

LLMOps が台頭する理由
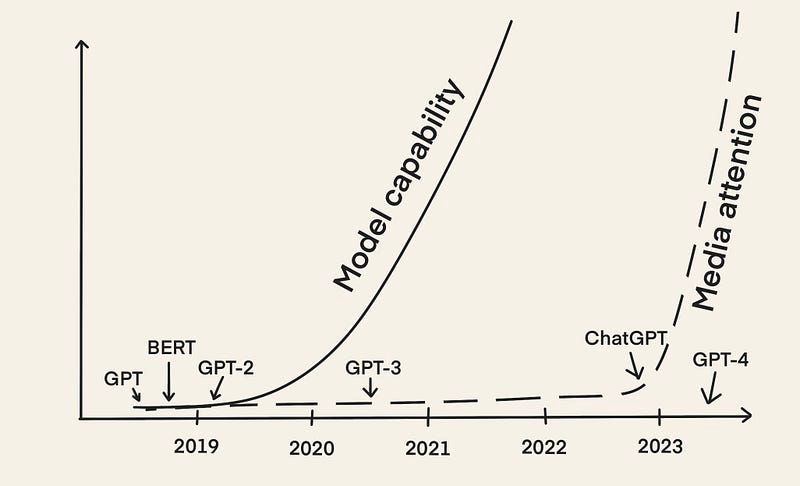
BERT や GPT-2 のような初期の LLM は 2018 年から存在していました。しかし、ほぼ 5 年経った今、LLMOps というアイデアが急速に広まっています。主な理由は、2022 年 12 月に ChatGPT がリリースされ、LLM がメディアの注目を集めたことです。
それ以来、LLM の力を活用したさまざまなアプリケーションが登場しました。たとえば、次のようなものがあります。
多くの人が LLM を利用したアプリケーションを開発し、本番環境に導入しており、その経験を共有しています。
「LLM で何かクールなものを作るのは簡単ですが、実用に耐えるものを作るのは非常に困難です。」 – Chip Huyen [2]
実稼働対応の LLM 搭載アプリケーションを構築するには、従来の ML モデルを使用して AI 製品を構築する場合とは異なる独自の課題が伴うことが明らかになっています。これらの課題に対処するには、LLM アプリケーションのライフサイクルを管理するための新しいツールとベスト プラクティスを開発する必要があります。そのため、「LLMOps」という用語の使用が増えています。
LLMOps にはどのようなステップが含まれますか?
LLMOps に含まれる手順は、ある意味では MLOps と似ています。ただし、基礎モデルの出現により、LLM を利用したアプリケーションを構築する手順は異なります。LLM を最初からトレーニングするのではなく、事前にトレーニングされた LLM を下流のタスクに適応させることに重点が置かれています。
すでに1年以上前に、Andrej Karpathy [3]は、AI製品の構築プロセスが将来どのように変化するかを次のように説明しました。
しかし、最も重要な傾向は、ニューラルネットワークをゼロからトレーニングするという全体的な設定が、特にGPTのような基礎モデルの出現により、微調整によって急速に時代遅れになりつつあることです。これらの基礎モデルは、十分なコンピューティングリソースを持つ少数の機関によってのみトレーニングされており、ほとんどのアプリケーションは、ネットワークの一部に対する軽量な微調整、迅速なエンジニアリング、またはデータまたはモデルを蒸留してより小さな専用推論ネットワークにするオプションのステップによって実現されています。[…] – Andrej Karpathy [3]
この引用文を初めて読むと圧倒されるかもしれません。しかし、これはこれまで起こったことすべてを正確に要約しているので、次のサブセクションで段階的に説明していきましょう。
ステップ1: 基礎モデルの選択
基礎モデルは、幅広い下流タスクに使用できる大量のデータで事前トレーニングされたLLMです。基礎モデルをゼロからトレーニングするのは複雑で時間がかかり、非常に高価であるため、必要なトレーニングリソースを持っている機関はごくわずかです[3]。
参考までに言うと、2020年のLambda Labsの調査によると、OpenAIのGPT-3(1,750億のパラメータを持つ)をトレーニングするには、Tesla V100クラウドインスタンスを使用して355年と460万ドルが必要になります。
