
Agentic AI refers to systems that can pursue goals by taking a sequence of actions instead of producing a single response. Traditional AI models are typically used in a request-response pattern. A user sends a prompt, the model generates an answer, and the interaction ends. Agentic systems operate differently. They interpret a task, decide what steps are required, execute those steps, and adjust their behavior as the situation evolves.
An agent usually combines several components. A reasoning model determines what actions to take. Tools allow the system to interact with external systems such as search engines, databases, or APIs. Memory stores information about past steps and intermediate results. Together, these components allow the system to perform tasks that require multiple decisions rather than a single prediction.
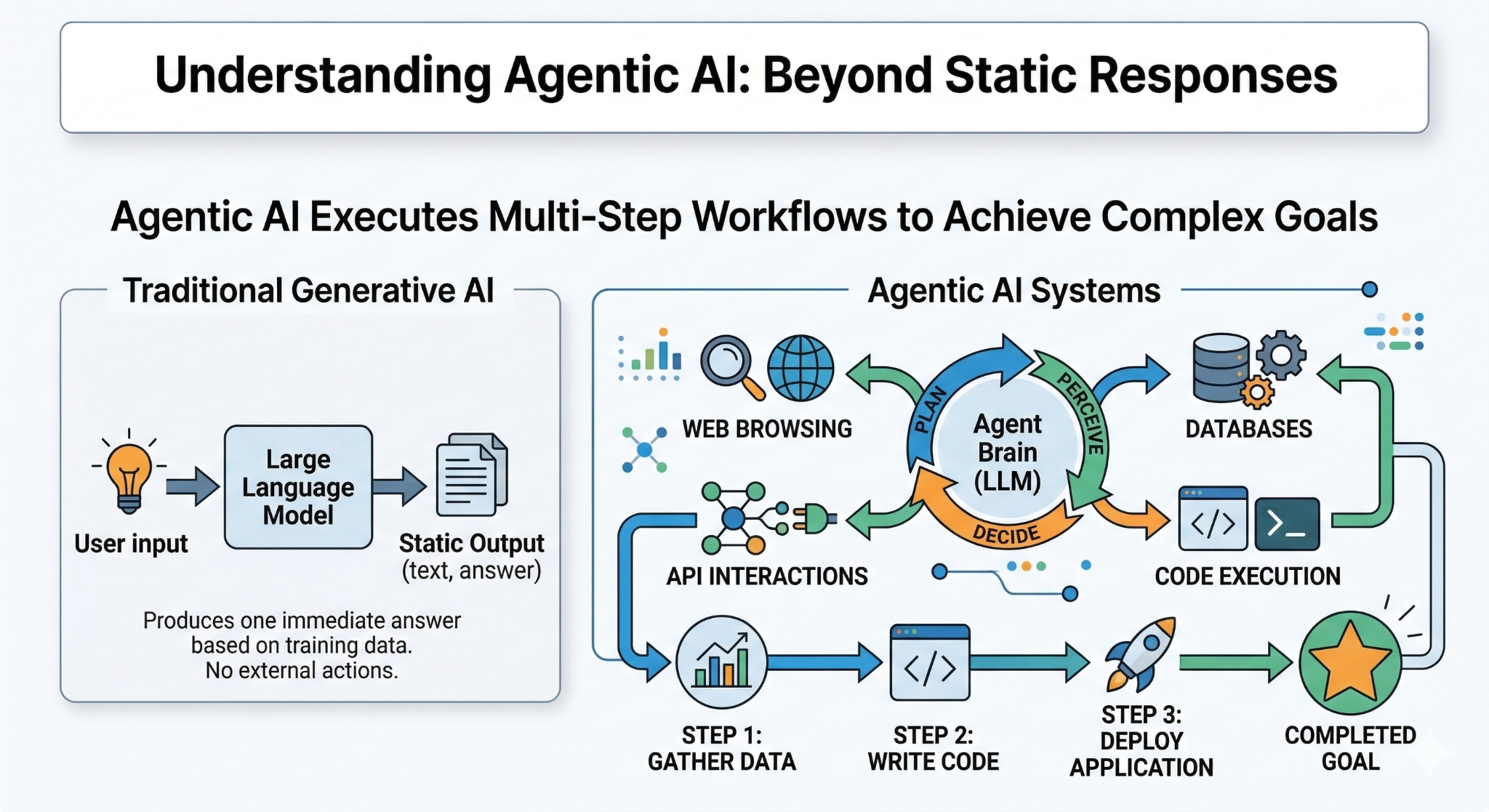
The key shift is that the model is no longer only responsible for generating text. It participates in an ongoing process that includes planning, execution, evaluation, and adaptation. Because the system acts repeatedly, mistakes can accumulate unless the agent has mechanisms to detect and correct them.
