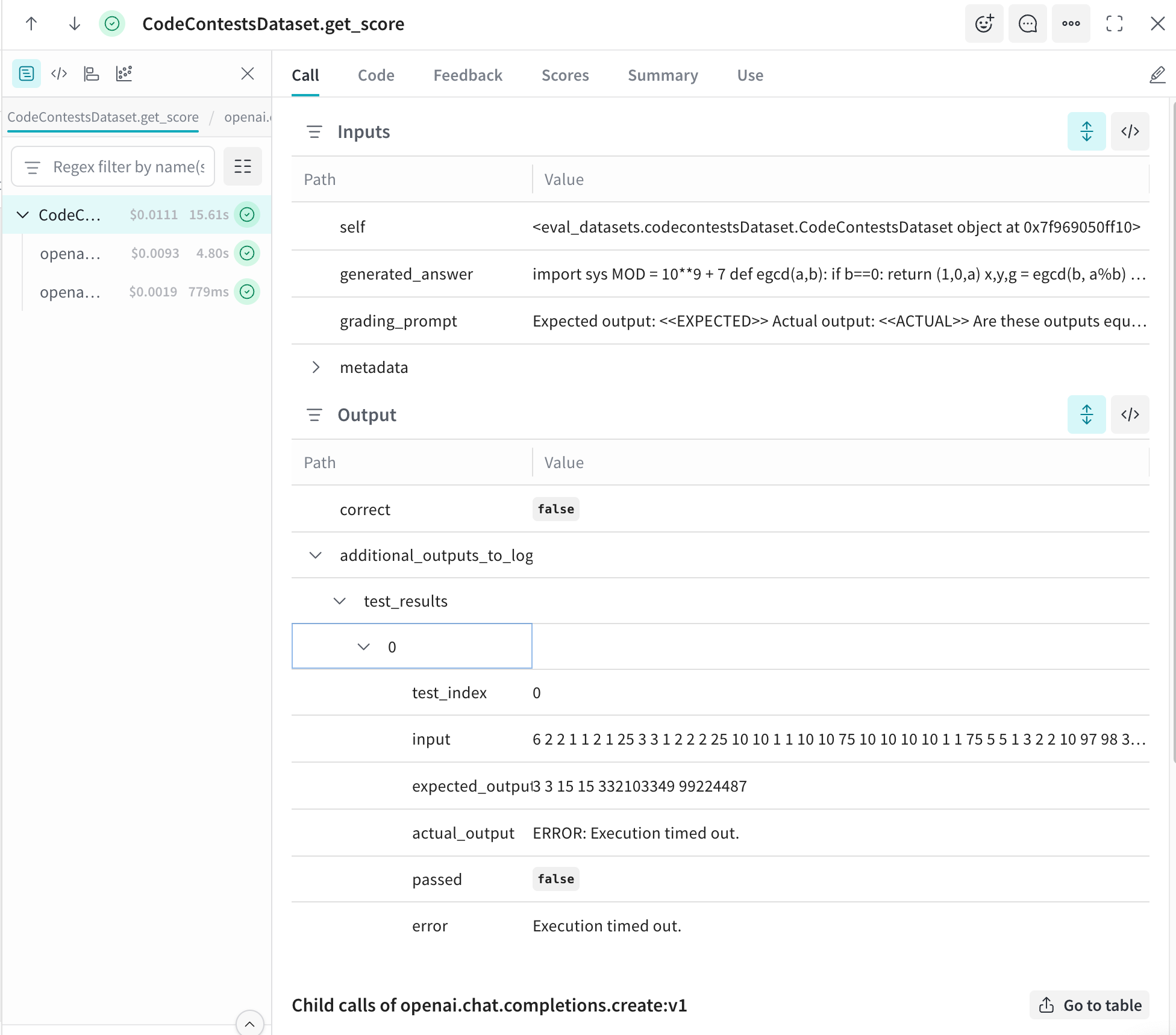
LLM-as-a-judge refers to using large language models to evaluate the outputs of other AI systems by scoring responses for accuracy, relevance, safety, or any other user-specified criteria. These judge models leverage language understanding to make nuanced judgments about quality, much like a human evaluator would.
