
Your AI assistant gets a question wrong. A domain expert notices, types “That’s not how we calculate quarterly returns. Use the fiscal year-end date, not calendar year,” and moves on. Three weeks later, the same question comes up. The assistant gets it right this time. Not because someone retrained the model. The system remembered that correction and applied it.
This is Agent Learning from Human Feedback in action. ALHF. The idea that AI agents can improve through natural language corrections from domain experts, without the traditional retraining cycle.
In this article, we’ll walk through what ALHF actually involves, where it differs from the RLHF approach you’ve probably heard about, and what the research and early deployments tell us about making it work. We’ll also look at how to set up a practical feedback loop using Weights & Biases. The focus here is on concepts and organizational considerations. If you’re a manager trying to understand whether this approach makes sense for your team, this is for you.

Executive summary on ALHF for busy leaders
ALHF lets AI agents adapt to your organization’s expectations through plain-language corrections from domain experts, with no retraining and no numeric reward signals. It matters because it compresses the months-long fine-tuning cycle into days or weeks, allowing people who already know the work to shape agent behavior directly. The trade-off is that it depends on feedback quality, which is messier in practice than the research assumes.
Here’s the short version. ALHF enables AI agents to adapt to expert expectations through natural-language comments. No hard-coded rules. No numeric reward signals. When a financial analyst tells an agent “always cite the data source for compliance,” that instruction gets stored and applied to future queries. The underlying model stays the same.
Why does this matter for organizations deploying AI systems?
Traditional fine-tuning requires collecting examples, running training jobs, and managing deployment cycles. That takes months and needs ML expertise. ALHF lets domain experts shape agent behavior in days or weeks. They teach the agent directly using language they already use every day. Does your legal team have specific language requirements? Does your finance group calculate metrics differently from the textbook? ALHF gives you a way to continuously inject that knowledge.
Databricks reported that its internal Knowledge Assistant showed measurable improvements in answer completeness and feedback adherence within weeks of deploying this kind of mechanism. Analytics8 saw similar gains with analytics copilots serving non-technical users.
But we should be clear about the limitations. ALHF relies on assumptions about human feedback that often break down in practice. Feedback isn’t always consistent. Experts disagree. People get tired and stop paying close attention. How you design the feedback collection process matters as much as the technical implementation.
From static models to teachable AI agents
The shift is from treating a model as a fixed artifact that occasionally gets retrained to treating it as something that learns continuously from expert feedback. You make this move because generic foundation models, even with good prompts and retrieval, can’t capture the specialized rules, calculations, and policies that vary by team and change over time. Teachable agents close that gap by capturing corrections as they happen and letting them shape future behavior.
Most enterprise AI deployments follow a familiar pattern. Take a foundation model, write some prompts, maybe add retrieval over internal documents, ship it. Works well enough for generic tasks.
Then you hit the wall.
Your legal team has specific language requirements. Finance calculates metrics in ways that differ from textbook definitions. Customer support follows escalation policies that change quarterly. The generic model doesn’t know any of this. Prompting helps, but only goes so far.
The traditional fix? Fine-tuning.
Collect examples, train the model on your data, redeploy. This works, but it’s slow, expensive, and requires ML expertise most organizations don’t have in-house.
Teachable agents work differently. You stop treating the model as a fixed artifact that occasionally gets retrained. Instead, you treat it as something that learns continuously from expert feedback. The agent proposes an answer. Expert reviews it. System captures the correction. That correction influences future behavior.
Humans have always learned from feedback.
What’s new is making this work at scale for AI systems, with natural language as the interface.
What is Agent Learning from Human Feedback?
ALHF is a method for improving a deployed agent by capturing expert feedback as natural language, storing it, retrieving it when relevant, and injecting it into future responses. Instead of reducing human judgment to a number, it preserves the full context of what the expert said and why. The result is an agent that gets better at your specific tasks without any traditional retraining of the underlying model.
But let’s explore what’s actually happening under the hood.