This is where self-correction becomes essential. A capable agent must not only act, but also evaluate the consequences of those actions.
Many agentic systems are built around a structured control loop that turns raw reasoning into reliable, goal-directed behavior. One of the most widely used patterns is the Observe-Plan-Act-Reflect loop.
Here’s exactly how it works in practice:
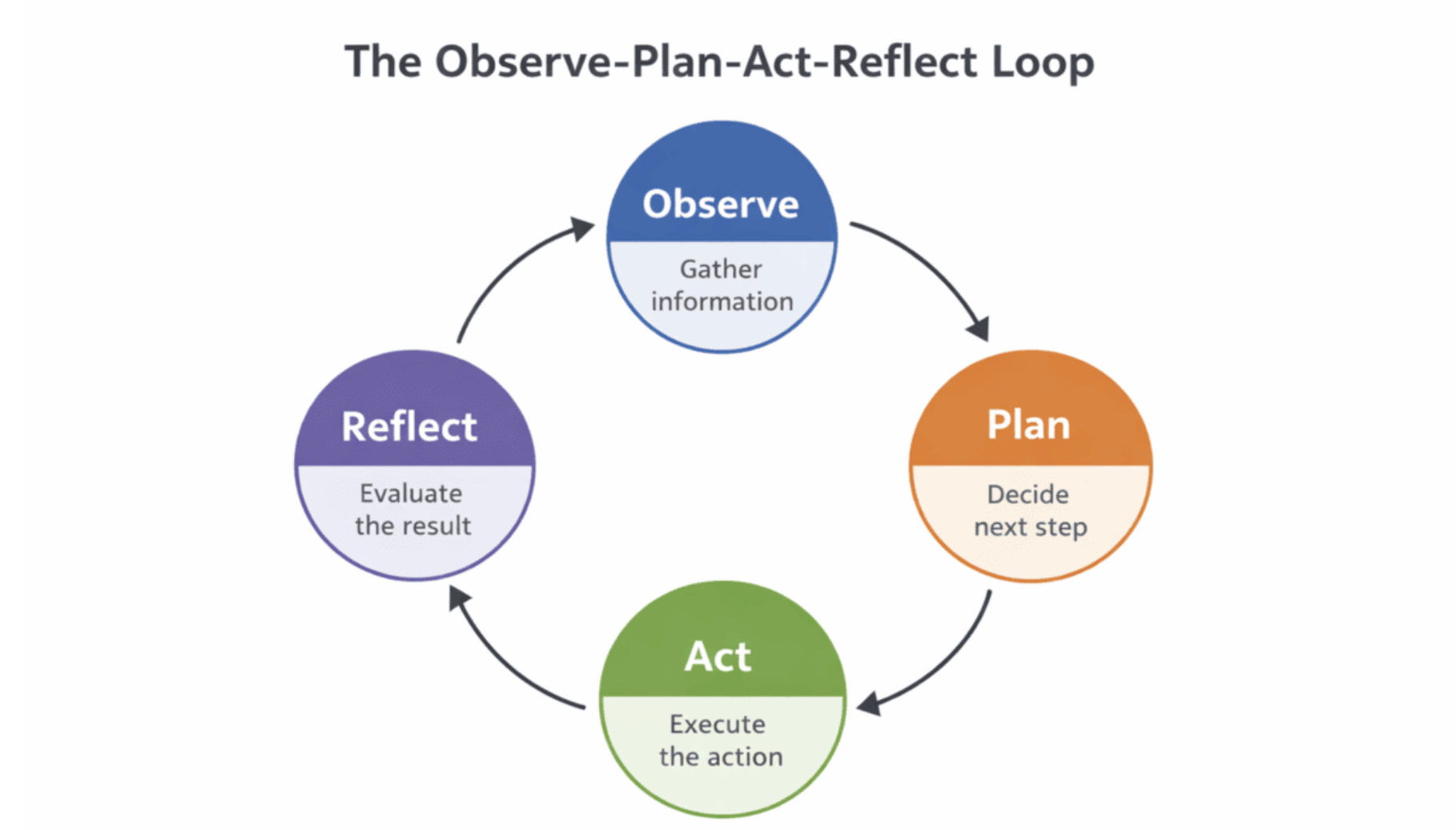 A closed-loop control cycle for agentic AI, enabling iterative decision-making, execution, and self-correction.[/caption]
A closed-loop control cycle for agentic AI, enabling iterative decision-making, execution, and self-correction.[/caption]
This loop repeats until a stopping condition is met (goal achieved, maximum steps reached, confidence threshold passed, etc.). Each full cycle lets the agent incorporate new information and refine its strategy. When the reflect stage is implemented well, it becomes the primary mechanism for self-correction, detecting errors early, avoiding repeated mistakes, and preventing error cascades that would otherwise derail the entire workflow.
In a traditional generative model, a single wrong token is annoying but harmless: the conversation simply ends. In an agentic system, that same wrong token can trigger a chain of catastrophic failures.
Because agents operate in long-running loops (Observe → Plan → Act → Reflect), every decision becomes the foundation for the next one. A small error early in the sequence compounds exponentially. One bad API call, one hallucinated fact, or one misinterpreted tool output, and the entire plan collapses.
Consider a realistic task: “Research the latest benchmarks Grok benchmarks, build a comparison table, and publish it as a live Notion page.”
The final output is confidently wrong, and the agent has no idea.
Real-world agent runs fail in exactly this way every day: malformed JSON, silent exceptions, outdated search results, or subtle hallucinations. The longer the horizon (more steps, more tools, more external state), the more fragile the system becomes.
An agentic system without self-correction is just an expensive hallucination at scale.
Production-grade agentic systems share one non-negotiable trait: they treat every action as provisional until it is verified.
This is why every serious framework in 2025–2026 bakes reflection and evaluation directly into the control loop:
