

ハイパーパラメータの自動最適化の方法
自動ハイパーパラメータ最適化で使用される3つの主なアルゴリズムは、
-
グリッド検索
3 つのアルゴリズムの主な違いは、次にテストするハイパーパラメータ値のセットを選択する方法です。ただし、検索空間の定義方法 (固定値と値の範囲) や実行回数の指定方法 (暗黙的と明示的) も異なります。
このセクションでは、これらの違いと、それぞれの長所と短所について説明します。
以下では、W&B Sweepsを使用してハイパーパラメータepochsとlearning_rate を最適化します。詳細については、関連するKaggle NotebookとW&B プロジェクトをご覧ください。
グリッド検索
グリッド検索は、指定されたグリッド (直交積) 内のすべての可能なハイパーパラメータの組み合わせを評価するハイパーパラメータ調整手法です。これは、ハイパーパラメータが少ない ML モデルにのみ推奨されるブルート フォース アプローチです。
入力
-
最適化したいハイパーパラメータのセット
-
各ハイパーパラメータの離散探索空間は特定の値として
-
最適化するためのパフォーマンス指標
-
(暗黙的な実行回数:検索空間は固定された値のセットであるため、実行する実験の数を指定する必要はありません)
(ランダム検索とベイズ最適化の違いは上記で太字で強調表示されています。)
Python でグリッド検索を実装する一般的な方法は、 scikit learnライブラリのGridSearchCVを使用することです。または、次に示すように、W&B を使用してハイパーパラメータ調整用のグリッド検索を設定することもできます。

手順
ステップ 1: グリッド検索アルゴリズムは、指定されたハイパーパラメータ値のすべての可能なハイパーパラメータの組み合わせのグリッド (直積) を作成することによって、評価するハイパーパラメータ値のセットを選択します。次に、グリッドを反復処理します。このアプローチは、徹底的な検索またはブルート フォース アプローチです。
以下に、この例の結果のグリッドを示します。
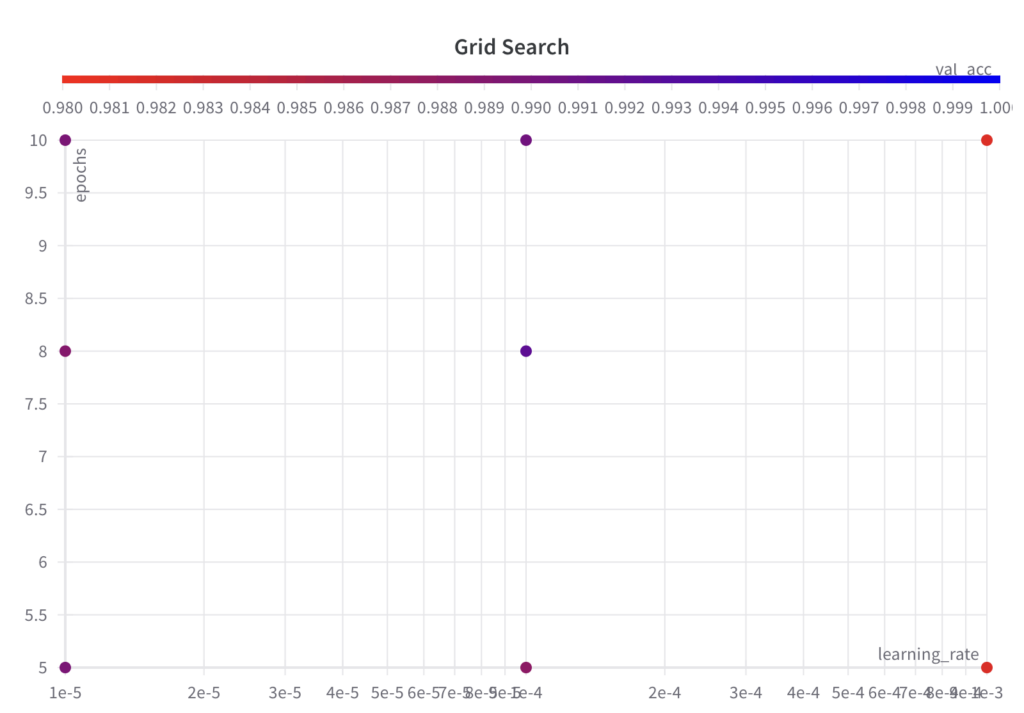