In traditional supervised learning, you show the model thousands of input-output pairs. It learns the pattern. In reinforcement learning, you give it a reward signal (just a number) and it learns to maximize that signal. RLHF sits between these approaches. Humans rate outputs; those ratings train a reward model, which then guides the agent.
ALHF takes a different path. Rather than reducing human judgment to a number, it captures the full context of expert feedback in natural language. An analyst says, “This answer is correct but too technical for our sales team; simplify the jargon.” That entire instruction becomes part of how the agent behaves going forward.
Three things need to happen for this to work.
You need to capture feedback. When an expert reviews an agent’s output, the system records what the expert said, the original query, and the context the agent had at the time.
You need to retrieve that feedback later. When a new query arrives, the system searches for relevant past corrections. Things that apply to similar situations get pulled in.
You need to update behavior based on what you retrieved. The agent incorporates relevant feedback into its response. Sometimes this happens through prompt injection (you just add the feedback to the context). Sometimes through more sophisticated mechanisms, such as adapter tuning.
What you end up with: an agent that gets better at your specific tasks without going through traditional retraining.
How ALHF differs from RLHF
RLHF, the approach OpenAI and Anthropic use to align foundation models, collects human preferences at scale. We’re talking thousands of comparisons. They train a reward model that guides the base model toward preferred behaviors. It’s a powerful approach, but it operates at a different level. It shapes general model behavior, not how a deployed agent handles your specific workflows.
The differences come down to granularity, timing, and format.
RLHF uses numeric ratings or pairwise comparisons. ALHF uses natural language corrections. RLHF aggregates preferences across many examples. ALHF captures task-specific, contextual feedback. RLHF happens during training, before deployment. ALHF happens continuously while the system is live. RLHF typically relies on paid contractors or crowdworkers. ALHF uses domain experts inside your organization. RLHF requires model retraining. ALHF works through retrieval and prompt injection.
What does this mean practically? RLHF requires machine learning infrastructure and training budgets. ALHF can work with off-the-shelf models and a well-designed feedback interface. The experts teaching the agent are often the same people who would be answering questions manually anyway.
Some early research on cross-domain knowledge transfer suggests that feedback learned in one context can sometimes transfer to related tasks. Feedback about financial terminology might apply across multiple finance-related agents. Still early days, but promising.
For managers: ALHF gives you faster iteration loops, lower data requirements, and finer control over agent behavior. You don’t need to become a machine learning shop to make it work.
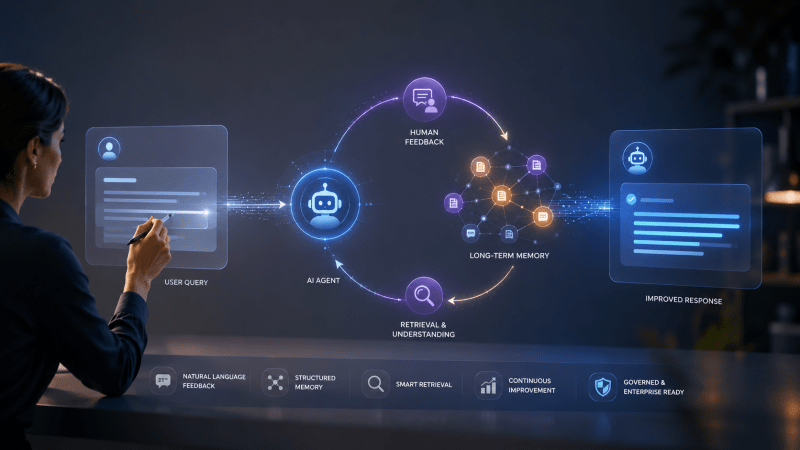
Inside ALHF: How AI agents learn from natural language feedback
The loop works like this: the agent answers, an expert spots a problem and writes a plain-language correction, and the system stores that correction along with the original query and context, making it searchable. When a similar query arrives later, retrieval surfaces the relevant feedback and folds it into the new response. The hard part is deciding when past feedback actually applies, which production systems handle by combining semantic similarity, query classification, and explicit tags.