Agents that lack these mechanisms remain brittle demos. Agents that include them recover from bad tool calls, catch their own hallucinations, retry intelligently, and even change strategy mid-flight.
True agency means taking responsibility for complex, multi-step goals in the real world. Responsibility without the ability to notice and fix mistakes is meaningless.
Self-correction is therefore the foundation of any system that can honestly call itself agentic.
The real power of agentic AI emerges when self-correction stops being a defensive patch and becomes an engine of continuous, autonomous improvement. Instead of simply avoiding failure, well-designed agents actually get smarter with every cycle. Here are the three core mechanics that make this possible.
Self-correction begins with tight, rapid feedback. After every action, the agent immediately evaluates its own output against the original goal, success criteria, or a set of verifiable metrics.
This is far more than “did it work?”, Modern implementations use structured scoring:
When the score falls below a threshold, the agent automatically triggers replanning or repair steps. Because the loop is fast and cheap, the system can iterate 5–20 times on a single sub-task without human intervention. The result is not just error recovery, it is measurable, progressive improvement in output quality over successive attempts.
One-shot reflection is useful, but true autonomy requires persistent memory of failure.
Modern agent architectures maintain two memory layers:
Every failed or low-scoring execution is stored with:
When the agent encounters a similar situation later, it retrieves the most relevant failure cases and proactively avoids repeating the same mistake. This turns every past error into institutional knowledge. Over time, the agent develops “learned instincts”; it becomes systematically better at the specific domain or workflow it repeatedly tackles.
In multi-agent setups (LangGraph teams, CrewAI, AutoGen, MetaGPT-style hierarchies), different agents play distinct roles:
These digital colleagues argue, critique, and cross-verify each other’s work exactly like a high-performing human team. A mistake that slips past one agent can be caught by another. The collective intelligence dramatically reduces blind spots and produces outputs that no single agent could achieve on its own.