ステップ 2: 選択したハイパーパラメータのセットとその値に対して ML 実験を実行し、そのパフォーマンス メトリックを評価してログに記録します。
ステップ3: 指定された回数の試行を繰り返し、モデルのパフォーマンスに満足するまで繰り返します。
出力
すべての自動化されたハイパーパラメータ最適化アルゴリズムと同様に、グリッド サーチは、最高のパフォーマンス メトリックとそれぞれのハイパーパラメータ値を持つ実験を返します。
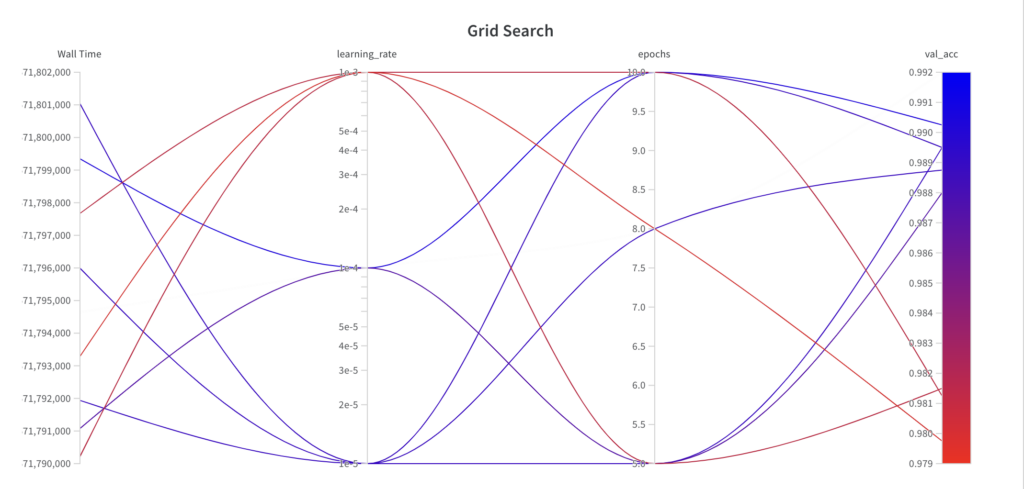
以下に、ハイパーパラメータ最適化アルゴリズムがどの時点でどのパラメータを選択したか、および結果として得られたパフォーマンスを示します。次のことがわかります。
-
グリッド検索アルゴリズムは、指定されたハイパーパラメータ セットのグリッドを反復処理します。
-
グリッド検索は情報に依存しない検索アルゴリズムであるため、結果として得られるパフォーマンスは実行全体にわたって傾向を示しません。
-
最高のval_accスコアは0.9902です
利点
-
実装が簡単
-
並列化が可能:ハイパーパラメータセットを独立して評価できるため
デメリット
-
多くのハイパーパラメータを持つモデルには適していません。これは主に、計算コストがハイパーパラメータの数に応じて指数関数的に増加するためです。
-
以前の実験からの知識が活用されていないため、情報に基づかない検索になります。良好な結果を得るには、微調整された検索スペースでグリッド検索アルゴリズムを複数回実行することをお勧めします。
調整するハイパーパラメータが 3 つ以下でない限り、通常はグリッド検索を避けることをお勧めします。
ランダム検索
ランダム検索は、指定された検索空間からランダムに値をサンプリングするハイパーパラメータ調整手法です。多くのハイパーパラメータを持ち、そのうちのほんの一部がモデルのパフォーマンスに影響を与えるMLモデルの場合、グリッド検索よりも効果的です[1]。
入力
-
最適化したいハイパーパラメータのセット
-
各ハイパーパラメータの値の範囲としての連続的な探索空間
-
最適化するためのパフォーマンス指標
-
明示的な実行回数:検索スペースは連続しているため、手動で検索を停止するか、実行の最大回数を定義する必要があります。