Let’s walk through what the feedback loop actually looks like in practice.
Someone asks the agent a question. The agent generates a response based on what it knows and whatever context it retrieved. A domain expert (or sometimes the user themselves) reads this response. They spot issues. Maybe a factual error. Wrong tone. Missing context. Policy violation.
The expert writes a correction in plain language. The system stores this correction alongside the original query, context, and response. That correction becomes searchable, typically through embedding-based retrieval. When similar queries come in later, the system can surface this feedback.
Here’s where it gets tricky. Deciding when past feedback applies to a new query isn’t straightforward. Naive keyword matching misses semantic similarity. Pure embedding retrieval can surface irrelevant feedback. Production systems typically combine multiple signals. Semantic similarity. Query type classification. Explicit tags assigned during feedback collection.
The feedback itself can target different aspects of agent behavior.
- An expert might correct content accuracy: “The Q3 revenue figure should be $4.2M, not $4.5M.”
- They might address tone: “Too formal for customer-facing responses. Use simpler language.”
- Reasoning steps: “When calculating churn, exclude trial accounts from the denominator.”
- Tool usage: “For compliance questions, always query the policy database before answering.”
- Or format: “Financial summaries should lead with the key metric, not background context.”
The more specific your feedback taxonomy, the more precisely the system can apply corrections where they actually matter.
Human-in-the-loop components and feedback modes
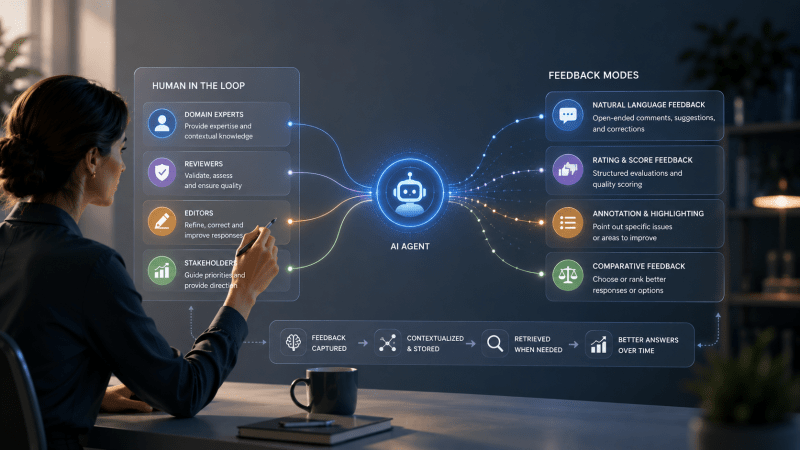
Every ALHF system needs a control point where humans can step in, review outputs, and teach the agent. This determines how much autonomy the agent has and when it asks for help.
Microsoft’s AutoGen framework offers a useful way to think about this through its ConversableAgent class, which supports three input modes.
- In NEVER mode, the agent runs fully autonomously. It receives a task, executes it, returns results. No human intervention. Fast, but you don’t get any opportunity for correction until after the fact.
- In ALWAYS mode, the agent requests human input at every step. Maximum control. But this creates bottlenecks. Really only makes sense for high-stakes tasks where errors carry serious consequences.
- TERMINATE mode sits in the middle. The agent works autonomously until it reaches a decision point or finishes the task, then surfaces results for human review. You get some efficiency while maintaining oversight.
These choices have staffing implications. NEVER mode means minimal oversight with periodic audits. ALWAYS mode means dedicated reviewers per agent. TERMINATE mode means review queues and async feedback workflows.
Why does this connect to ALHF? You can only collect feedback at points where humans interact with the agent. ALWAYS mode generates the most training signal but incurs the highest cost. TERMINATE mode hits a balance most organizations can sustain. You get enough human touchpoints to learn from without drowning your experts in review work.