Together, these three mechanics: rapid iterative feedback, persistent failure memory, and collaborative multi-agent critique, transform self-correction from a safety net into a genuine learning system. The agent doesn’t just fix mistakes; it evolves.
Transitioning from theory to architecture requires defining the components that enable self-correction. Relying on a single prompt will consistently fail to build a reliable autonomous loop. We require a system composed of distinct roles and layers that work together to generate, test, and refine outputs.
Building a system that fixes its own mistakes requires breaking down the monolithic large language model approach into specialized components. Each part of the architecture has a specific job, preventing the system from getting stuck in hallucination loops or losing track of the original goal. We will look at four core pillars: the actor, the validator, the memory layer, and the tooling layer. Tracking the interactions between these components is critical, and developers often rely on platforms like Weights & Biases or specific tools like W&B Traces to monitor the agentic loop.
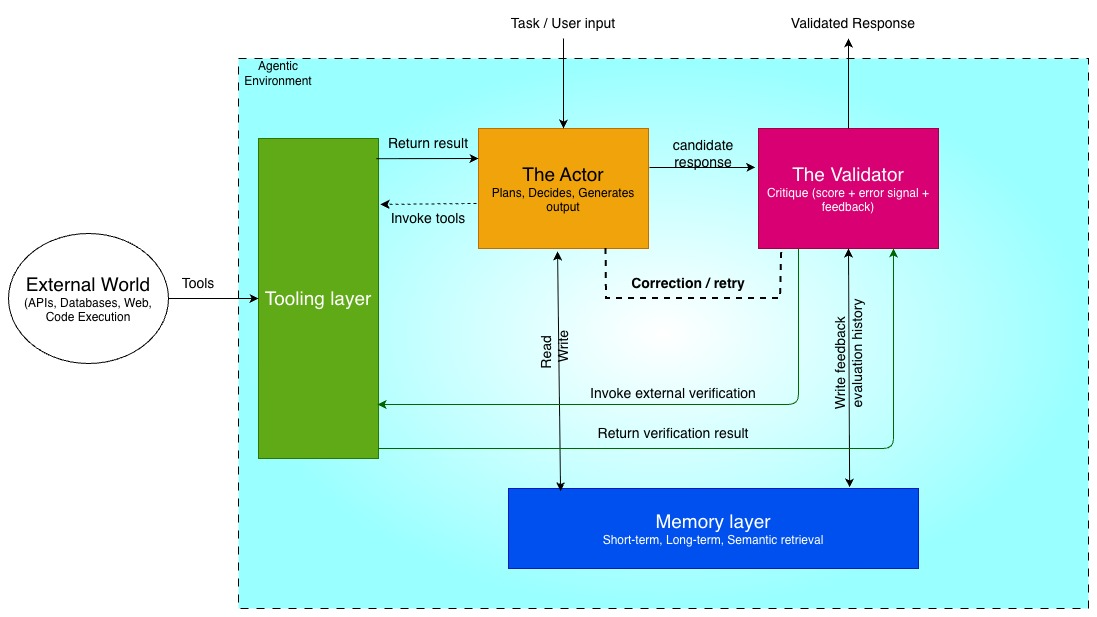
The actor is the primary worker in the system. This is the model responsible for generating the initial solution to a given prompt. It acts as the creative force, whether that involves writing a block of Python code, drafting a customer support response, or querying a database. The actor operates based on the initial instructions and any context provided by the memory layer.
Primary role: Generating the first draft or executing the initial action based on the user prompt.
Key characteristic: Optimized for generation and task execution.
The validator acts as the critic. Once the actor produces an output, the validator takes over to rigorously test that solution against external signals, ground truth, or predefined constraints. Having a separate model or a highly constrained, prompted persona for this step is crucial because a model reviewing its own work is often prone to confirmation bias. The validator scores the output, identifies specific errors, and passes this feedback back to the actor for the next iteration.
Primary role: Testing, critiquing, and validating the actor’s output to catch errors before final execution.