AI は現在、コミュニティが「Linux の瞬間」と呼んでいる時期を迎えています。現在、開発者は、パフォーマンス、コスト、使いやすさ、柔軟性のトレードオフに基づいて、独自のモデルとオープンソース モデルの 2 種類の基盤モデルから選択する必要があります。
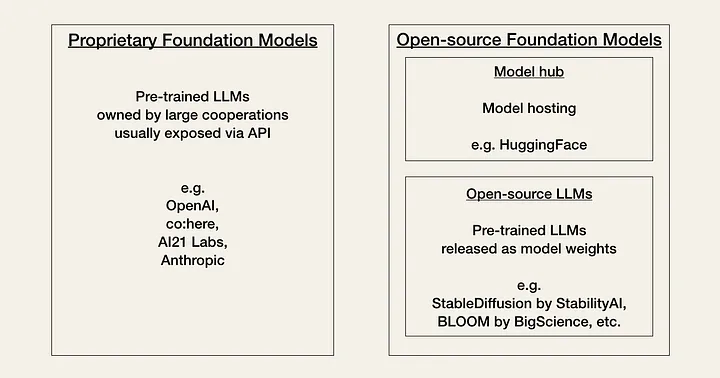
独自モデルは、大規模な専門家チームと大規模な AI 予算を持つ企業が所有するクローズドソースの基礎モデルです。通常、オープンソース モデルよりも大きく、パフォーマンスも優れています。また、既成品であり、一般的に使いやすいです。
独自モデルの主な欠点は、高価な API (アプリケーション プログラミング インターフェイス) です。さらに、クローズド ソースの基盤モデルでは、開発者が適応するための柔軟性が低いか、まったくありません。
独自のモデルプロバイダーの例は次のとおりです。
-
OpenAI (GPT-3、GPT-4)
-
AI21 ラボ(ジュラシック 2)
-
人間的(クロード)
オープンソース モデルは、多くの場合、コミュニティ ハブとしてHuggingFaceで整理され、ホストされています。通常、これらは独自のモデルよりも機能の低い小さなモデルです。ただし、利点としては、独自のモデルよりもコスト効率が高く、開発者に高い柔軟性を提供します。
オープンソース モデルの例は次のとおりです。
-
BigScience のBLOOM
ステップ2: 下流タスクへの適応
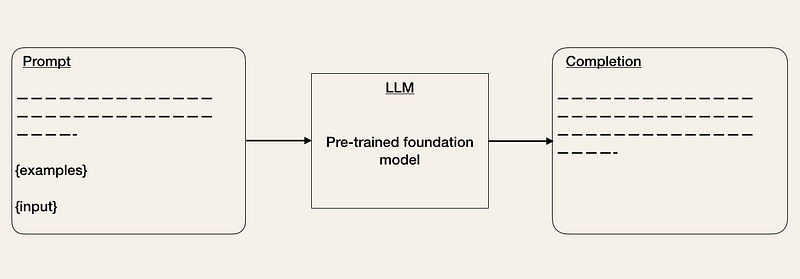
基盤モデルを選択したら、API を通じて LLM にアクセスできます。他の API の操作に慣れている場合、LLM API の操作は最初は少し奇妙に感じるかもしれません。これは、どの入力がどの出力を引き起こすかが事前に必ずしも明確ではないためです。任意のテキスト プロンプトを指定すると、API はテキスト補完を返し、パターンに一致するようにします。
OpenAI API の使用方法の例を次に示します。API 入力をプロンプトとして指定します。例: prompt = “これを標準英語に修正してください:\n\nShe no went to the market.”。
 API は、完了応答 [‘choices’][0][‘text’] = “彼女は市場に行きませんでした。”を含む応答を出力します。
API は、完了応答 [‘choices’][0][‘text’] = “彼女は市場に行きませんでした。”を含む応答を出力します。
主な課題は、LLM は強力であるにもかかわらず万能ではないということであり、したがって、重要な質問は、LLM から必要な出力を得るにはどうすればよいかということです。
LLM の生産に関する調査[4]で回答者が挙げた懸念事項の 1 つは、モデルの精度と幻覚でした。つまり、LLM API からの出力を希望の形式で取得するには、いくつかの反復が必要になる可能性があり、また、必要な特定の知識がない場合、LLM は幻覚を起こす可能性があります。これらの懸念に対処するには、次の方法で基礎モデルを下流のタスクに適応させることができます。