Designing effective feedback mechanisms for enterprise AI systems
A feedback mechanism is more than a thumbs-up button. It’s the entire process that captures, structures, stores, and applies human comments to improve AI systems. Get this wrong and feedback piles up in dashboards without driving any real improvement.
What makes feedback mechanisms work in practice?
Low friction matters. If giving feedback takes more than 30 seconds, people won’t do it consistently. The interface needs to live inside the workflow, not as a separate tool they have to navigate to.
Structure helps, but only if it’s lightweight. Free-text feedback is valuable but hard to systematize. Adding basic tags (feedback type, severity, applicable scope) makes retrieval and analysis easier without burdening experts.
Routing matters too. Feedback about factual errors might need to update a retrieval index. Feedback about tone might adjust prompt templates. Feedback about tool usage might modify available actions. The mechanism needs to know where each correction should go.
And you need to measure whether any of this is working. Track whether feedback is being used. If the same correction keeps appearing for similar queries, something in your retrieval is broken.
Different applications need different designs. Knowledge assistants (such as those Databricks built internally) focus on answer completeness and source accuracy. Feedback often includes pointers to authoritative documents the agent should have cited. Analytics copilots (like those Analytics8 deploys) handle query interpretation. Did the agent understand the business question behind the technical request? Customer service agents balance accuracy with tone and policy compliance.
But the metrics stay similar across all of these. Is feedback reducing repeated mistakes? Are experts providing fewer corrections over time? Is user satisfaction improving?
Questionable assumptions about human feedback
Much of the AI alignment literature treats human feedback as ground truth. In research settings, this simplification is often necessary. In production, it breaks down.
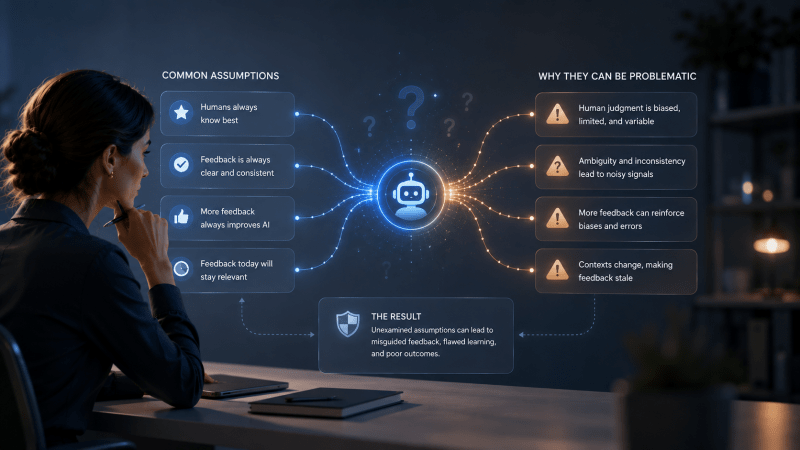
Research presented at ICML’s workshop on models of human feedback identified several assumptions that frequently fail in real deployments.
- The assumption is that humans are rational and consistent. In practice, the same expert might give different feedback on the same output depending on workload, mood, or what they reviewed five minutes earlier. Quality varies.
- The assumption is that feedback represents a single coherent set of values. Different departments want different things. Legal wants precision. Marketing wants engagement. There’s often no single “correct” behavior to optimize for.
- The assumption is that annotators stay attentive. Fatigue is real. Review quality degrades over long sessions. You’re better off collecting high-stakes feedback in short bursts rather than marathon labeling sessions.
- The assumption is that labels are ground truth. Sometimes the expert is wrong. Sometimes the policy changed, and nobody told them.
Treat feedback as evidence, not gospel.
What does this mean for managers deploying ALHF systems?
- Use diverse raters. A single expert per domain creates blind spots. Cross-check feedback from multiple sources.
- Build calibration processes. Periodically review feedback quality. Remove or downweight feedback from consistently unreliable sources.