Key characteristic: Optimized for logic, rule-following, and strict evaluation.
Without memory, an agent is completely static. The memory layer allows the system to learn from past failures and avoid repeating the exact same error on the second attempt. This layer stores the history of the current interaction, including the original prompt, the actor’s previous attempts, and the validator’s feedback. Short-term memory keeps the current loop on track, while long-term memory can improve the system’s baseline performance over time.
Primary role: Retaining context and feedback history to ensure the system progresses toward a solution.
Key characteristic: Maintains the conversation state and the iteration count.
For the actor to act and the validator to validate, they need access to the outside world. The tooling layer provides the system with interfaces to external utilities. This might include a secure code sandbox for testing scripts, a web browser for verifying facts, or a retrieval-augmented generation pipeline to pull proprietary data. Tools give the AI system the grounding it needs to evaluate its own work objectively. Workflows using W&B Evaluations can also be integrated here to systematically benchmark the outcomes.
Primary role: Providing access to external environments, APIs, and databases for executing code and verifying information.
Key characteristic: Bridges the gap between the language model and verifiable reality.
These four layers together form the foundation of a self-correcting agentic system. The actor proposes, the validator assesses, the memory layer retains lessons, and the tooling layer grounds everything in real capabilities. When wired into the observe-plan-act-reflect loop described earlier, the system can detect its own errors, generate targeted corrections, and steadily improve the quality of its outputs without constant human intervention. The next part of this guide walks through implementing and connecting these layers in code.
Self-correction is not a universal fix. It works well when the problem is bounded, the success criteria are explicit, and the feedback signal is reliable. Outside those conditions, autonomous correction loses its ability to distinguish a genuine improvement from a confident wrong answer. The four failure classes below represent the boundaries that system designers need to plan around rather than assume away.
When the actor (generator) and the validator (critic) are the same model, or when two models were trained on nearly identical data, the validator tends to approve what the actor produces. The validator is not independently evaluating the output; it is pattern-matching against the same biases and blind spots that caused the actor to generate it in the first place.
This is the most underestimated failure mode in multi-model pipelines. The agreement looks like validation. In practice, it is a correlated failure: both models reach the same wrong conclusion through the same reasoning path. The loop completes, the system reports success, and the output is confidently wrong.
Here is how the failure typically unfolds:
┌─────────────────────┐
│ Actor (Generator) │
│ Produces output O │
└───────── ┬──────────┘
│
▼
┌─────────────────────┐
│ Validator (Critic) │
│ Same model/family │ → Shared training data & biases
│ Approves O (Yes-Man)│ → Correlated failure
└───────── ┬──────────┘
│
▼
┌─────────────────────┐
│ Loop Closes: │
│ "Success" Reported │
│ Output: Confidently │
│ Wrong │
└─────────────────────┘
Structural fix:
To prevent this, system designers must introduce genuine independence into the critic role. This can be achieved by:
When LLM-based critique is unavoidable, the validator prompt should include specific, measurable rubric items (e.g., “Verify every claim is traceable to a source document and no original instruction has been omitted”) instead of vague instructions like “Is this response good?”
Long pipelines amplify small mistakes. A single error early in the process gets written into the shared state, passed forward, and affects every subsequent step. By the time a validator detects the problem, the error has already spread across the entire system.
In a 10-step pipeline with 95% success at each step, the overall success probability drops to roughly 60%. Step-level retries can handle isolated failures, but they cannot correct errors already embedded in shared state.
Here’s how cascading errors unfold:
┌───────────────────┐
│ Step 1 (OK) │
└────────┬──────────┘
│
▼
┌───────────────────┐
│ Step 2 (OK) │
└────────┬──────────┘
│
▼
Error occurs here → ┌───────────────────┐
│ Step 3 (Error) │
└────────┬──────────────────┘
│ Error injected into shared state
▼
┌───────────────────┐
│ Step 4 → Step 12 │ ← Error propagated & amplified
└────────┬──────────┘
│
▼
┌─────────────────────┐
│ Validator (late) │ ← Detects failure too late
└─────────────────────┘
A more reliable approach is to treat the state as the central concern. Add checkpointing after each action, keep an immutable log of raw outputs, and support backward tracing of failures. When a late validator flags an issue, the system should identify the root cause before retrying. In severe cases, rolling back to a clean checkpoint is more efficient than attempting forward repair.