グリッド検索との違いは上記で太字で強調表示されています。
Python でランダム検索を実装する一般的な方法は、 scikit learnライブラリのRandomizedSearchCVを使用することです。または、以下に示すように、W&B を使用してハイパーパラメータ調整用のランダム検索を設定することもできます。

手順
ステップ 1: ランダム検索アルゴリズムは、指定された反復回数ごとに指定された検索空間からハイパーパラメータ値をランダムにサンプリングして、評価するハイパーパラメータのセットを選択します。
以下では、ハイパーパラメータ値のサンプリングされたセットが、グリッド検索アルゴリズムのようなグリッドに従わないことがわかります。
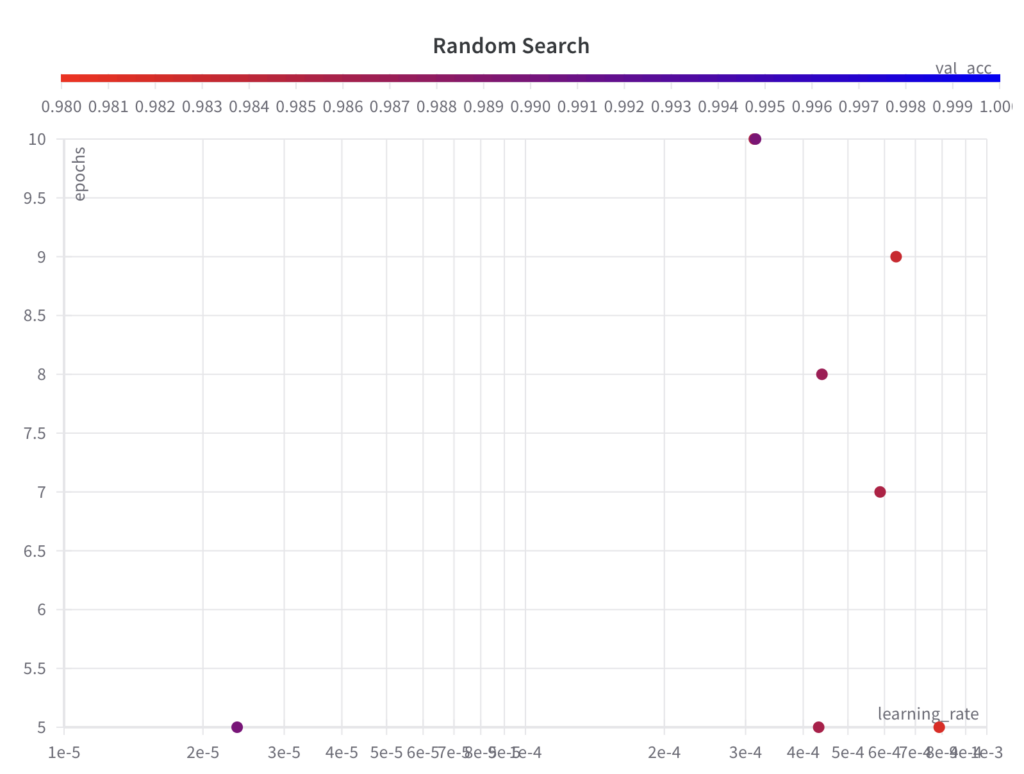
ステップ 2: 選択したハイパーパラメータのセットとその値に対して ML 実験を実行し、そのパフォーマンス メトリックを評価してログに記録します。
ステップ 3: 指定された回数だけ試行を繰り返します。
出力
すべての自動化されたハイパーパラメータ最適化アルゴリズムと同様に、ランダム検索は、最高のパフォーマンス メトリックとそれぞれのハイパーパラメータ値を持つ実験を返します。
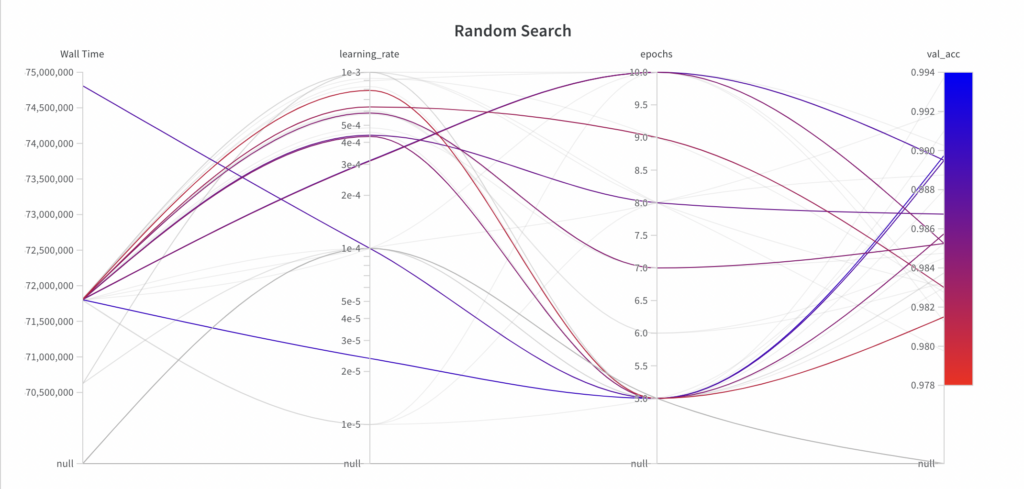
以下に、ハイパーパラメータ最適化アルゴリズムがどの時点でどのパラメータを選択したか、および結果として得られたパフォーマンスを示します。次のことがわかります。
-
ランダム検索では、ハイパーパラメータepochsの全検索空間から値をサンプリングしますが、最初の数回の実験ではハイパーパラメータlearning_rateの全検索空間を探索しません。
-
ランダム検索は情報に依存しない検索アルゴリズムであるため、結果として得られるパフォーマンスは実行全体にわたって傾向を示しません。
-
最高のval_accスコアは 0.9868 で、グリッド検索で達成された最高のval_accスコア (0.9902) よりも悪いです。この主な理由は、 learning_rate がモデルのパフォーマンスに大きな影響を与え、この例ではアルゴリズムが適切にサンプリングできなかったためだと考えられます。