- Version your feedback. Policies change. Yesterday’s correct answer might violate today’s compliance requirements. Feedback needs timestamps and expiration mechanisms.
- Expect disagreement. When experts conflict, you need a resolution process. Not an assumption that someone must be wrong.
Measuring AI agent learning: metrics and tools
To justify investment in ALHF, you need metrics showing that feedback actually improves agent behavior. “It feels better” isn’t a business case.
Think about metrics in three categories.
- Agent output quality. Did the task success rate improve? Are answers more complete? Is policy adherence higher? These are the outcomes you ultimately care about.
- Feedback coverage. What fraction of agent interactions receive expert review? Are you collecting feedback on the right queries (edge cases, failures) or just easy ones?
- Feedback utilization. When feedback exists for a query type, is it getting retrieved and applied? If the same correction keeps appearing, your retrieval mechanism isn’t working.
The Databricks Knowledge Assistant case offers concrete examples. Their team tracked answer completeness (did the response address all aspects of the question?) and feedback adherence (when relevant feedback existed, did the response reflect it?).
Both improved measurably after they deployed their feedback mechanism. Adherence showed faster gains since feedback retrieval is relatively straightforward. Completeness improved more gradually since it requires the agent to internalize broader patterns.
Emerging tools like AutoLibra aim to automate metric discovery for agents, inferring what to measure based on task structure rather than requiring manual metric definition. Still research-grade, but signals where the field is heading.
Practical implementation: Setting up an ALHF loop with Weights & Biases
Implementing ALHF means wiring your agents, feedback interface, and evaluation tools into a single learning loop. The goal is to instrument what you already have so that feedback flows from experts to agents systematically.
A typical architecture has five pieces.
- The LLM or AI agent generating responses.
- The feedback capture interface where experts review outputs and provide corrections.
- A feedback store (database with semantic search support) holding feedback records with associated queries, contexts, and metadata.
- An evaluation pipeline running automated tests on whether feedback is being applied and whether agent quality is improving.
- Dashboards and monitoring for visibility into feedback volume, utilization rates, and quality trends.
Weights & Biases’ Models provides tooling for evaluation and monitoring, with Weave handling tracing. Every agent interaction gets logged with inputs, outputs, and any retrieved feedback. Evaluation runs compare agent behavior with and without feedback, tracking improvement over time.
ALHF example: Instrumenting an AI knowledge assistant with Weights & Biases
Let’s walk through what this looks like in practice. Code is available in a companion repository, but we’ll focusing here on what you’re measuring and why.
Step 1: Define success metrics.
Before writing any code, agree on what better means. For a knowledge assistant, you probably care about answer accuracy, completeness, source grounding, and feedback adherence. These become your evaluation criteria in Weave.
Step 2: Log every agent interaction.
Wrap your agent’s response function with Weave’s @weave.op() decorator. This captures inputs, outputs, and timing automatically.
@weave.op()
def answer_question(query: str, context: list[str]) -> str:
# Your agent logic here
return responseEvery call now appears in the Weave UI with full traceability.
Step 3: Collect structured human feedback.
When experts review responses, capture the original query and response, the correction in natural language, feedback type, and severity. Store in a format supporting semantic search since you’ll retrieve this for future queries.
Step 4: Build an evaluation dataset.
Pull a sample of queries with expert feedback. This becomes your “golden set” for measuring improvement. Include cases where the original response was wrong and cases where it was right. You want to catch regressions, not just improvements.
Step 5: Run evaluations with and without feedback retrieval.
Using Weave’s Evaluation framework, compare agent performance. Run a baseline where the agent responds without retrieved feedback. Run again with ALHF, where the agent responds with relevant feedback injected into context. Track your metrics from Step 1 across both conditions.
Step 6: Review results in the Weights & Biases UI.
The Weave interface shows traces (individual interactions with full context), evals (aggregate metrics across runs comparing baseline vs. ALHF), and leaderboards (side-by-side comparison if you’re testing multiple retrieval strategies).