Key Insight: Early errors do not stay local. They compound across the pipeline, making late-stage validation insufficient. Effective systems must prioritize state management, auditability, and rollback mechanisms over simple retry logic.
Agentic systems work reliably when success criteria are explicit and verifiable. In ambiguous or open-ended tasks, the validation mechanism becomes unreliable. This creates silent failures where the system confidently approves incorrect outputs. The core challenge is not generation. It is the inability to consistently detect errors beyond the autonomy safety boundary.
Here’s a clear visual representation of the concept:
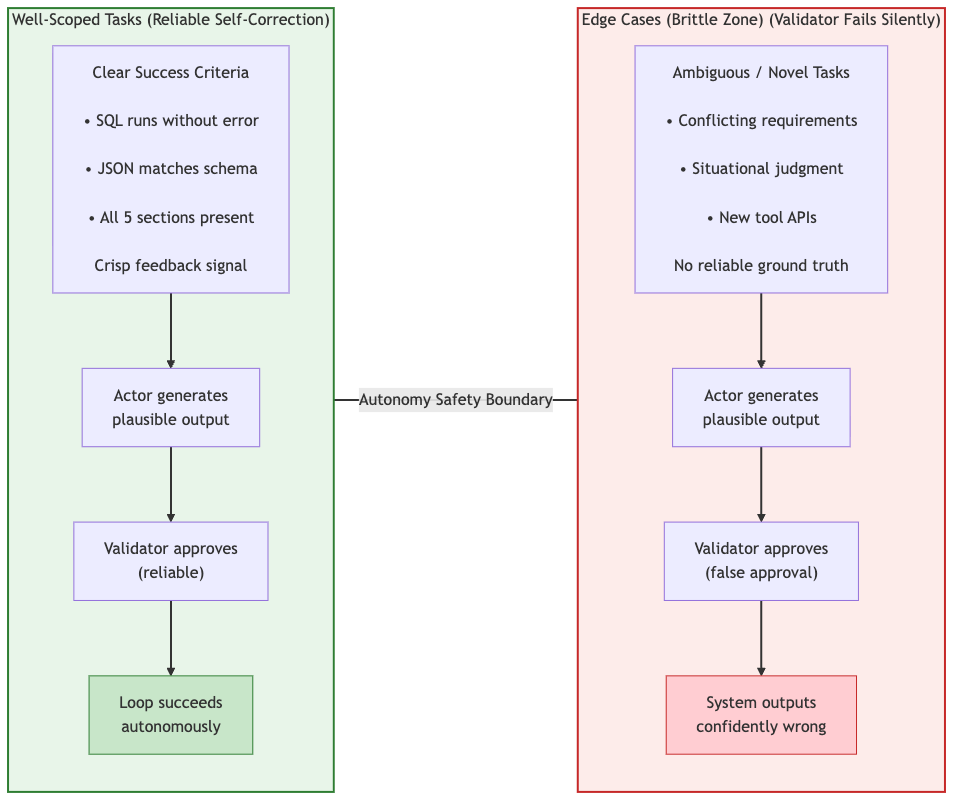
Core problem shown: in the brittle edge zone, the self-correction loop fails because the validator lacks a reliable reference for what is correct.
Recommended approach:
Limit autonomous operation to well-scoped, verifiable tasks.
A self-correcting agent that cannot solve a problem will keep retrying unless explicitly stopped. Without limits, the loop continues until the context window fills, the token budget is exhausted, or costs reach a ceiling. This often results in silent failure or a partial result with no explanation.