This approach has rapidly gained traction because it solves a fundamental problem in AI development: how do you evaluate systems at scale when human review is too slow and expensive and traditional metrics are too rigid? Consider the challenge of assessing a RAG system’s answers, or a chatbot’s helpfulness. Human evaluation provides gold-standard quality but does not scale beyond a few hundred examples. Rule-based metrics like BLEU or ROUGE capture surface patterns and miss semantic meaning entirely.
LLM-as-a-judge bridges this gap by delivering human-like judgments at machine speed and cost.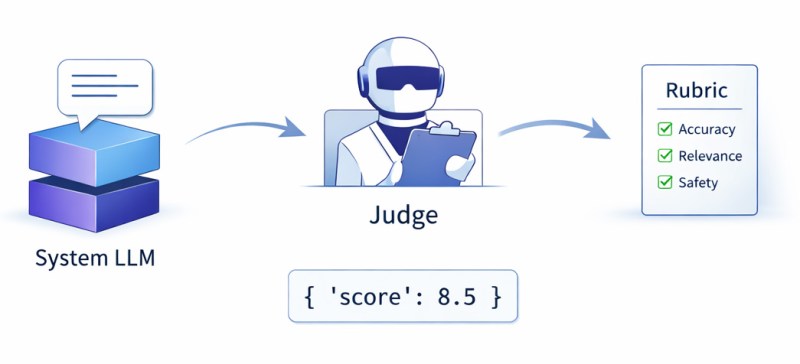
Its versatility extends across the entire AI development lifecycle. In evaluation, judge models assess whether answers are correct and whether they meet quality criteria like helpfulness and clarity, or violate anti-criteria like toxicity and hallucination. In training, judges generate preference pairs for RLHF (Reinforcement Learning from Human Feedback) and GRPO (Group Relative Policy Optimization), rapidly labeling thousands of examples to accelerate model improvement. In production applications, judges monitor responses in real-time, acting as quality filters and guardrails that block unsafe outputs or trigger fallback behaviors when quality drops.
Research has demonstrated that LLM judges can achieve high agreement with human evaluators across diverse tasks, making them a practical tool for teams building and deploying AI systems at scale.
In this article, we’ll cover how LLM-as-a-judge systems work under the hood, their strengths and limitations backed by empirical research, research-validated best practices for building reliable judges, and practical frameworks like the RAG Triad for evaluating real-world applications. By the end you should know when to use LLM-as-a-judge and when to avoid it. Let’s dig in.
The three categories below represent a set of categories I have personally developed. Other groupings are possible, but this set provides the most practical and clear structure I have found for evaluation and monitoring:
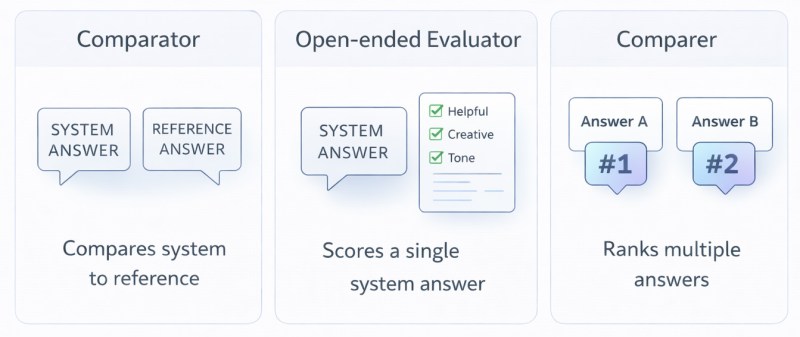
The scope of LLM-as-a-judge evaluation is broad. Judges can be assigned to assess chatbot conversations, code snippets, summaries, translations, step-by-step reasoning, citation-backed answers, creative writing, or any case where quality matters. A judge may review a single response, compare multiple options, or score outputs against trusted reference answers.
One key advantage of this approach is flexibility. The same judge model can be used for dramatically different evaluation tasks by simply adjusting the prompt and the rubric. For example, evaluating medical accuracy relies on different criteria than judging the creativity of a story, but both can be addressed by the same judge with a suitable prompt.