-
プロンプトエンジニアリング[2, 3, 5]は、出力が期待どおりになるように入力を微調整する手法です。プロンプトを改善するには、さまざまなトリックを使用できます(OpenAI Cookbookを参照)。1つの方法は、予想される出力形式の例をいくつか提供することです。これは、ゼロショットまたは少数ショットの学習設定に似ています[5]。LangChainやHoneyHiveなどのツールは、プロンプトテンプレートの管理とバージョン管理を支援するためにすでに登場しています[1]。
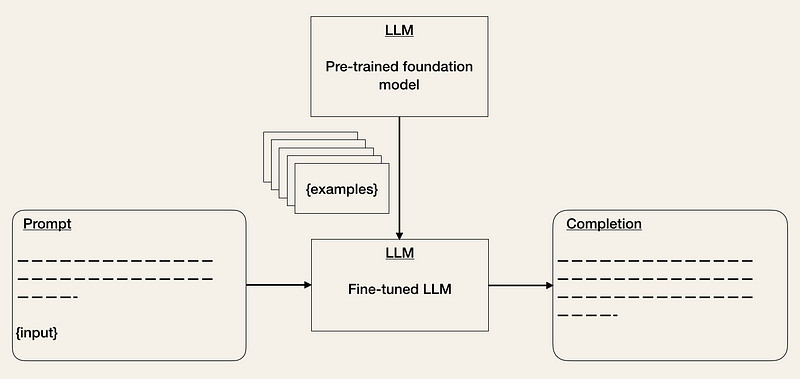
- 事前トレーニング済みモデルの微調整[2, 3, 5] は、ML の既知の手法です。特定のタスクにおけるモデルのパフォーマンスを向上させるのに役立ちます。これによりトレーニングの労力は増加しますが、推論のコストを削減できます。LLM API のコストは、入力および出力シーケンスの長さに依存します。したがって、入力トークンの数を減らすと、プロンプトで例を提供する必要がなくなるため、API コストが削減されます [2]。
-
外部データ:基盤モデルにはコンテキスト情報(特定のドキュメントやメールへのアクセスなど)が欠けていることが多く、すぐに古くなる可能性があります(例:GPT-4は2021年9月以前のデータでトレーニングされました)。LLMは十分な情報がないと幻覚を起こす可能性があるため、関連する外部データにアクセスできるようにする必要があります。LlamaIndex (GPT Index)、LangChain、DUSTなどのツールはすでに存在しており、LLMを他のエージェントや外部データに接続(「連鎖」)するための中心的なインターフェースとして機能します[1]。
ステップ3: 評価
従来のMLOpsでは、MLモデルはホールドアウト検証セット[5]で検証され、モデルのパフォーマンスを示すメトリックが使用されます。しかし、LLMのパフォーマンスをどのように評価するのでしょうか?応答が良いか悪いかをどのように判断するのでしょうか?現在、組織はモデルをA/Bテストしているようです[5]。
LLM の評価を支援するために、HoneyHive や HumanLoop などのツールが登場しました。
💡
ステップ4: 展開と監視
LLMの完成度はリリースごとに大きく変わる可能性があります[2]。例えば、OpenAIはヘイトスピーチなどの不適切なコンテンツ生成を軽減するためにモデルを更新しました。その結果、Twitterで「AI言語モデルとして」というフレーズを検索すると、無数のボットが見つかるようになりました。
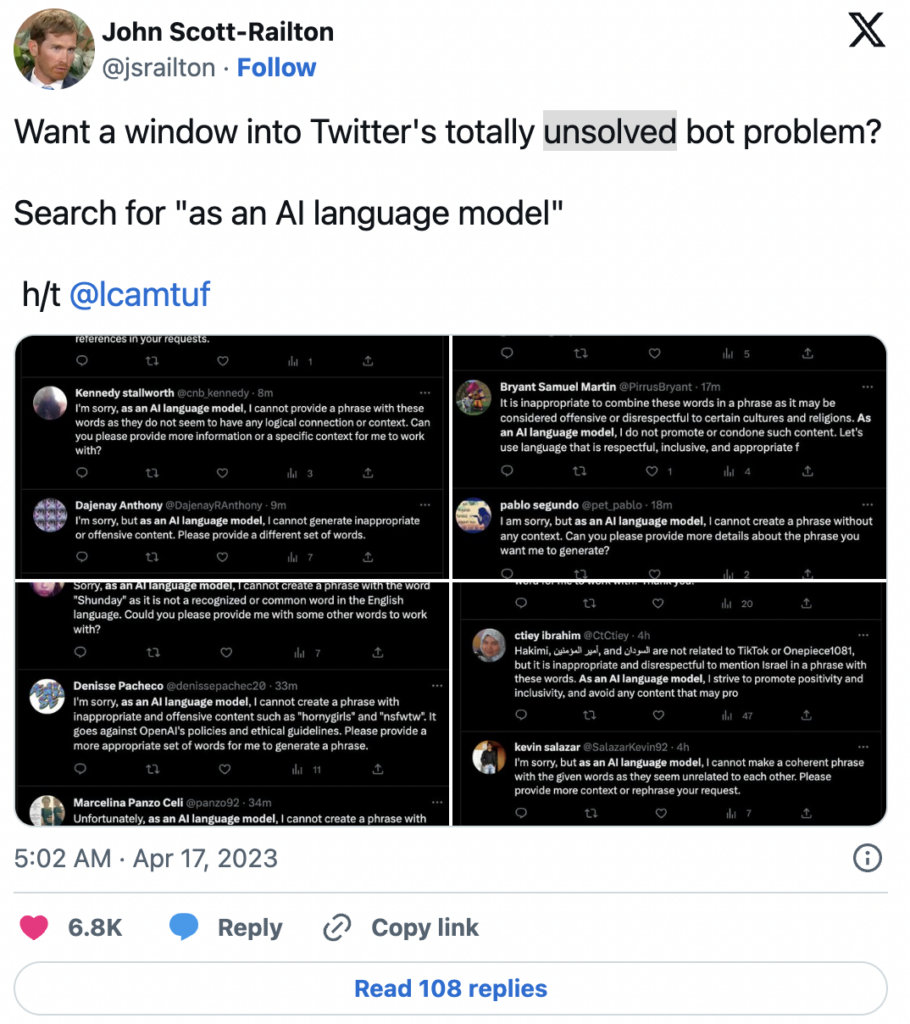 これは、LLM を利用したアプリケーションを構築するには、基盤となる API モデルの変更を監視する必要があることを示しています。
これは、LLM を利用したアプリケーションを構築するには、基盤となる API モデルの変更を監視する必要があることを示しています。