Here’s how the failure typically unfolds:
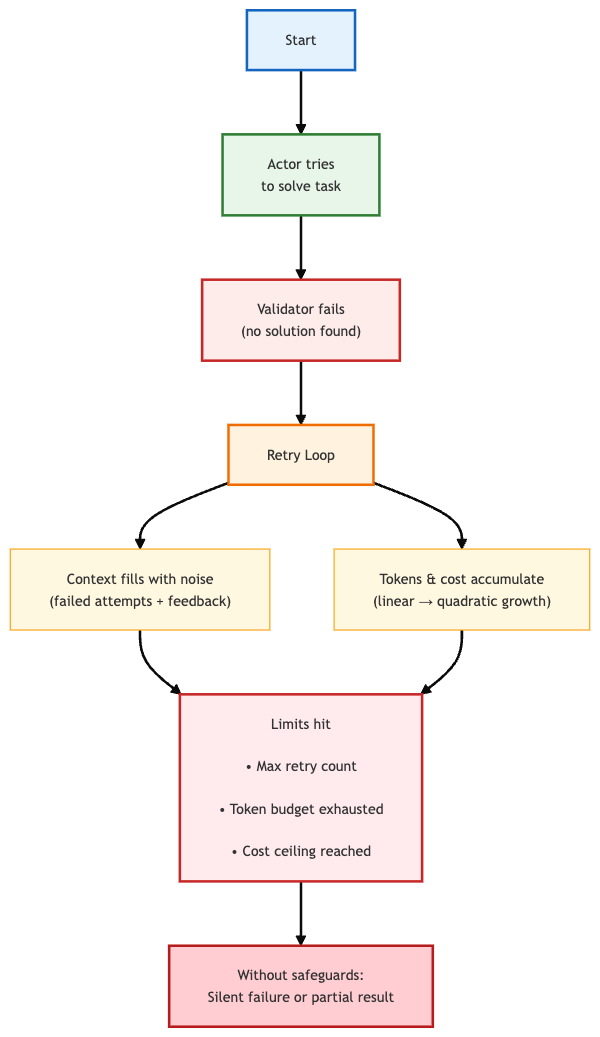
Design requirement: This failure mode is predictable and should be handled as a core design constraint. Every loop should enforce:
Fallback behavior: the system should return the best attempt produced so far, along with a clear diagnostic that explains how far the loop progressed and why it stopped.
Context degradation: as retries increase, the context window becomes filled with failed attempts and validator feedback. Later retries often perform worse because attention is spent on irrelevant information.
Mitigation strategy: summarize past attempts before each retry, rather than appending the full history. This helps preserve useful context and keeps the agent focused on correction.
System design: these constraints are more reliable when enforced by an external orchestrator rather than the agent itself. An orchestrator can monitor token usage, enforce budgets, and trigger escalation without relying on the agent to manage its own resources.
The architecture, implementation patterns, and failure modes covered so far reflect the current state of self-correcting agentic systems. The field is evolving quickly, and two developments are shaping how production-grade agents will operate in the near future.
The first is a protocol that standardizes how agents communicate with tools and with each other. The second is the governance infrastructure required to deploy autonomous systems responsibly at scale.
Understanding both is essential for building agents that remain reliable as system complexity increases.
The next frontier for self-correcting agents is not only smarter reflection loops. It is interoperability. Most agentic systems operate in isolation. An agent built on one framework cannot directly communicate with tools or agents built on another, and integrations often rely on custom connectors and fragile glue code that breaks when APIs change.
The Model Context Protocol is an emerging standard designed to address this. It defines a universal communication layer that allows any AI agent to connect to tools, data sources, or external services through a consistent interface. It can be thought of as a common connection standard that works regardless of what exists on either end.
For self-correcting systems, this changes what is possible in three ways:
As the ecosystem evolves, self-correcting agents built on compliant architectures will gain access to a growing library of verified and reusable tools and agent capabilities. This reduces engineering overhead and makes it easier to build reliable agentic pipelines.