利点
-
実装が簡単
-
並列化可能:ハイパーパラメータセットを独立して評価できるため
-
多くのハイパーパラメータを持つモデルに適しています。多くのハイパーパラメータを持ち、モデルのパフォーマンスに影響を与えるハイパーパラメータが少数のモデルの場合、ランダム検索はグリッド検索よりも効果的であることが保証されています[1]
デメリット
-
以前の実験からの知識が活用されていないため、情報に基づかない検索になります。良い結果を得るには、微調整された検索スペースでランダム検索アルゴリズムを数回実行することをお勧めします。
ベイズ最適化
ベイズ最適化は、代理関数を使用して次に評価するハイパーパラメータのセットを決定するハイパーパラメータ調整手法です。グリッド検索やランダム検索とは対照的に、ベイズ最適化は情報に基づいた検索方法です。
入力
-
最適化したいハイパーパラメータのセット
-
各ハイパーパラメータの値の範囲としての連続的な探索空間
-
最適化するためのパフォーマンス指標
-
明示的な実行回数:検索スペースは連続しているため、手動で検索を停止するか、実行の最大回数を定義する必要があります。
グリッド検索の違いは上記で太字で強調表示されています。
Python でベイズ最適化を実装する一般的な方法は、 bayes_optライブラリのBayesianOptimizationを使用することです。または、以下に示すように、W&B を使用してハイパーパラメータ調整用のベイズ最適化を設定することもできます。

手順
- ステップ 1: 目的関数の確率モデルを構築します。この確率モデルは代理関数と呼ばれます。代理関数はガウス過程 [2] から派生したもので、さまざまなハイパーパラメータ セットに対する ML モデルのパフォーマンスを推定します。
- ステップ 2: 指定された検索空間で最高のパフォーマンスを達成するために代理関数が期待するものに基づいて、次のハイパーパラメータ セットが選択されます。
以下では、ハイパーパラメータ値のサンプリングされたセットが、グリッド検索アルゴリズムのようなグリッドに従わないことがわかります。
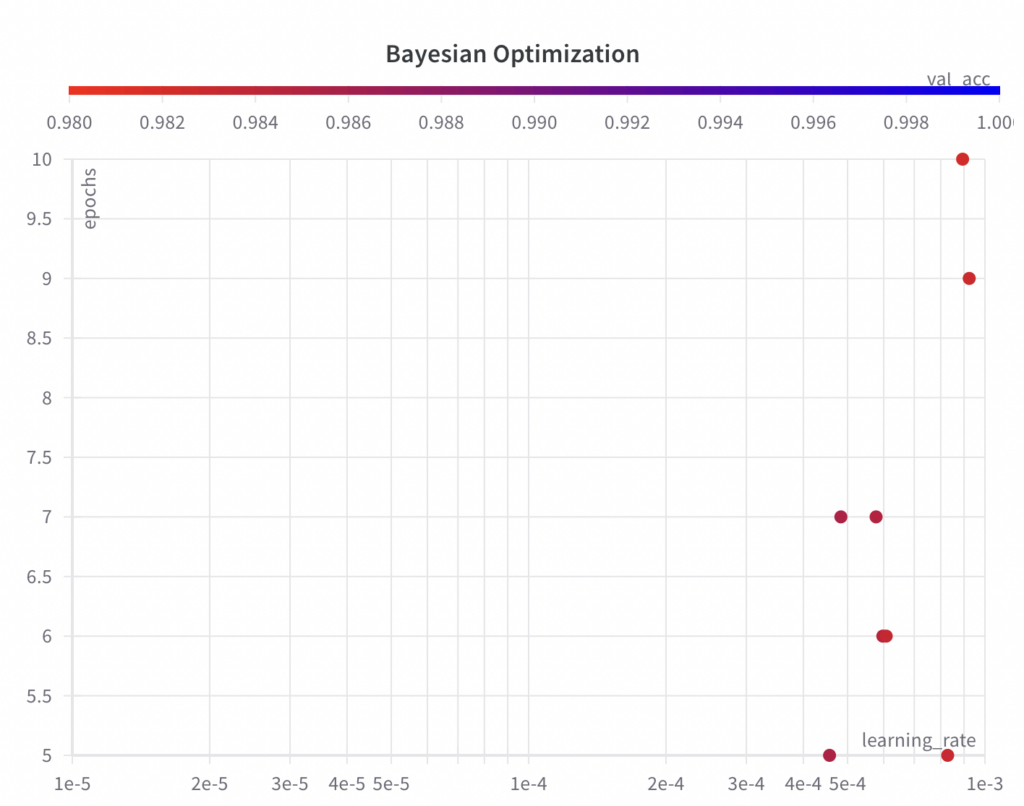