You’re looking for high feedback adherence (when feedback exists, it’s being used) and improving outcome metrics (accuracy, completeness) over time as the feedback store grows.
Step 7: Close the loop.
Review cases where feedback exists but wasn’t applied, or was applied but didn’t help. These indicate retrieval problems or feedback quality issues. Refine your taxonomy and retrieval strategy based on what you learn.
Analyzing the results in the Weights & Biases UI
When you generate such a system and you’ve run a few interactions and an evaluation, the Weave interface gives you two views that matter.
Traces view: seeing what actually happened
Open the Traces tab in the left sidebar. Each row represents one call to your agent. You’ll see the function name, timing, token count, and cost estimate. Click any row to expand it.

Inside an expanded trace, you get the call hierarchy. The parent call (your main agent function) contains child calls for each operation: retrieving context from the knowledge base, retrieving relevant feedback (if ALHF mode is enabled), building the prompt, and generating the response. This hierarchy shows you exactly where time goes. If retrieval is slow, you’ll see it. If the LLM call dominates, that’s visible too.

The detail panel shows inputs and outputs for each operation. For the top-level agent call, you see the user’s query as input and the generated response as output. For the feedback retrieval call, you see which past corrections were surfaced and their similarity scores. This is where you verify that the right feedback is being retrieved for the right queries.
Evals view: comparing baseline to ALHF
After running the evaluation script, navigate to the Evals tab. You’ll see two evaluation runs: one for baseline (no feedback) and one for ALHF (with feedback).
Each row shows aggregate metrics across all test cases.
The columns show your scorers. Relevance score measures whether expected topics appear in responses. Helpfulness score uses an LLM judge to rate response quality. You might add others depending on your use case.
Select both rows and click Compare. The side-by-side view makes differences obvious. If ALHF is working, you should see higher scores in the feedback-enabled run. Small differences (a few percentage points) might be noise. Large differences (10%+ improvement) suggest the feedback mechanism is adding real value.
Click into individual evaluation runs to see per-example results. This table shows each test query, the agent’s output, and scores for that specific case. Look for patterns. Does ALHF help more with certain query types? Are there cases where feedback hurt rather than helped? These edge cases guide where to focus improvement efforts.
Alternative ALHF use cases you can pilot quickly
Beyond knowledge assistants, ALHF patterns apply to several common scenarios.
Internal analytics copilots. Data analysts and business users provide feedback on query interpretation, metric definitions, and visualization choices. You track query accuracy, self-service rate, and time to insight.
Documentation and FAQ assistants. Technical writers and product managers provide feedback on accuracy, completeness, and detail level. You track deflection rate from support tickets and satisfaction scores.
Customer support triage bots. Senior support agents and team leads provide feedback on issue classification, escalation decisions, and tone. You track first-contact resolution, escalation accuracy, and CSAT.
Code review helpers. Senior engineers and the security team provide feedback on best practices, security patterns, and style consistency. You track review throughput, catch rate, and false positive rate.
Compliance policy checkers. Legal and compliance officers provide feedback on policy interpretation, edge cases, and required disclosures. You track violation detection rate, false positive rate, and audit outcomes.
For any of these, start narrow. Pick one workflow, instrument it, collect feedback for a few weeks, and measure whether the agent improves. Expand only after you’ve validated that the loop works.