LLM-as-a-judge also extends to process supervision using Process Reward Models, or PRMs. Rather than judging only the final answer, PRMs evaluate each step in a reasoning chain for logical coherence and correctness. This allows for catching where reasoning goes astray, not just whether the outcome is right or wrong. For multi-step problems, mathematical proofs, or complex planning, PRMs provide detailed feedback on each stage, helping to pinpoint both effective reasoning and specific mistakes. This kind of granular supervision enables more focused improvements than approaches that look only at final results.
At its core, LLM-as-a-judge follows a straightforward pipeline:
input + system output (+ optional reference answer) → evaluation prompt → LLM judge → score
Understanding each step and the variations within this pipeline is crucial for building effective evaluation systems.
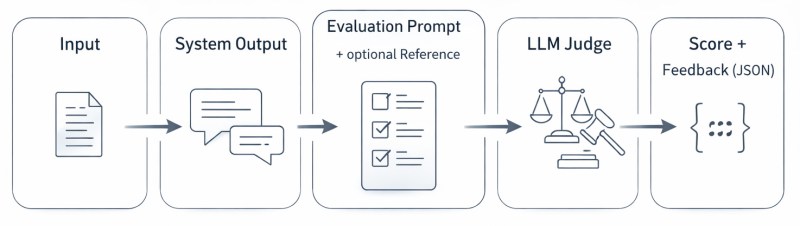
The process begins with collecting what needs to be evaluated. The input is the original query or task given to the system being judged, such as a user question, a prompt, or a problem statement. The system output is the response generated by the model under evaluation. Optionally, a reference answer (ground truth or gold standard response) can be included when evaluating factual accuracy or comparing against known correct answers.
These components are fed into an evaluation prompt sent to the judge LLM. This prompt is arguably the most critical piece of the entire system. It defines the judge’s role, specifies the evaluation criteria, provides the scoring scale, and sets output format requirements.
A well-crafted evaluation prompt might include:
After the judge responds, the evaluation system must parse the output. Structured output formats (JSON, XML) make this reliable and programmatic. A typical parsed result might include a numeric score, a categorical judgment (pass/fail, A/B/C grades), and reasoning explaining the decision. Parsing failures indicate prompt design issues and should trigger refinements to the evaluation prompt.
Single judges can be inconsistent or biased. Multi-judge ensembles address this by running multiple evaluations and aggregating results. Common strategies include:
These approaches increase reliability at the cost of more API calls and latency. The tradeoff depends on how critical accuracy is for the application.
Evaluating retrieval-augmented generation systems requires specialized metrics that go beyond general quality assessment.

The RAG Triad breaks evaluation into three components:
Alternative frameworks like RAGAS provide additional metrics, such as faithfulness (similar to groundedness), answer correctness (by comparing against reference answers), and context precision (ranking the quality of retrieved documents). These metrics can be evaluated by LLM judges with appropriately designed prompts that incorporate both the query and retrieved documents.
A reward model acts as a judge during preference-based training. In Reinforcement Learning from Human Feedback (RLHF), the process includes:
The reward model learns to mimic human preferences and serves as an automated judge to evaluate outputs at scale. This enables the model to receive consistent feedback and reinforces behaviors that match human values and criteria, making data collection and optimization much faster and more efficient.
Group Relative Policy Optimization (GRPO) takes a different approach by generating multiple candidate responses for each prompt and using relative rankings to guide training. LLM judges can rank these candidates, providing the preference signal needed for optimization without requiring explicit reward model training.
The key advantage is speed and scale: LLM judges can evaluate millions of examples for pennies per thousand, enabling rapid iteration on model training that would be prohibitively expensive with human labelers.
For tasks requiring multi-step reasoning, such as math problems, coding, or complex analysis, Process Reward Models evaluate intermediate steps rather than just final answers. PRMs assign scores to each reasoning step, identifying where the model’s logic breaks down.
LLM judges can serve as PRMs by evaluating each step of a chain-of-thought response:
This granular feedback enables training systems that not only produce correct final answers but follow sound reasoning throughout. It’s particularly valuable for catching subtle errors that lead to correct-looking but fundamentally flawed solutions.
PRMs can be trained discriminative models (smaller, faster, specialized for step verification) or LLM judges prompted to evaluate reasoning chains. The choice depends on throughput requirements, cost constraints, and the complexity of reasoning being evaluated.