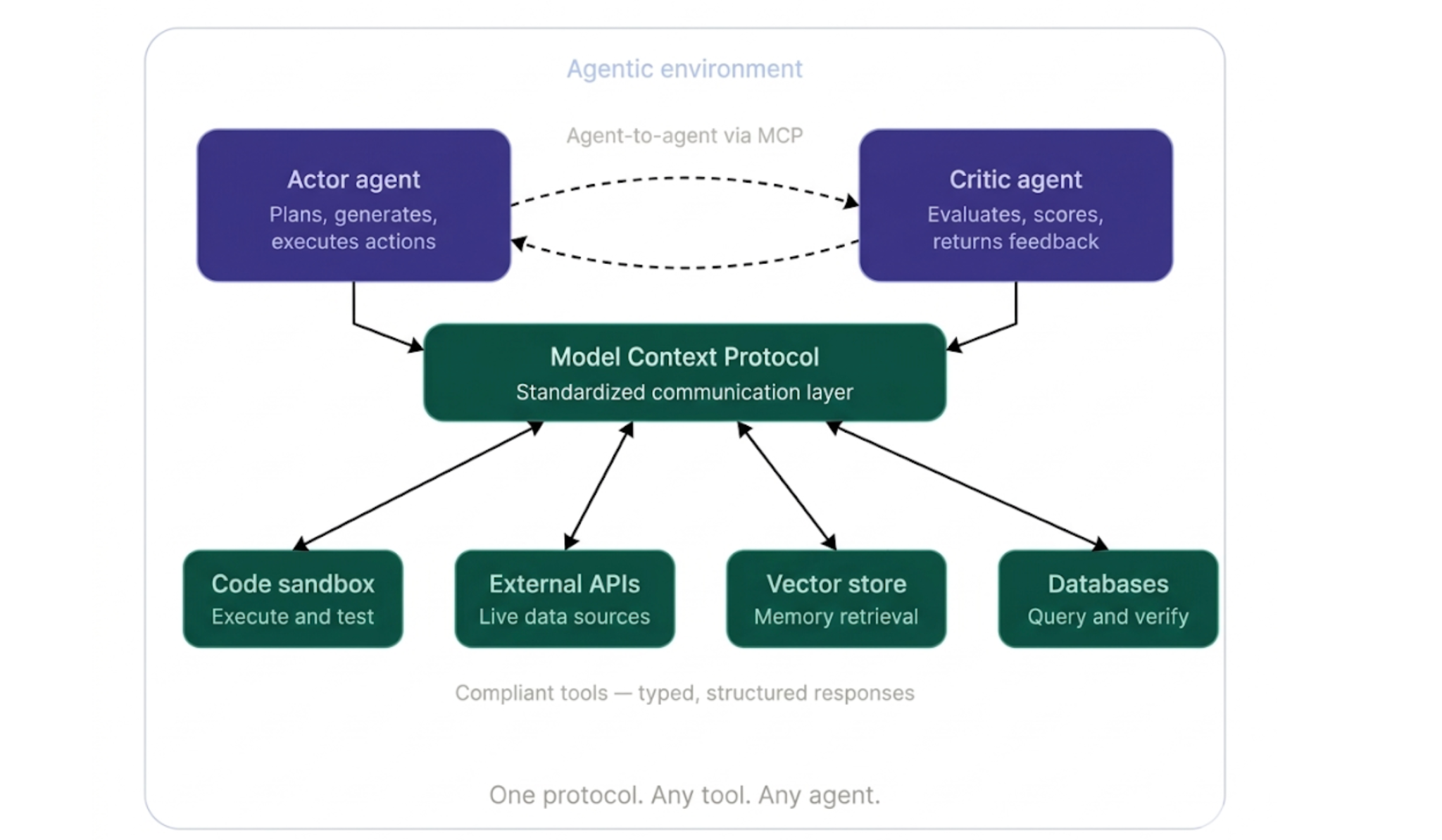
Self-correction makes agents more capable. Governance is what makes them trustworthy enough to deploy at scale.
As agentic systems move into production, the question shifts from whether the system can fix its own mistakes to who is accountable when it cannot. The correction loop handles recoverable errors. Governance addresses everything beyond that, including irreversible actions, ethical boundaries, and failures that escalate faster than automated systems can detect.
Several principles are becoming foundational:
Regulatory pressure is also accelerating this shift. The EU AI Act classifies certain agentic applications as high-risk systems that require conformity assessments and human oversight mechanisms. This turns logging, auditability, and escalation paths into legal requirements rather than optional best practices.
The practical takeaway is straightforward. Design governance before building the actor, because adding it later to a deployed system is significantly more difficult.