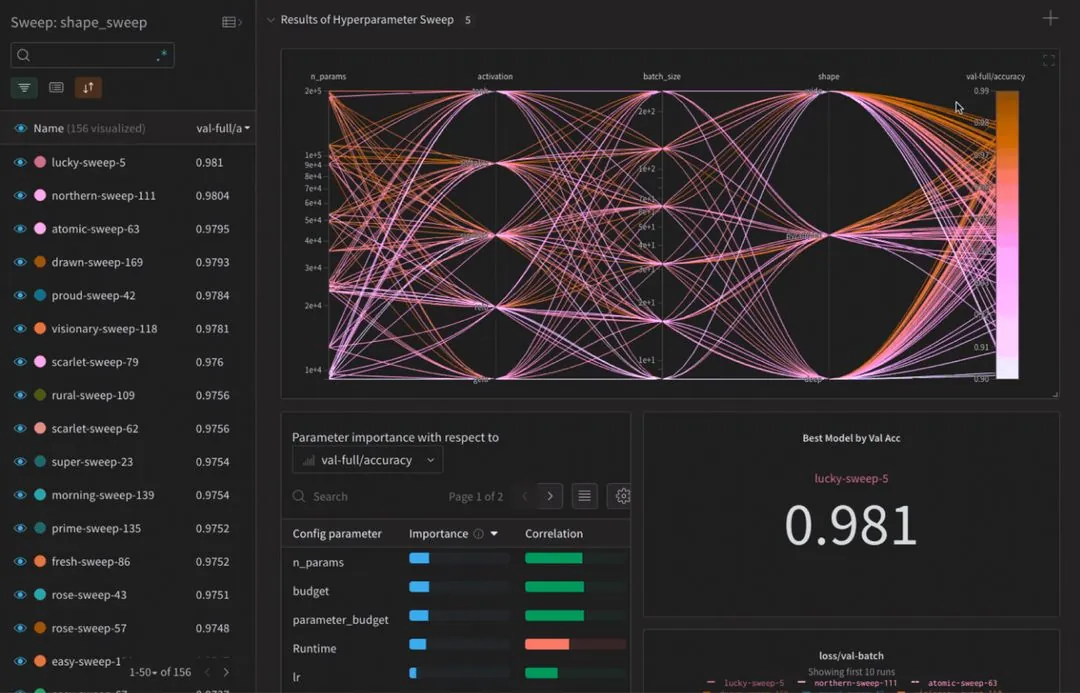
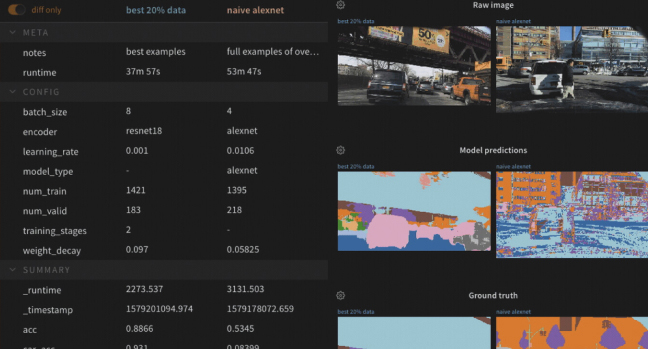
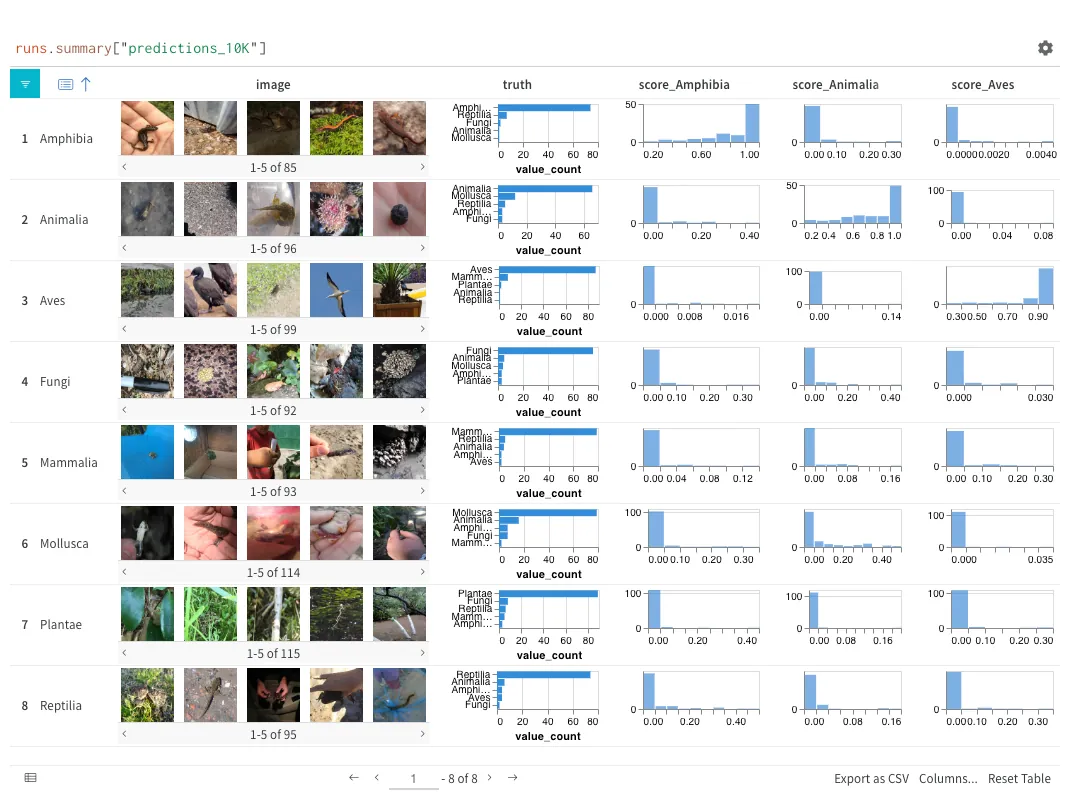
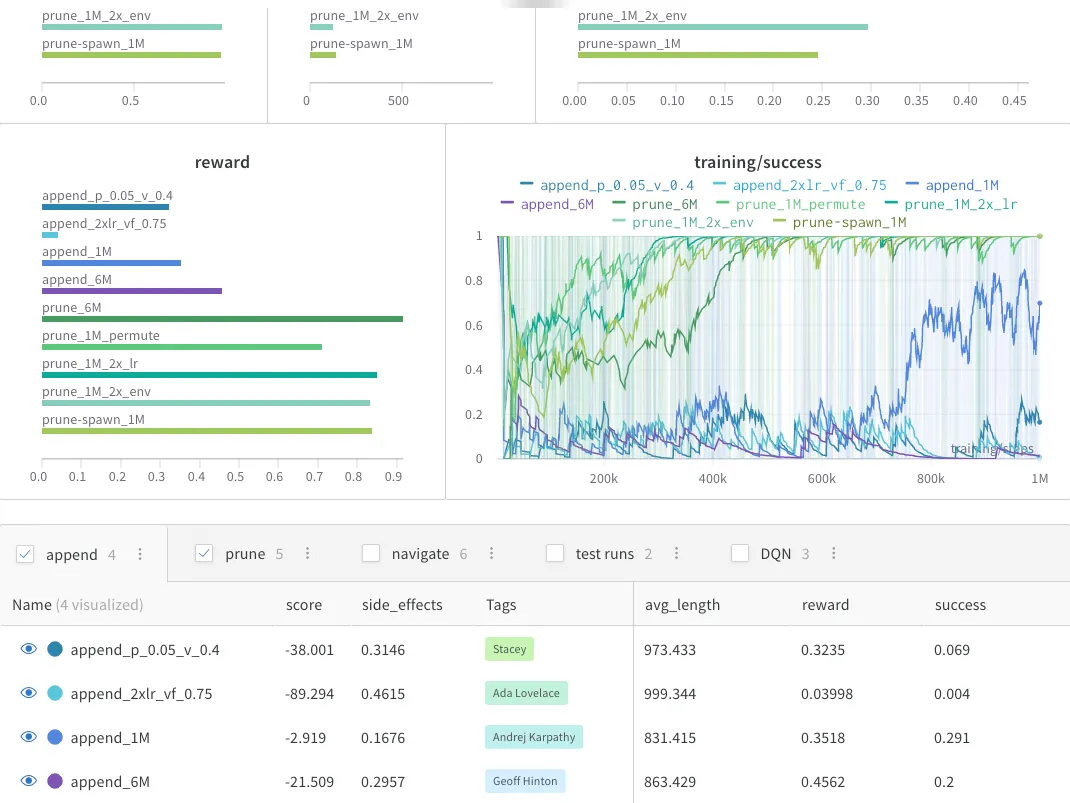
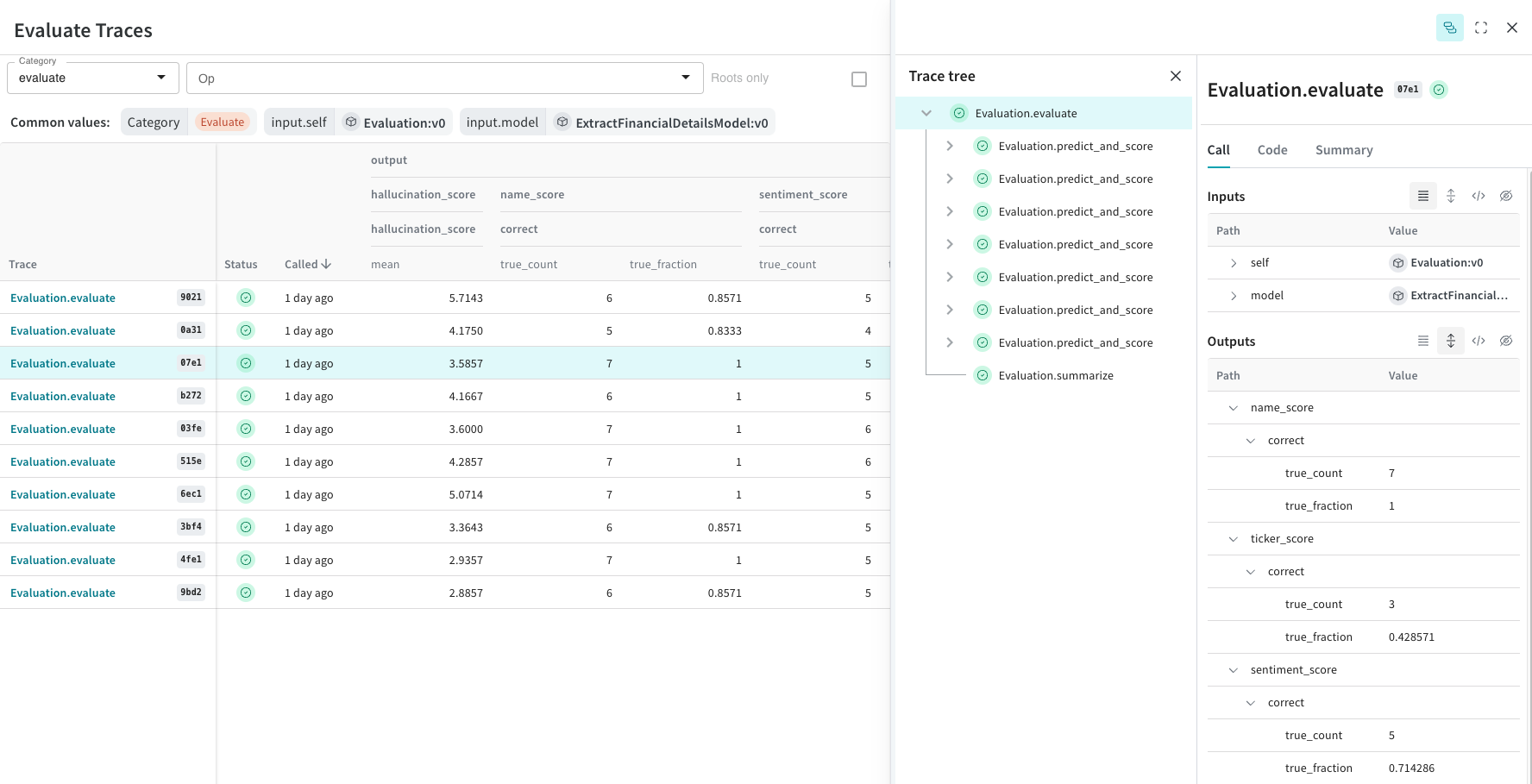
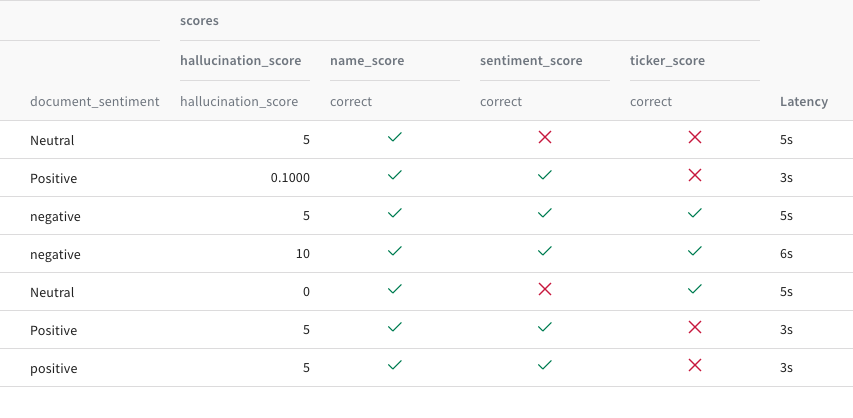
import wandb
wandb.init(project="visualize-sklearn")
# Model training here
# Log classifier visualizations
wandb.sklearn.plot_classifier(clf, X_train, X_test, y_train, y_test, y_pred, y_probas, labels,
model_name="SVC", feature_names=None)
# Log regression visualizations
wandb.sklearn.plot_regressor(reg, X_train, X_test, y_train, y_test, model_name="Ridge")
# Log clustering visualizations
wandb.sklearn.plot_clusterer(kmeans, X_train, cluster_labels, labels=None, model_name="KMeans")