計的特性(平均、分散、共分散)が時間に依存しない場合、時系列は定常です [7]。
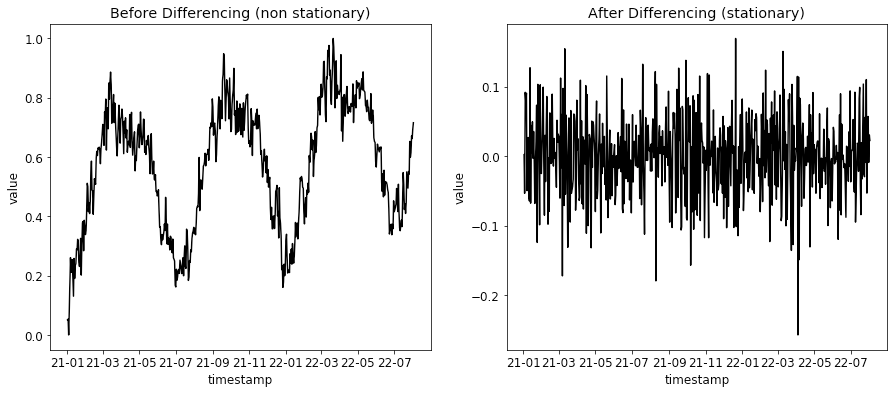
未来が過去と似ている場合、予測は容易になります [3]。したがって、定常時系列は統計的特性が同じままであるため、非定常時系列よりもモデル化が容易です。そのため、多くの時系列予測モデルは定常性を前提としています。
時系列が非定常である場合は、差分をとるなどして定常化を試みることができます。
時系列予測の基礎
このセクションでは、一般的な時系列予測モデルと、それらをトレーニングおよび検証する方法について説明します。
人気の時系列予測モデル
時系列予測には、さまざまなモデルが利用できます。予測手法は、最新の観測値を予測値として使用するような単純なものから、非常に複雑なMLモデル[3]まで多岐にわたります。
単純なアプローチ:単純な予測では、予測値は最新の観測値に過ぎません。この基本的な方法は、より高度なモデルのパフォーマンスを評価するためのベンチマークとしてよく使用されます。
したがって、重みとバイアスを使用して実験を追跡する際の最初のステップとして、実験をテストするための単純なアプローチでベースラインを作成することをお勧めします。💡
回帰ベースの時系列予測:回帰ベースの時系列予測法では、時系列が他の時系列と線形関係にあると仮定します [3]。この線形関係の仮定により、季節性ではなくトレンドのモデルが生成されます。
指数平滑法: 指数平滑法は1950年代後半に提案され、古典的な予測法である[1、2、13]。この方法が人気なのは、比較的少ないメモリスペースで信頼性の高い(短期)予測を迅速に生成できるからである[3]。
この予測方法は、過去の観測値の加重平均を使用します。過去のすべての観測値の平均を取ることで時系列のノイズが低減し(平滑化)、観測値が古くなるにつれて重みが指数関数的に減少します[3]。
自己回帰和分移動平均(ARIMA):ARIMAは、自己相関に基づいて時系列をモデル化する予測手法の一種です[3, 9]。モデルは、以下の構成要素の組み合わせです。
-
自己回帰 (AR):過去の値の線形結合に基づいて予測を行います。
-
移動平均 (MA):過去の予測誤差の線形結合に基づいて予測を行います。
Prophet: Prophetは、FacebookのCore Data Scienceチーム[12]によって開発された、すぐに使えるように設計されたオープンソースの時系列フレームワークです。基本的な考え方は、時系列をトレンド、季節要素(例:週ごとまたは年ごと)、決定論的不規則要素(例:休日)、ノイズの4つの要素に分解できるという仮定に基づいています。
機械学習: 近年、時系列予測において機械学習モデルが人気を集めています。2020年のマクリダキスコンペティション(M5コンペティション)[8]は、さまざまな時系列予測手法を評価・比較する一連のコンペティションであり、ニューラルネットワークや勾配ブースティングフレームワーク[4、5、6]によって最高の予測結果が得られました。
時系列予測モデルのトレーニングと検証
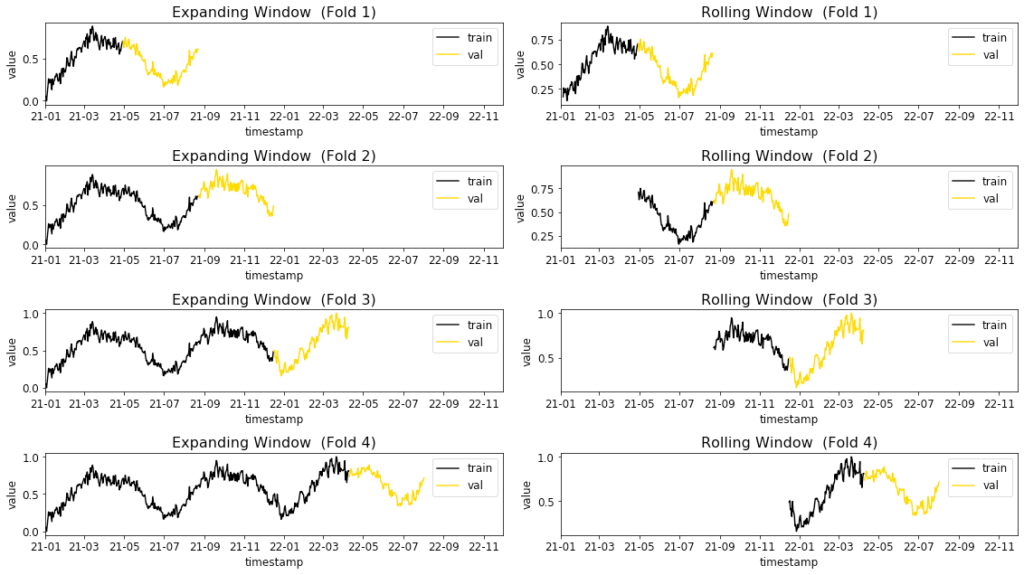
時系列予測の場合、時間的な側面から、通常の機械学習モデルと同じクロス検証戦略を適用することはできません。したがって、予測モデルのトレーニングと検証には、トレーニング データが検証データよりも古い必要があります。

時間の側面を考慮することに加えて、トレーニング用の入力データの長さを固定するか (スライディング ウィンドウ)、入力データの長さを拡張するか (拡張ウィンドウ) を決定できます。