Governance, risk, and organizational design
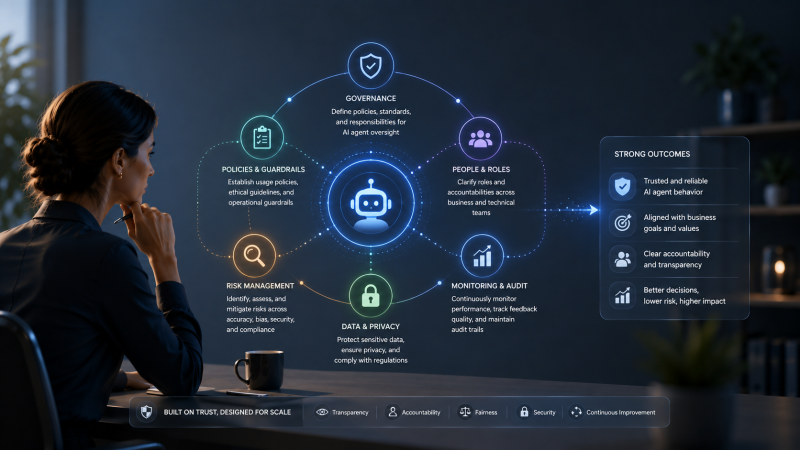
Building AI systems that learn from human feedback is as much an organizational challenge as a technical one. Without clear governance, feedback-driven agents can entrench bias, create accountability gaps, or drift in ways nobody intended.
Questions to address before deployment.
- Who can teach the agent? Not everyone’s feedback should carry equal weight. Define roles. Who provides authoritative corrections? Who reviews feedback for quality? Who resolves conflicts when experts disagree?
- How is feedback governed? Create guidelines for what constitutes good feedback. Review feedback periodically for consistency and accuracy. Remove or downweight feedback that’s outdated or from unreliable sources.
- What are the risks? If feedback comes from a homogeneous group, the agent learns their blind spots. Without quality controls, low-effort or malicious feedback degrades performance. If experts are evaluated on feedback volume rather than quality, you get quantity over quality. If one expert provides most feedback, the agent reflects their idiosyncrasies.
- How do you align with existing policies? ALHF systems need to connect with corporate policies, legal constraints, and risk frameworks. Feedback about financial calculations should go through compliance review. Feedback about customer data handling needs privacy review.
- How do you audit the system? Maintain logs of what feedback was applied when. If an agent makes a mistake, you need to trace whether it was following feedback, and from whom. Weights & Biases reports provide this visibility layer.
Future directions
Research on models of human feedback is moving fast.
Current systems treat feedback as text to be retrieved and injected. Future systems will build more sophisticated models of expert preferences, handling disagreement, uncertainty, and context more gracefully.
Real feedback is inconsistent. Research on robust aggregation (learning from feedback that’s sometimes wrong or contradictory) will make ALHF more practical at scale.
Feedback learned in one context might transfer to related contexts. Early work suggests this is possible but not automatic.
Frameworks like AutoLibra (for metric discovery) and ALHF-specific evaluation libraries are emerging. As tooling matures, implementation gets easier.
ALHF isn’t a replacement for RLHF or constitutional AI. Future systems will likely combine foundation-level alignment with deployment-time adaptation.
For managers: stay adaptable. Build modular architectures that can incorporate new feedback mechanisms as they mature. Establish an experimentation culture where new approaches get tested and measured. Maintain evaluation infrastructure so you know what’s actually working.
What leaders should do next
ALHF offers a practical path to teach AI agents your organization’s rules, workflows, and values. Capture expert corrections, retrieve them when relevant, and apply them to improve future responses. The execution requires attention to feedback quality, retrieval mechanisms, and organizational governance.
If you’re considering ALHF, here’s how to start.
- Pick a narrow use case. Don’t try to make all your agents teachable at once. Start with one high-value workflow where expert feedback is readily available.
- Define success metrics. What does improvement look like? Answer accuracy? Task completion? User satisfaction? Measure something concrete.
- Instrument for visibility. Use Weights & Biases or similar tooling to log interactions, capture feedback, track metrics over time.
- Build governance early. Decide who can provide feedback, how it’s reviewed, how conflicts are resolved.
- Iterate and expand. Once you’ve validated the loop works for one use case, extend to others. Reuse your feedback infrastructure and evaluation pipelines.
Organizations that figure out how to teach their AI systems systematically will have an advantage over those still treating models as static artifacts. ALHF is one path to get there. With clear metrics, good governance, and continuous learning, you can build AI systems that actually reflect what your experts know.