- ステップ 3: 選択したハイパーパラメータのセットとその値に対して ML 実験を実行し、そのパフォーマンス メトリックを評価してログに記録します。
- ステップ 4: 実験後、代理関数は最後の実験の結果で更新されます。
- ステップ 5: 指定された回数だけステップ 2 ~ 4 を繰り返します。
出力
すべての自動化されたハイパーパラメータ最適化アルゴリズムと同様に、ベイズ最適化は、最高のパフォーマンス メトリックとそれぞれのハイパーパラメータ値を持つ実験を返します。
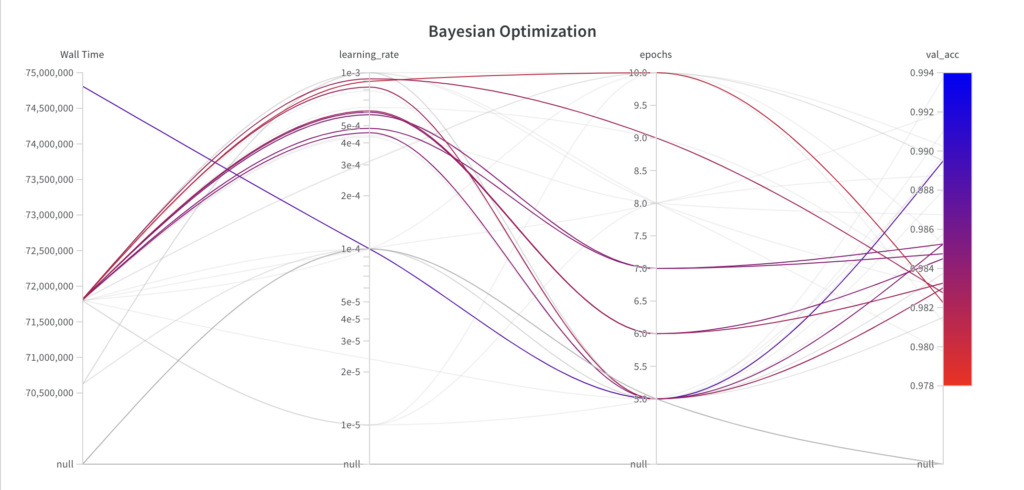
以下に、ハイパーパラメータ最適化アルゴリズムがどの時点でどのパラメータを選択し、その結果どのようなパフォーマンスになったかを示します。次のことがわかります。
-
ベイズ最適化アルゴリズムはハイパーパラメータepochsの完全な検索空間から値をサンプリングしますが、最初の数回の実験ではハイパーパラメータlearning_rateの完全な検索空間を探索しません。
-
ベイズ最適化アルゴリズムは情報に基づいた検索アルゴリズムであるため、結果として得られるパフォーマンスは実行ごとに向上します。
-
最高のval_accスコアは 0.9852 で、グリッド検索 (0.9902) とランダム検索 (0.9868) で達成された最高のval_accスコアよりも悪いです。この主な理由は、 learning_rate がモデルのパフォーマンスに大きな影響を与えるという事実であると考えられますが、この例ではアルゴリズムが適切にサンプリングできませんでした。ただし、アルゴリズムがより良い結果を得るために、 learning_rateを下げ始めていることがわかります。さらに実行すれば、ベイズ最適化アルゴリズムは、より良いパフォーマンスをもたらすハイパーパラメータにつながる可能性があります。
利点
-
多くのハイパーパラメータを持つモデルに適している
-
情報に基づいた検索:過去の実験から得た知識を活用し、適切なハイパーパラメータ値に早く収束できる
デメリット
-
実装が難しい
-
次に評価するハイパーパラメータのセットは前の実験の結果に依存するため、並列化できません。